
MLflow Tracking : Une façon efficace de suivre les essais de modélisation
Par : Mihir Gajjar, Statistique Canada
Collaborateurs : Reginald Maltais, Allie Maclsaac, Claudia Mokbel et Jeremy Solomon, Statistique Canada
MLflow (le contenu de cette page est en anglais) est une plateforme en source ouverte qui permet de gérer le cycle de vie d'apprentissage automatique, notamment l'expérimentation, la reproductibilité, le déploiement et un registre de modèles central. MLflow propose quatre composantes :
- MLflow Tracking : enregistrement et interrogation d'essais : code, données, paramètres de configuration et résultats.
- MLflow Projects : assemblage de code de science des données en un format permettant de reproduire les passages sur n'importe quelle plateforme.
- MLflow Models : déploiement de modèles d'apprentissage automatique dans divers environnements d'utilisation.
- Model Registry : stockage, annotation, découverte et gestion de modèles au sein d'un répertoire central.
Cet article se concentre sur MLflow Tracking. Le site Web de MLflow détaille les trois autres composantes.
Avantages de MLFlow
MLflow Tracking offre une solution pouvant être adaptée de votre machine locale à l'entreprise entière. Cela permet aux scientifiques des données de commencer sur leur machine locale, alors que les organisations peuvent mettre en œuvre une solution veillant à la maintenabilité à long terme et à la transparence au sein d'un répertoire central.
MLflow Tracking fournit des capacités de suivi cohérentes et transparentes en :
- effectuant le suivi programmatique des paramètres et des résultats correspondants pour les essais de modélisation et en les comparant à l'aide d'une interface utilisateur;
- récupérant le modèle présentant les meilleurs résultats ainsi que son code correspondant, pour diverses mesures d'intérêt pour tous les essais de différents projets;
- regardant temporellement en arrière, afin de relever des essais effectués avec certaines valeurs de paramètres;
- permettant aux membres de l'équipe de procéder à des essais et de faire part des résultats en collaboration;
- exposant à l'intention de la direction l'état d'avancement de plusieurs projets au sein d'une seule interface ainsi que tous les détails (paramètres, tracé des résultats, mesures, etc.);
- permettant le suivi pour tous les passages et paramètres au moyen d'un simple carnet; ce qui réduit le temps passé à gérer du code et diverses versions de carnet;
- fournissant une interface permettant le suivi d'essais basés sur Python et R.
Comment passer d'un essai à un autre avec MLflow?
Cet article se concentre sur l'utilisation de MLflow avec Python. Le document QuickStart (le contenu de cette page est en anglais) relatif à MLflow présente des exemples de son utilisation avec R pour une installation locale sur une seule machine. Les organisations souhaitant déployer MLflow entre des équipes peuvent également se reporter à ce document QuickStart.
Le présent article explore un exemple d'utilisation de MLflow avec Python; toutefois, pour bien comprendre le fonctionnement de MLFlow, il est utile d'effectuer chaque étape sur votre machine.
Installation de MLflow
MLflow peut s'installer comme progiciel Python standard en entrant la commande suivante dans une fenêtre de terminal :
$ pip install mlflow
Une fois l'exécution de la commande terminée, vous pouvez entrer mlflow sur votre terminal et explorer les options disponibles. Vous pouvez essayer, par exemple : mlflow –version , pour vérifier la version installée.
Lancement du serveur MLflow
Il est recommandé de disposer d'un serveur MLflow centralisé pour une personne, une équipe ou une organisation, afin que les passages pour différents projets puissent être journalisés à un emplacement central, en les isolant par essai (différents essais pour différents projets). Nous discutons plus en détail de ces questions plus loin dans le présent article. Pour commencer rapidement à utiliser l'outil, vous pouvez ignorer le lancement du serveur et journaliser tout de même les passages. Ce faisant, les passages sont enregistrés dans un répertoire intitulé « MLruns », dans le même répertoire que le code. Vous pouvez plus tard ouvrir l'interface utilisateur de MLflow en suivant le même chemin d'accès et visualiser les passages journalisés.
Les passages peuvent être journalisés sur un serveur MLflow exécuté localement ou à distance en configurant l'adresse URI (identifiant uniforme de ressource) adéquate de suivi. La configuration de l'emplacement de journalisation adéquat est expliquée plus bas.
Si vous préférez toutefois lancer le serveur immédiatement, vous pouvez le faire en entrant la commande suivante :
$ mlflow server
Le terminal affichera des renseignements similaires à ceux présentés ci-dessous, qui montrent que le serveur écoute au port de serveur local 5000. Cette adresse est utile pour accéder à l'interface utilisateur (IU) de MLflow. N'hésitez pas à explorer la différence subtile entre l'IU de MLflow et le serveur de MLflow dans les documents relatifs à MLflow Tracking (le contenu de cette page est en anglais).
[2021-07-09 16:17:11 –0400] [58373] [INFO] Starting gunicorn 20.1.0
[2021-07-09 16:17:11 –0400] [58373] [INFO] Listening at: http://127.0.0.1:5000 (58373)
[2021-07-09 16:17:11 –0400] [58373] [INFO] Using worker: sync
[2021-07-09 16:17:11 –0400] [58374] [INFO] Booting worker with pid: 58374
[2021-07-09 16:17:11 –0400] [58375] [INFO] Booting worker with pid: 58375
[2021-07-09 16:17:11 –0400] [58376] [INFO] Booting worker with pid: 58376
[2021-07-09 16:17:11 –0400] [58377] [INFO] Booting worker with pid: 58377
Journalisation des données dans MLflow
Deux principaux concepts sous-tendent le suivi avec MLflow : les essais et les passages. Les données journalisées au cours d'un essai sont enregistrées sous forme de passage dans MLflow. Ces passages peuvent être organisés en essai; ce qui regroupe les passages pour une tâche particulière. On peut alors visualiser, rechercher, comparer et télécharger les artéfacts et métadonnées de passages pour les passages journalisés dans le cadre d'un essai MLflow.
