
Écrire un pipeline d'imagerie satellite, deux fois : un véritable succès
Par : Blair Drummond, Statistique Canada
Statistique Canada modernise la collecte des données agricoles à l'aide d'images satellitaires pour prédire la croissance des cultures. Les scientifiques des données de Statistique Canada ont été confrontés à plusieurs défis tout au long du projet, incluant l'apparence de coûts hors de prix une fois les exigences du passage à la production prises en considération, et ce, malgré des résultats initiaux prometteurs. Ils ont toutefois relevé le défi en tenant compte de toutes les options, y compris les moins évidentes, et ils ont constaté directement tout le bienfait d'avoir une équipe diversifiée au niveau des compétences.
Une équipe de scientifiques de données de Statistique Canada a uni ses efforts à ceux des experts du programme de l'agriculture de l'agence pour créer une preuve de concept de l'apprentissage automatique qui a été couronnée de succès. Ils ont implanté un réseau neuronal qui a réussi à prédire avec une exactitude de 95 % quelle culture poussait dans un quart de section (terrain de 160 acres), en utilisant l'imagerie satellite accessible gratuitement. C'était une belle opportunité pour le programme d'agriculture de StatCan, car l'imagerie satellite offre une façon d'obtenir des estimations de mi-saison, ou même des estimations en temps quasi réel, et la nouvelle approche contribue à réduire le fardeau de réponse pour les exploitants agricoles qui devaient répondre aux enquêtes régulièrement.
Il n'y avait cependant qu'un problème. L'implantation produite par la preuve de concept comportait une étape de prétraitement dans laquelle il fallait extraire des données sous forme de pixels des images satellites de Landsat8 et appliquer certaines transformations. Pour une seule image, ce processus, mené au moyen d'un ordinateur de bureau de base en mode virtuel infonuagique, prenait environ une journée complète, utilisait plus de 100 gigaoctets de mémoire vive et coûtait environ 50 $ par image. L'ensemble des données d'entraînement comportait des données pour sept années et trois provinces, ou environ 1 600 images au total. Si tout fonctionnait la première fois en utilisant l'infrastructure de nuage public, le projet coûterait 80 000 $, avant même d'arriver à l'étape de l'entraînement du modèle.
Ce coût aurait été trop élevé pour ce projet qui en était encore à l'étape d'expérimentation. On ne savait pas avec certitude si le modèle fonctionnerait bien à une échelle plus grande que cette expérimentation, et le coût pour mettre au point un nouveau modèle avait cet obstacle de taille devant lui. Les scientifiques des données étaient assez convaincus de trouver un modèle qui fonctionnerait, mais ils devaient le rendre plus économique. En parallèle, ils se sont tournés vers une petite preuve de concept pour voir s'ils étaient en mesure de contourner cet obstacle et rendre les étapes de prétraitement économiquement viables.
La preuve de concept : les trois premiers pipelines
Lorsque les scientifiques des données ont commencé l'expérimentation de pipeline dans le cadre de ce projet à l'automne 2019, le nuage était encore relativement nouveau pour eux, l'Analyse des données en tant que service (ADS) était un jeune projet, et l'équipe se familiarisait avec ce qui était nouvellement accessible. La preuve de concept visait certainement à régler un problème particulier, mais elle constituait également une expérimentation à l'échelle de la division pour trouver comment naviguer dans la plateforme infonuagique. C'est pourquoi ils en ont fait un projet conjoint avec l'équipe de l'ADS et une équipe d'architectes de solutions en nuage. Le but était d'acquérir de l'expérience avec différentes technologies, y compris :
Les solutions d'apprentissage automatique Azure Batch et Azure devaient être implantées par une équipe possédant l'expertise pertinente, en étroite collaboration avec la Division de la science des données (DScD). Celle-ci a également travaillé avec l'équipe de l'ADS pour voir ce que la plateforme de l'ADS était en mesure d'offrir. Les équipes ont toutes reçu le même ensemble de code et quelques images d'essai et pendant quatre mois, elles ont travaillé à l'implantation de leurs solutions.
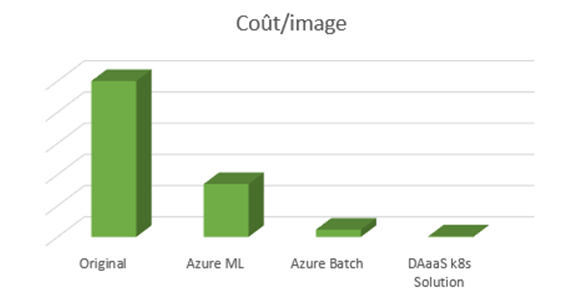
À la fin de la période d'implantation, chacune des approches a été analysée pour produire des estimations de coûts pour le traitement d'une seule image (Figure 1).