Les données d'un essai peuvent être journalisées comme passage dans MLflow à l'aide de progiciels MLflow Python, R ou Java ou au moyen de l'IPA (interface de programmation d'applications) REST.
Le présent article fait la démonstration de la modélisation d'un des concours de mise en route de TLN (traitement du langage naturel) sur Kaggle intitulé « Natural Language Processing with Disaster Tweets (le contenu de cette page est en anglais) ». On utilise un carnet Jupyter et l'IPA Python de MLflow pour journaliser des données dans MLflow. Nous mettrons l'accent sur la démonstration de la façon de journaliser des données dans MLflow au cours de la modélisation, plutôt que sur l'obtention des meilleurs résultats de modélisation.
Tout d'abord, commençons par le processus de modélisation habituel, qui inclut des importations, la lecture de données, le prétraitement de texte, les caractéristiques de pondération rtf-idf (term frequency-inverse document frequency) et le modèle de machine à vecteurs de support (SVM). À la fin, une section sera intitulée « Journalisation dans MLflow ».
Note : Nous maintenons le pipeline TLN aussi simple que possible, afin de porter l'accent sur la journalisation dans MLflow. Certaines des étapes habituelles, comme l'analyse exploratoire des données, ne s'appliquent pas à cet objectif et nous ne les mentionnons donc pas. La façon préférable de journaliser des données dans MLflow est en laissant une portion de code à la fin de la journalisation. Vous pouvez également configurer MLflow au début du code et journaliser les données tout au long du code, lorsque les données ou variables sont disponibles à la journalisation. Un avantage de journaliser toutes les données ensemble à la fin à l'aide d'une seule cellule est que le pipeline entier se termine avec succès et le passage journalise les données (tant que le code de journalisation dans MLflow ne comporte aucun bogue). Si les données sont journalisées tout au long du code et que l'exécution du code est interrompue pour une raison ou une autre, la journalisation des données sera alors incomplète. Toutefois, en cas de scénario où un code comporte plusieurs portions de code (ce qui entraîne une longue exécution), la journalisation tout au long du code, à de multiples emplacements, peut en fait être bénéfique.
Importation des bibliothèques
Commencez par importer toutes les bibliothèques requises par l'exemple :
# To create unique run name.
import time
# To load data in pandas dataframe.
import pandas as pd
# NLP libraries
# To perform lemmatization
from nltk import WordNetLemmatizer
# To split text into words
from nltk. tokenize import word_tokenize
# To remove the stopwords
from nltk.corpus import stopwords
# Scikit-learn libraries
# To use the SVC model
from sklearn.svm import SVC
# To evaluate model performance
from sklearn.model_selection import cross_validate, StratifiedkFold
# To perform Tf-idf vectorization
from sklearn.feature_extraction.text import TfidfVectorizer
# To get the performance metrics
from sklearn.metrics import f1_score, make_scorer
# For logging and tracking experiments
import mlflow
Création d'un nom de passage unique
MLflow permet de suivre plusieurs passages d'un essai grâce à un paramètre de nom de passage. Le nom du passage peut être défini comme toute valeur, mais devrait être unique, afin de pouvoir être identifié ensuite parmi les différents passages. Ci-dessous, un horodatage est utilisé comme nom unique.
run_name = str(int(time.time()))
print('Run name: ', run_name)
On obtient :
Nom de passage : 1625604741 Lecture des données
Chargez la formation et les données de test à partir des fichiers CSV fournis pour l'exemple.
# Kaggle competition data download link: https://www.kaggle.com/c/nlp-getting-started/data
train_data = pd.read_csv("./data/train.csv")
test_data = pd.read_csv("./data/test.csv")
En exécutant la portion de code suivant dans une cellule :
train_data
La figure 1 présente un exemple de données de formation venant d'être chargées.
Figure 1 : Aperçu des données de formation chargées
![]()
Figure 1 : Aperçu des données de formation chargées
Cinq premières et dernières entrées du fichier CSV. Il contient les colonnes id, mot clé, emplacement, texte et cible. Les colonnes de texte contiennent le tweet en tant que tel et la colonne cible, la catégorie.
| id | Mot clé | Emplacement | Texte | Cible | |
|---|---|---|---|---|---|
| 0 | 1 | NaN | Nan | Our Deeds are the Reason of this #earthquake M… | 1 |
| 1 | 4 | NaN | Nan | Forest fire near La Ronge Sask. Canada | 1 |
| 2 | 5 | NaN | Nan | All residents asked to 'shelter in place' are… | 1 |
| 3 | 6 | NaN | Nan | 13,000 people receive #wildfires evacuation or… | 1 |
| 4 | 7 | NaN | Nan | Just got sent this photo from Ruby #Alaska as… | 1 |
| ... | ... | ... | ... | ... | ... |
| 7608 | 10869 | NaN | Nan | Two giant cranes holding a bridge collapse int… | 1 |
| 7609 | 10870 | NaN | Nan | @aria_ahrary @TheTawniest The out of control w… | 1 |
| 7610 | 10871 | NaN | Nan | M1.94 [01:04 UTC] ?5km S of Volcano Hawaii. Htt… | 1 |
| 7611 | 10872 | NaN | Nan | Police investigating after an e-bike collided… | 1 |
| 7612 | 10873 | NaN | Nan | The Latest: More Homes Razed by Northern Calif… | 1 |
7613 lignes x 5 colonnes
Les données de formation représentent environ 70 % des données totales.
print('The length of the training data is %d' % len(train_data))
print('The length of the test data is %d' % len(test_data))
Produit :
The length of the training data is 7613
The length of the test data is 3263
Prétraitement de texte
Selon la tâche à réaliser, différents types d'étapes de prétraitement peuvent être nécessaires pour que le modèle d'apprentissage automatique apprenne de meilleures caractéristiques. Le prétraitement peut normaliser les intrants, supprimer certains mots courants, le cas échéant, de sorte que le modèle ne les apprenne pas comme des caractéristiques, et apporter des modifications logiques et utiles pouvant mener à une amélioration du rendement et de la généralisation du modèle. La section suivante montre comment des étapes de prétraitement peuvent aider le modèle à capturer les caractéristiques pertinentes au cours de l'apprentissage.
def clean_text(text):
# split into words
tokens = word_tokenize(text)
# remove all tokens that are not alphanumeric. Can also use .isalpha() here if do not want to keep numbers.
words = [word for word in tokens if word.isalnum()]
# remove stopwords
stop_words = stopwords.words('english')
words = [word for word in words if word not in stop_words]
# performing lemmatization
wordnet_lemmatizer = WordNetLemmatizer()
words = [wordnet_lemmatizer.lemmatize(word) for word in words]
# Converting list of words to string
words = ' '.join(words)
return words
train_data['cleaned_text'] = train_data['text'].apply(clean_text)
Lors de la comparaison du texte d'origine et du texte nettoyé, les pseudo-mots ont été supprimés :
train_data['text'].iloc[100]
'.@NorwayMFA #Bahrain police had previously died in a road accident they were not killed by explosion https://t.co/gFJfgTodad (en anglais seulement)'
train_data['cleaned_text'].iloc[100]rain_data['text'].iloc[100]
'NorwayMFA Bahrain police previously died road accident killed explosion http'
À la lecture du texte ci-dessus, on peut dire qu'il contient des renseignements sur une catastrophe et devrait donc être classé comme tel. Pour confirmer cela avec les données, imprimez l'étiquette présente dans le fichier CSV relatif à ce tweet :
train_data['target'].iloc[100]
Produit :
1
Caractéristiques Tf-idf
Ensuite, nous convertissons une collection de documents bruts vers une matrice de caractéristiques TF-IDF en vue d'alimenter le modèle. Pour de plus amples détails sur tf-idf, reportez-vous aux documents TF–IDF - Wikipédia and scikit-learn sklearn.feature_extraction.text (le contenu de cette page est en anglais).
ngram_range=(1,1)
max_features=100
norm='l2'
tfidf_vectorizer = TfidfVectorizer(ngram_range=ngram_range, max_features=max_features, norm=norm)
train_data_tfidf = tfidf_vectorizer.fit_transform(train_data['cleaned_text'])
train_data_tfidf
Produit :
<7613x100 sparse matrix of type '<class 'numpy.float64'>'
with 15838 stored elements in Compressed Sparse Row format>
tfidf_vectorizer.get_feature_names()[:10]
Produit :
['accident',
'amp',
'and',
'as',
'attack',
'back',
'best',
'body',
'bomb',
'building']
Modèle SVC
L'étape suivante de la modélisation est d'ajuster un modèle et d'évaluer son rendement.
On utilise un programme de validation croisée K-Folds stratifié pour évaluer le modèle. Voir scikit learn sklearn.model_selection (le contenu de cette page est en anglais) pour de plus amples détails.
strat_k_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
Faire fonctionner un programme de calcul de résultat à l'aide de la mesure f1-score pour l'utiliser comme paramètre dans le modèle SVC.
scoring_function_f1 = make_scorer(f1_score, pos_label=1, average='binary')
Vient ensuite une étape importante pour adapter le modèle aux données. Dans cet exemple, le classificateur SVC est utilisé. Voir scikit learn sklearn.svm.svc (le contenu de cette page est en anglais) pour de plus amples détails.
C = 1.0
kernel='poly'
max_iter=-1
random_state=42
svc = SVC(C=C, kernel=kernel, max_iter=max_iter, random_state=random_state)
cv_results = cross_validate(estimator=svc, X=train_data_tfidf, y=train_data['target'], scoring=scoring_function_f1, cv=strat_k_fold, n_jobs=-1, return_train_score=True)
cv_results
Produit :
{'fit_time': array([0.99043322, 0.99829006, 0.94024873, 0.97373009, 0.96771407]),
'score_time': array([0.13656974, 0.1343472 , 0.13345313, 0.13198996, 0.13271189]),
'test_score': array([0.60486891, 0.65035517, 0.5557656 , 0.5426945 , 0.63071895]),
'train_score': array([0.71281362, 0.76168757, 0.71334394, 0.7291713 , 0.75554698])}
def mean_sd_cv_results(cv_results, metric='F1'):
print(f"{metric} Train CV results: {cv_results['train_score'].mean().round(3)} +- {cv_results['train_score'].std().round(3)}")
print(f"{metric} Val CV results: {cv_results['test_score'].mean().round(3)} +- {cv_results['test_score'].std().round(3)}")
mean_sd_cv_results(cv_results)
F1 Train CV results: 0.735 +- 0.021
F1 Val CV results: 0.597 +- 0.042
Note : Le code ci-dessous est exécuté comme une commande d'interface système en ajoutant le point d'exclamation : « ! » au début du code dans une cellule Jupyter.