Les pipelines ont fonctionné avec différents types de machines virtuelles choisis par l'architecte. Les solutions Azure ont utilisé des instances de faible priorité et la tarification de la solution Kubernetes est fondée sur une tarification réservée pour trois ans (ce qui est plus onéreux qu'une faible priorité). La vraie question était la suivante : pourquoi des différences de coût aussi énormes?
Comparer des pommes avec des oranges
La différence était le code. Alors que chaque équipe a reçu le même code au début avec l'objectif de le paralléliser, les solutions d'apprentissage automatique Azure et Azure Batch ont favorisé des approches légèrement différentes à l'égard de cette parallélisation. Les légers changements apportés au code ont donné lieu à des différences de résultat significatives. Les différences ne se situaient pas vraiment au niveau de la technologie du pipeline en soi; toutes choses étant égales, le rendement aurait été comparable, mais une des implantations a contourné un grave problème de rendement tandis qu'une autre n'a pas touché à cette partie du code.
Par exemple, un des problèmes de l'implantation initiale était sa manière de paralléliser le traitement d'une image. Dans sa forme originale, elle a séparé ce qui devait être extrait de l'image en 30 groupes et a ensuite créé 30 processus parallèles, chacun traitant une partie de l'image. À première vue, il s'agissait d'une excellente idée, mais malheureusement, il y avait une complexité. L'algorithme d'extraction requis pour charger un fichier de données géographiques volumineux dans la mémoire et l'image elle-même représentaient ensemble environ 3 Go de mémoire vive. Ce serait possible pour un processus, mais puisque les processus ne partagent pas la mémoire, faire cela pour 30 processus en parallèle gonflait l'utilisation de la mémoire vive à 90 Go. De plus, tous les processus écrivaient de nombreux petits fichiers sur le disque dans le processus d'extraction, et les écritures de disque en parallèle ralentissaient grandement le programme. Cette première implantation a utilisé un grand nombre de ressources et pris plus de temps que prévu, parce qu'elle n'en finissait plus d'écrire des données sur le disque.
C'était là un endroit où l'apprentissage automatique Azure et Azure Batch ont divergé. La solution Azure Batch a facilité la tâche de paralléliser au niveau de ces groupes à l'intérieur de l'image à extraire, et ces processus ont donc été séparés parmi différentes machines. La mémoire vive était beaucoup plus facile à gérer et les processus ne se faisaient pas concurrence lors de l'écriture sur le disque. Cette tâche était moins naturelle à exécuter dans l'apprentissage automatique Azure et, sans que ce soit de sa faute, il a semblé beaucoup moins performant.
En revanche, pour l'implantation de la solution ADS et Kubernetes, les scientifiques des données ont pris grand soin de lire les composants, de les réécrire et de les restructurer et, avant même de toucher au pipeline, ils avaient un processus d'extraction :
- qui utilisait 6 Go de mémoire vive par image, et non 100 Go;
- qui s'exécutait en moins de 40 minutes, et non en plusieurs heures;
- qui utilisait 6 unités centrales de traitement, et non 30 et plus.

Description de la figure 2 - L'utilisation du processeur
Traitement de trois lots de 15 images chacun, pour un total de 45 images. Chaque couleur représente une image extraite et l'utilisation des unités centrales de traitement au fil du temps.

Description de la figure 3 - L'utilisation de la RAM
Traitement de trois lots de 15 images chacun, pour un total de 45 images. Chaque couleur représente une image extraite et l'utilisation de la mémoire avec le temps.
Avant même de se rendre à l'optimisation du pipeline, le problème a été réduit d'un problème nécessitant de vastes clusters d'ordinateurs à un qui pourrait être exécuté sur un ordinateur portatif de milieu de gamme. Comme le pipeline n'avait plus la contrainte de rendre le traitement d'une image économique, il a été possible de passer à l'étape de rendre le traitement d'images pour une saison au complet à la fois simple, gérable et automatisé.
Comment savons-nous cela maintenant? Pourquoi cela n'a-t-il pas été remarqué?
L'équipe qui a travaillé sur les solutions d'apprentissage automatique Azure Batch et Azure ne profitait pas d'un mandat qui comprenait la restructuration du code. Ils n'étaient expressément pas censés modifier le code, car cela aurait pu avoir des répercussions sur la méthodologie et cela a peu à voir avec les solutions infonuagiques ou avec les preuves de technologie. Cela ne faisait tout simplement pas partie de leurs tâches.
En revanche, l'équipe de la DScD venait à peine d'embaucher quelqu'un pour investir précisément dans leur capacité d'ingénierie des données, alors en plus de travailler à une preuve de technologie avec l'ADS, l'équipe déployait aussi des efforts pour acquérir plus d'expertise dans ce domaine. L'ingénieur en données a examiné le code en profondeur et a eu la chance d'avoir près de lui l'auteur même du code pour répondre à ses questions. Ils avaient tout simplement plus de liberté pour régler le problème de diverses manières en disposant des ressources à l'interne, ce qui a donné des résultats plus efficaces ainsi que de nouvelles perspectives.
Il est important de noter que sans cette analyse et cet examen du code, non seulement n'auraient-ils pas eu cette nouvelle solution, mais ils n'auraient pas su non plus pourquoi les deux solutions Azure présentaient de telles différences de rendement! Ce n'est qu'après la revue qu'il a été possible de déterminer clairement la cause des différences entre les trois solutions.
Leçons apprises
L'équipe n'a pas comparé des pommes avec des pommes dans cette situation, et par conséquent, cela a été une expérience beaucoup plus instructive. Ce qu'ils ont comparé sans le vouloir était réellement
- qu'arrive-t-il lorsque vous tentez un portage virtuel (lift-and-shift) d'une application existante?
et
- que pouvez-vous tirer de l'analyse d'une application existante?
La première question en est une de plateforme/d'infrastructure à la base, et la deuxième est une question d'ingénierie/d'application. Ce qui a été découvert dans cette preuve de concept, c'est que bien que la plateforme soit un contexte nécessaire, sans quoi cet exercice aurait été impossible, la valeur réelle a été obtenue par l'ingénierie de baseNote de bas de page 1, et c'est le travail investi dans l'application même qui a fait la différence entre les résultats.
L'équipe a été plus sage lors de l'expérience et a appris où concentrer son expertise. Grâce à ce projet, et à des expériences similaires, ils ont été en mesure de prendre des décisions stratégiques au sein de la division quant à déterminer comment et où augmenter la capacité. Au cours de l'année écoulée depuis l'expérimentation, les efforts de la DScD pour accroître les compétences en matière d'ingénierie des données dans l'ensemble de la division ont porté fruit dans le cadre de nombreux projets.
Choisir une technologie de pipeline et ce qui a dégénéré la première fois
Dans la section précédente, il a été démontré que la technologie de pipeline sous-jacente n'était pas réellement ce qui a nui à l'efficacité ou au coût. Alors, quels sont les éléments qui ont motivé les décisions? Et quelles sont les erreurs qui ont été commises la première fois?
Comme on y a fait allusion précédemment, la valeur opérationnelle de la DScD réside dans le développement de modèles et d'applications, et non dans la fourniture ou la mise à jour de l'infrastructure. De plus, la division ne représente qu'une infime partie d'une organisation beaucoup plus vaste, et il est important que sa stratégie en matière de technologie soit toujours harmonisée avec l'organisation et qu'elle corresponde aux services horizontaux offerts par des solutions comme l'ADS.
Pour la DScD, la décision était facile. L'harmonisation et le travail avec l'ADS facilite le travail de la DScD, leur permettant de se concentrer sur les choses qui apportent une valeur opérationnelle aux clients, et le travail avec la plateforme d'ADS aide l'équipe d'ADS à construire une plateforme robuste et souple qui répond aux besoins des clients — pour la DScD, pour Statistique Canada, pour les partenaires externes et en définitive, pour les Canadiens.
Choisir la solution ADS et Kubernetes était évident à la fin. Ils ont implanté un pipeline entièrement automatisé qui interagissait avec l'interface de programmation d'applications de la Geological Survey des États-Unis pour obtenir les images, les téléchargeait et les traitait, tout cela de manière automatique, contrôlée à l'aide de versions et mue par des artefacts. L'équipe a obtenu des résultats couronnés de succès et l'équipe ainsi que les clients étaient très heureux de cette solution.
Malheureusement, le pipeline s'exécutait à l'aide d'un logiciel particulier, et environ un mois plus tard, ce logiciel est passé à un nouveau modèle de licence, ce qui a entraîné une remise en question de son utilisation. Il a été déterminé que l'utilisation continue du logiciel était impossible (et que l'achat du logiciel n'était pas une option viable).
Par conséquent, la réécriture était inévitable d'une manière ou d'une autre.
La réécriture et l'avantage de l'analyse a posteriori
À bien des égards, la réécriture a donné à l'équipe la chance de revoir et de simplifier l'implantation initiale. Le premier pipeline comportait de nombreux composants qui remplissaient chacun une fonction, et le code du pipeline s'employait ensuite à les orchestrer.