! Jupyter nbconvert --to html mlflow-example-real-or-not-disaster-tweets-modeling-SVC.ipynb
[NbConvertApp] Converting notebook mlflow-example-real-or-not-disaster-tweets-modeling-SVC.ipynb to html
[NbConvertApp] Writing 610630 bytes to mlflow-example-real-or-not-disaster-tweets-modeling-SVC.htmlJournalisation dans MLflow
Tout d'abord, configurez le serveur URI. Le serveur s'exécutant localement, définissez l'URI de suivi comme port de serveur local 5000. L'URI de suivi peut être configurée pour un serveur distant également (voir : Where Runs are Recorded [le contenu de cette page est en anglais]).
server_uri = 'http://127.0.0.1:5000'
mlflow.set_tracking_uri(server_uri)Pour organiser les passages, un essai a été créé et défini à l'emplacement où les passages seront journalisés. La méthode « set_experiment » créera un nouveau passage avec le nom de chaîne fourni et le définira comme l'essai en cours pour lequel les passages seront journalisés.
mlflow.set_experiment('nlp_with_disaster_tweets')Enfin, lancez un passage et journalisez les données dans MLflow.
# MLflow logging.
with mlflow.start_run(run_name=run_name) as run:
# Logging tags
# run_name.
mlflow.set_tag(key='Run name', value=run_name)
# Goal.
mlflow.set_tag(key='Goal', value='Check model performance and decide whether we require further pre-processing/hyper-parameter tuning.')
# Modeling exp.
mlflow.set_tag(key='Modeling technique', value='SVC')
# Logging parameters
mlflow.log_param(key='ngram_range', value=ngram_range)
mlflow.log_param(key='max_features', value=max_features)
mlflow.log_param(key='norm', value=norm)
mlflow.log_param(key='C', value=C)
mlflow.log_param(key='kernel', value=kernel)
mlflow.log_param(key='max_iter', value=max_iter)
mlflow.log_param(key='random_state', value=random_state)
# Logging the SVC model.
mlflow.sklearn.log_model(sk_model=svc, artifact_path='svc_model')
# Logging metrics.
# mean F1-score - train.
mlflow.log_metric(key='mean F1-score - train', value=cv_results['train_score'].mean().round(3))
# mean F1-score - val.
mlflow.log_metric(key='mean F1-score - val', value=cv_results['test_score'].mean().round(3))
# std F1-score - train.
mlflow.log_metric(key='std F1-score - train', value=cv_results['train_score'].std().round(3))
# std F1-score - val.
mlflow.log_metric(key='std F1-score - val', value=cv_results['test_score'].std().round(3))
# Logging the notebook.
# Nb.
mlflow.log_artifact(local_path='real-or-not-disaster-tweets-modeling-SVC.ipynb', artifact_path='Notebook')
# Nb in HTML.
mlflow.log_artifact(local_path='real-or-not-disaster-tweets-modeling-SVC.html', artifact_path='Notebook')
Selon le code ci-dessus, vous commencez un passage avec un nom de passage (run_name), puis journalisez ce qui suit :
- Balises : paire clé-valeur. La clé et la valeur sont toutes deux des chaînes; par exemple, cela peut servir à journaliser l'objectif du passage pour lequel la clé serait « Goal: » et la valeur peut être « To try out the performance of Random Forest Classifier with default parameters » (mettre à l'essai le rendement d'un classificateur de forêt aléatoire avec des paramètres par défaut).
- Paramètres : également une paire clé-valeur pouvant servir à journaliser les paramètres du modèle.
- Modèle : peut servir à journaliser le modèle. Vous journalisez ici un modèle scikit-learn comme artéfact MLflow, mais nous pouvons également journaliser un modèle pour d'autres bibliothèques d'apprentissage automatique pris en charge à l'aide du module MLflow correspondant.
- Mesures : paire clé-valeur. Le type de données de clé est « string » (chaîne) et peut avoir le nom de la mesure. Le paramètre de valeur est de type de données « float ». Le troisième paramètre facultatif est « step » qui est un nombre entier représentant toute mesure de progression de la formation : nombre d'itération de formation, nombre d'époques, etc.
- Artéfacts : un fichier ou répertoire local peut être journalisé comme artéfact pour le passage en cours. Dans cet exemple, nous journalisons à l'aide du carnet, de sorte que ces informations sont accessibles pour des passages futurs. Ce faisant, il est possible d'enregistrer un tracé comme « courbe de perte » ou « courbe de précision » dans le code et le journaliser comme artéfact dans MLflow.
Voilà, vous avez journalisé avec succès les données pour un passage dans MLflow! L'étape suivante est de visualiser les données journalisées.
IU de MLflow
Si vous retournez à la figure 1, vous vous souviendrez que vous avez lancé le serveur et qu'il écoutait au port de serveur local 5000. Ouvrez cette adresse dans votre navigateur préféré pour accéder à l'IU de MLflow. Une fois l'IU de Mlflow visible, vous pouvez utiliser l'interface pour consulter les données d'essai journalisées. Les essais créés s'affichent dans la barre latérale de l'IU et les balises, paramètres, modèle et mesures journalisés figurent dans les colonnes.
Figure 2 : IU de MLflow
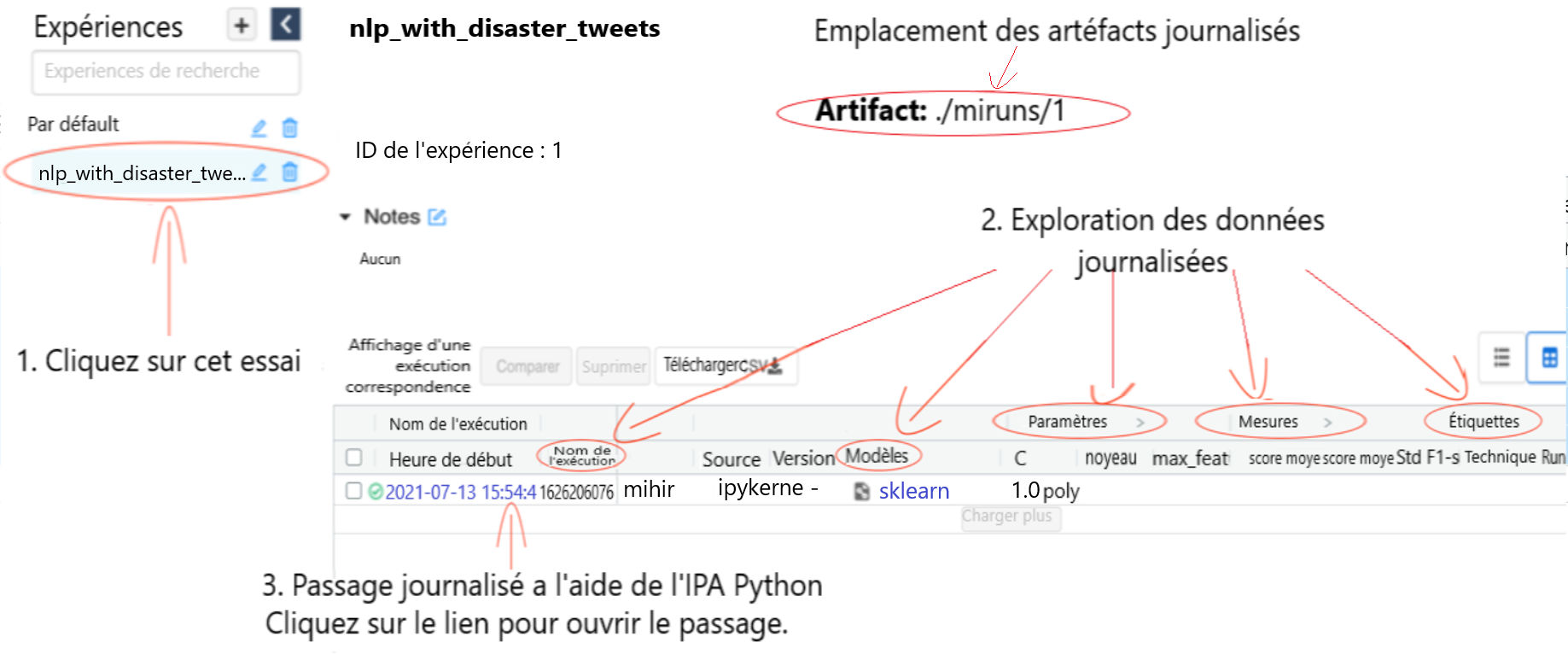
Figure 2 : IU de MLflow
La figure 2 présente l'IU de MLflow. L'essai configuré ci-dessus, c.-à-d. nlp_with_disaster_tweets est ouvert ainsi que le passage précédemment journalisé avec les détails comme le nom du passage, les paramètres et les mesures. Il indique également l'emplacement où sont enregistrés les artéfacts. Vous pouvez cliquer sur le passage journalisé pour l'explorer plus en détail.
Text in image: Modèles MLflow
Nlp_with_disaster_tweets (1. Cliquez sur cet essai)
ID de l'experience : 1. Emplacement de l'artéfact : ./miruns/1 (Emplacement des artéfacts journalisés)
Notes : Aucun
2. Exploration des données journalisées
| Paramètres | Mesures | Étiquettes | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Heure de début | Nom de l'exécution | Utilisateur | Source : | Version | Modèles | C | Noyau | max_feature | Score moyen | Score moyen | Std F1-scor | Technique : |
| 2021-07-13 15:54:45 | 1626206076 | Mihir | ipykerne | - | sklearn | 1.0poly | ||||||
3. Passage journalisé à l'aide de l'IPA Python. Cliquez sur le lien pour ouvrir le passage
Pour explorer un passage particulier plus en détail, cliquez sur le passage pertinent dans la colonne Heure de début. Cela permet d'explorer un passage journalisé en détail. Le nom du passage s'affiche et vous pouvez ajouter des notes relatives au passage, comme les paramètres, mesures, balises et artéfacts journalisés. Les données journalisées à l'aide de l'API Python pour ce passage figurent ici.
Les fichiers journalisés comme artéfacts peuvent être téléchargés; ce qui peut être utile si vous souhaitez extraire le code ultérieurement. Puisque le code ayant généré des résultats pour chaque passage est enregistré, vous n'avez pas à créer plusieurs copies du même code et pouvez expérimenter avec un seul carnet-cadre en changeant le code entre les passages.