Description de la figure 4 - Le pipeline d'origine
Répartition de chaque composant dans le pipeline d'origine et façon dont ils interagissent l'un avec l'autre.
Un organigramme avec les cases suivantes étiquetées : Fichiers de Trackframe > Tables de Trackframe > Sections Quartier > Processus AA, Minuteur journalier > Événement > Images, IPA de Landsat.
Dans le pipeline révisé, en utilisant les pipelines Kubeflow, la complexité est passée de l'orchestration du pipeline au code de l'application même.
Bien que cela semble contraire au sens commun, la réalité est que le pipeline n'est pas plus ou moins compliqué, que la logique soit encodée dans les « composants » du pipeline, ou dans le tissu qui les rassemble. La différence, c'est que plus de personnes connaissent le langage Python ou R habituel que le code d'orchestration du pipeline. Il est donc plus simple et plus facile à gérer (pour des projets comme celui-ci) de ne pas trop insister sur le code de pipeline. Par conséquent, du côté des pipelines Kubeflow, le pipeline ressemble à ce qui suit :

Description de la figure 5 - Le pipeline Kubeflow
Le pipeline mis à jour combine de nombreux composants d'origine en un seul processus pour déterminer les images d'intérêt, puis Kubeflow crée des processus parallèles pour traiter chacune d'entre elles.
Le pipeline Kubeflow: Un cercle étiqueté « Obtenir le nom de l'image » pointe vers sept boîtes étiquetées « Extraction SQ ».
Il obtient simplement la liste des images à traiter cette journée-là, s'exécute en parallèle dans le cluster Kubernetes et extrait chaque image séparément. Le composant est encapsulé dans une image Docker, qui lui permet de demeurer transférable et facilite les essais et le déploiement. Le code d'orchestration du pipeline est d'environ 20 lignes de Python.
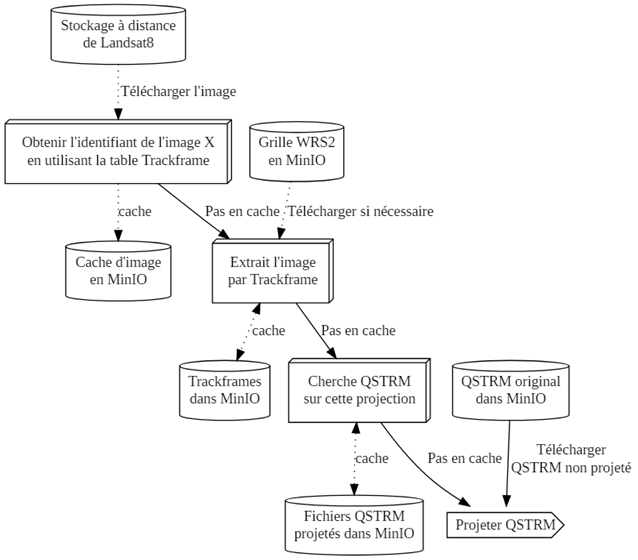
Description de la figure 6 - Le pipeline
Un organigramme avec les cases suivantes étiquetées : Stockage à distance de Landsat 8 > Télécharger l'image > Obtenir l'identifiant de l'image X en utilisant la table Trackframe > Cache > Cache d'image en MinIO
Grille WRS2 en MinIO > Pas en cache télécharger si nécessaire > Extrait l'image par Trackframe > cache > Trackframes dans MinIO
Pas en cache > Chercher QSTRM sur cette projection > cache > Fichiers QSTRM projetés dans MinIO
QSTRM original dans MinIO > Pas en cache / télécharger QSTRM non projeté > Projeter QSTRM
La circulation des données à l'intérieur de l'extracteur est encore un peu compliquée, mais elle est gérée facilement et efficacement à l'aide d'un compartiment S3 (implanté par MinIO) en tant que lieu de stockage et mémoire cache.
L'équipe était heureuse du résultat et a réussi à traiter 1 600 images sans problème.
La fin?
En fait, ce n'est pas réellement la fin de l'histoire, car le dernier chapitre n'a pas encore été écrit. Avec le nouveau pipeline, le projet sera élargi et passera à la production, et l'équipe commencera bientôt l'entraînement du nouveau modèle.
Nous avons hâte de vous faire part de notre avancement dans nos prochains articles à mesure que le projet ira de l'avant. Qui sait, vous aurez peut-être la chance de lire à propos d'un tout nouveau réseau neuronal qui peut trouver ce qui pousse à partir de l'espace!
- Date de modification :