Le modèle formé journalisé peut être chargé dans un essai futur à l'aide de l'IPA Python pour le passage journalisé.
Figure 3: Exploration des artéfacts journalisés dans un passage
![]()
Figure 3: Exploration des artéfacts journalisés dans un passage
La figure 3 explore les artéfacts journalisés. Les fichiers journalisés (carnet et modèle) sont présentés. La description du modèle fournit également le code permettant de charger le modèle journalisé dans Python.
Texte de l'image :
| Nom | Valeur | Actions |
|---|---|---|
| Objectif | Vérifier les performances du modèle et décidez si nous avons besoin d'un prétraitement/réglage hyperparamètres supplémentaire. | Vérification : supprimer les icônes |
| Technique de modélisation | SVC | Vérification : supprimer les icônes |
| Nom de passage | 16525862471 | Vérification : supprimer les icônes |
Ajouter une balise
Nom – Valeur – Ajout
Artéfacts
Carnet
- Real-or-not-disaster-tweets-modeling-SVC.html
- Real-or-not-disaster-tweets-modeling-SVC.ipynb
svc_model
- Modèle ML
- conda.yaml
- model.pkl
Chemin complet : ./miruns/1/b4af92528b1o4552b45231edeb6fe782/artefacts/Carnet
Taille : 0B
Modèle MLflow
Les extraits de code ci-dessous montrent comment faire des prédictions à l'aide du modèle enregistré.
Schéma du modèle
Schéma d'entrées et de sortie pour votre modèle. En savoir plus
Nom – Type
Pas de schéma
Pour démontrer la fonctionnalité de comparaison de passages, d'autres essais de modélisation ont été effectués et journalisés dans MLflow en changeant quelques paramètres dans le même carnet jupyter. N'hésitez pas à modifier certains paramètres et à journaliser davantage de passages dans MLflow.
La figure 4 présente les différents passages journalisés. Vous pouvez appliquer un filtre, conserver les colonnes souhaitées et comparer les paramètres ou les mesures entre les différents passages. Pour procéder à une comparaison détaillée, vous pouvez sélectionner les passages que vous souhaitez comparer et cliquer sur le bouton « Comparer » encerclé dans la figure ci-dessous.
Figure 4 : Personnalisation et comparaison de différents passages à l'aide de l'IU de MLflow
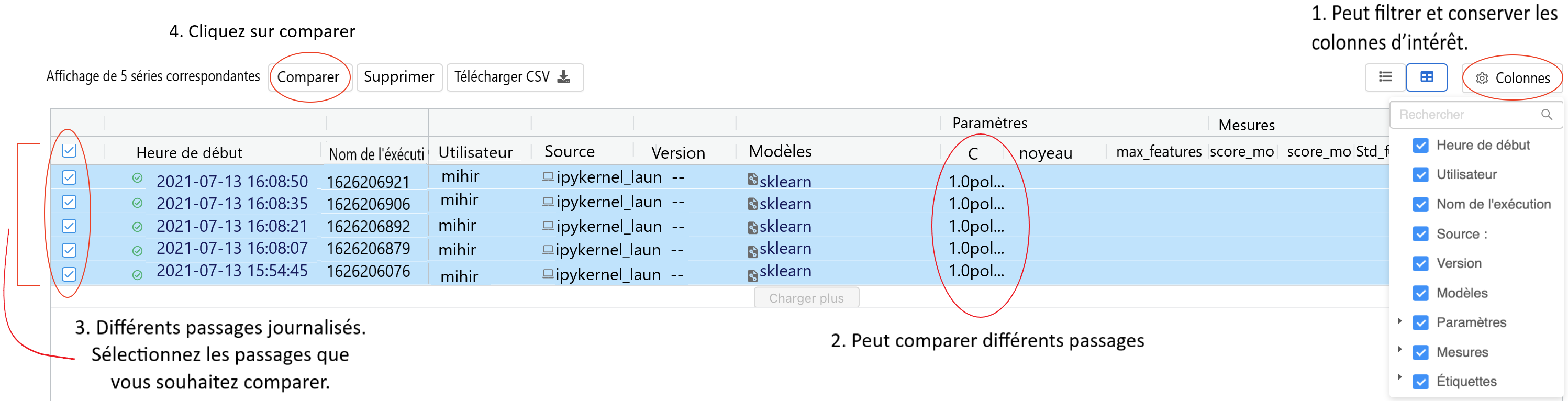
Figure 4 : Personnalisation et comparaison de différents passages à l'aide de l'IU de MLflow
Dans l'IU de MLflow, on peut personnaliser les colonnes affichées, appliquer un filtre et rechercher différents passages en fonction des données journalisées et facilement comparer les différents passages journalisés en fonction des colonnes visibles. On peut également comparer les différents passages journalisés plus en détail en les sélectionnant et en cliquant sur le bouton « Comparer ».
Texte de l'image :
1. Peut filtrer et conserver les colonnes d'intérêt.
Colonnes : Heure de début, Nom de l'exécution, Utilisateur, Source, Version, Modèles, Paramètres, Mesures, Balises
2. Peut comparer différents passages
3. Différents passages journalisés. Sélectionnez les passages que vous souhaitez comparer.
Affichage de 5 passages correspondants. Comparer, Supprimer, Télécharger, CSV
4. Cliquez sur comparer
| Parameters | Mesures | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Heure de début | Nom du passage | Utilisateur | Source | Version | Modèles | C | Noyau | max_features | Score mo | Score mo | Std F1-s |
| 2021-07-13 16:08:50 | 1626115725 | Mihir | Ipykerne_laun | - | sklearn | 1.0pol... | |||||
| 2021-07-13 16:08:35 | 1626115688 | Mihir | Ipykerne_laun | - | sklearn | 1.0pol... | |||||
| 2021-07-13 16:08:21 | 1626115602 | Mihir | Ipykerne_laun | - | sklearn | 1.0pol... | |||||
| 2021-07-13 16:08:07 | 1626115552 | Mihir | Ipykerne_laun | - | sklearn | 1.0pol... | |||||
| 2021-07-13 15:54:45 | 1625002471 | Mihir | Ipykerne_laun | - | sklearn | 1.0pol... | |||||
Après avoir cliqué sur le bouton « Comparer », une comparaison sous forme de tableau entre différents passages est générée (comme le présente la figure 5), permettant de facilement comparer les données journalisées pour différents passages. Les paramètres qui diffèrent entre les passages sont surlignés en jaune. Cela fournit à l'utilisateur une idée de la façon dont le rendement du modèle a varié au fil du temps en fonction des paramètres modifiés.
Figure 5 : Comparaison détaillée de passages journalisés dans l'IU de MLflow
![]()
Figure 5 : Comparaison détaillée de passages journalisés dans l'IU de MLflow
La figure 5 compare en détail différents passages journalisés dans MLflow. Les balises, paramètres et mesures figurent sur différentes lignes et les passages, dans différentes colonnes. Cela permet à un utilisateur de comparer les détails d'intérêt pour différents passages dans une seule fenêtre. Les paramètres qui diffèrent entre les passages sont surlignés en jaune. Par exemple, dans les essais, les paramètres max_features et ngram_range ont été modifiés pour différents passages et sont donc surlignés en jaune dans l'image ci-dessus.
Texte de l'image :
Nlp_with_disaster_tweets > Comparaison de 5 passages
| ID d'exécution : | 7a1448a5f88147c093 c357d787dbe3 |
264533b107b04be3 bd4981560bad0397 |
7670578718b3477abb 798d7e404fed6c |
D2372d5873f2435c 94dc7e633a611889 |
Fdc8362b2f37432f9 a4128fa522d80cb |
|---|---|---|---|---|---|
| Nom du passage | 1626115725 | 1626115688 | 1626115602 | 1626115552 | 16265862471 |
| Heure de début | 2021-07-12 14:48:54 | 2021-07-12 14:48:16 | 2021-07-12 14:48:50 | 2021-07-12 14:46:01 | 2021-07-09 16:27:58 |
| Paramètres | |||||
| C | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| Noyau | Poly | Poly | Poly | Poly | Poly |
| Max_features | 500 | 500 | 500 | 500 | 500 |
| Max_iter | -1 | -1 | -1 | -1 | -1 |
| Ngram_range | (1.3) | (1.2) | (1.1) | (1.1) | (1.1) |
| Norm | 12 | 12 | 12 | 12 | 12 |
| random_state | 42 | 42 | 42 | 42 | 42 |
| Mesures | |||||
| Mean f1-score-train | 0.93 | 0.931 | 0.933 | 0.876 | 0.735 |
| Mean f1-score-val | 0.694 | 0.693 | 0.694 | 0.649 | 0.597 |
| std f1-score-train | 0.001 | 0.001 | 0.002 | 0.002 | 0.021 |
| std f1-score-val | 0.008 | 0.009 | 0.01 | 0.013 | 0.042 |
Des changements dans les paramètres et dans les mesures pour différents passages peuvent également être présentés dans un diagramme de dispersion. Les valeurs des axes des x et des y peuvent être définies comme tout paramètre ou toute mesure permettant à l'utilisateur d'analyser les changements. Dans la figure 6, le lecteur peut analyser la variation de la validation; dans ce cas, le F1-score moyen pour différentes valeurs du paramètre « max_features ». Si vous passez le curseur sur un point de donnée, les détails relatifs à ce passage s'affichent.
Figure 6 : Configuration du diagramme de dispersion pour visualiser les effets des différentes configurations de paramètres dans les passages journalisés
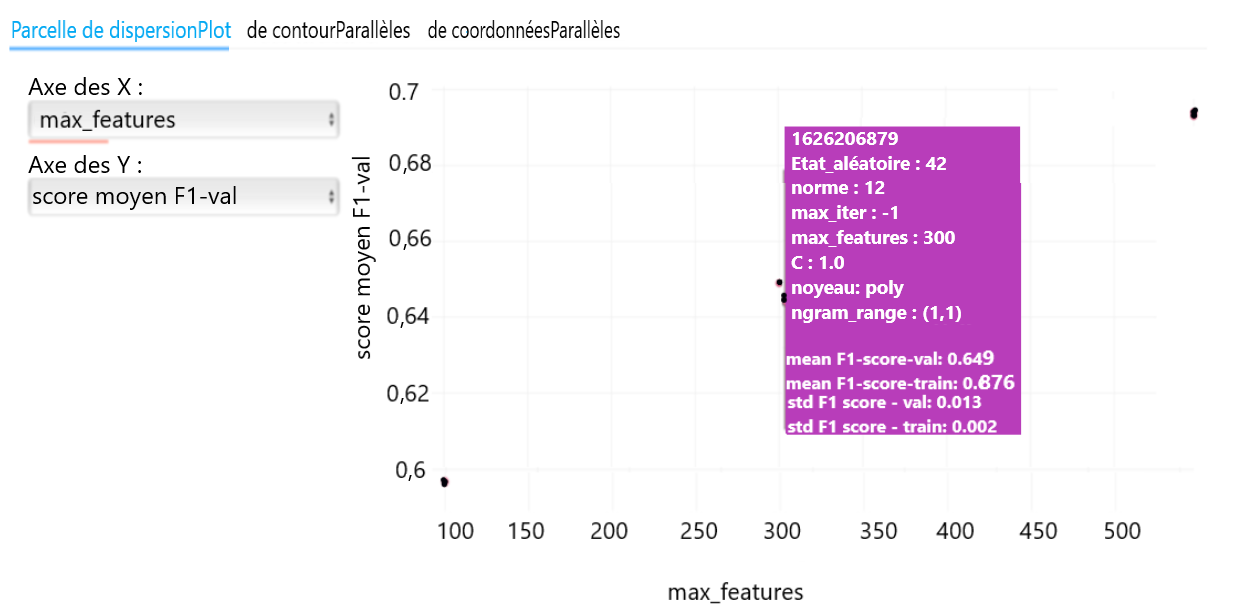
Figure 6 : Configuration du diagramme de dispersion pour visualiser les effets des différentes configurations de paramètres dans les passages journalisés
Démonstration des capacités de MLflow de produire un diagramme à l'aide des détails de différents passages. Vous pouvez sélectionner un paramètre particulier sur l'axe des X ainsi qu'une mesure que vous souhaitez surveiller sur l'axe des Y; cela crée immédiatement un diagramme de dispersion fournissant les détails sur l'axe correspondant et permet de visualiser les effets des paramètres sur la mesure, afin de vous faire une idée de la manière dont le paramètre influe sur la mesure.
Texte de l'image :
Parcelle de dispersionPlot – de contourParallèles – de coordonnées Parallèles
Axe des X : max_features
Axe des Y : score moyen F1 - val
| 1626115552 | |
|---|---|
| État_aléatoire : | 42 |
| Norme : | 12 |
| Max_iter : | -1 |
| Max_features : | 300 |
| C : | 1.0 |
| Noyeau : | Poly |
| Ngram_range : | (1.1) |
| Mean f1-score-val | 0.649 |
| Mean f1-score-train | 0.876 |
| std f1-score-val | 0.002 |
| std f1-score-train | 0.013 |
Le diagramme à coordonnées parallèles est également utile, car il présente à l'utilisateur d'un seul coup d'œil l'effet de certains paramètres sur les mesures souhaitées.
Figure 7 : Configuration du diagramme à coordonnées parallèles pour visualiser les effets de différents paramètres sur les mesures d'intérêt
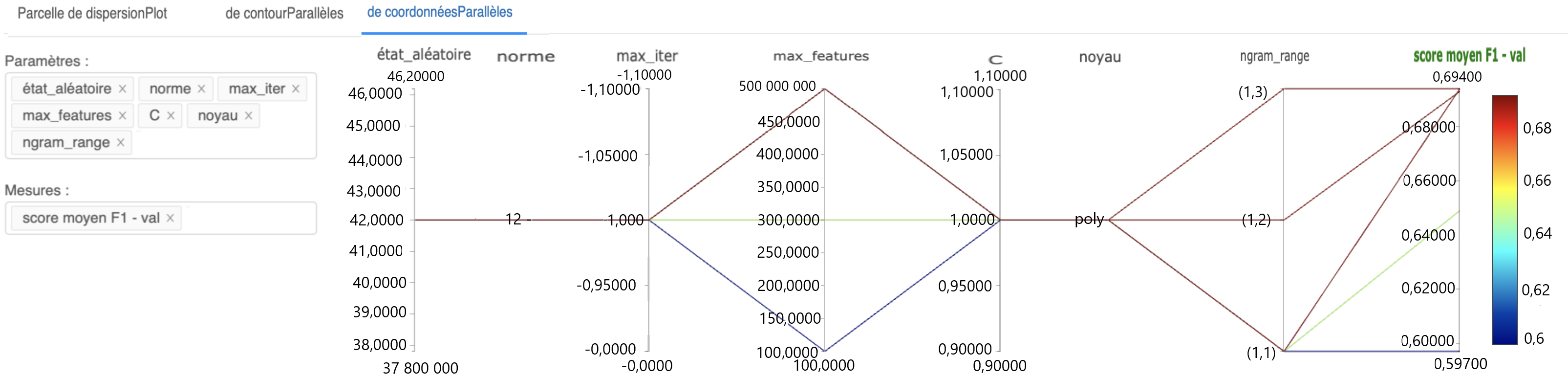
Figure 7 : Configuration du diagramme à coordonnées parallèles pour visualiser les effets de différents paramètres sur les mesures d'intérêt
Dans cette image, un diagramme à coordonnées parallèles est configuré. Vous pouvez sélectionner différents paramètres et différentes mesures à l'aide des fenêtres d'intrants fournies; le diagramme à coordonnées parallèles est mis à jour en conséquence. Ce diagramme peut donner une idée des résultats obtenus à l'aide de différentes configurations dans les essais. Il peut aider à comparer les différentes configurations et à sélectionner les paramètres fournissant un meilleur rendement.
Texte de l'image :
Parcelle de dispersionPlot – de contourParallèles – de coordonnéesParallèles
Paramètres : état_alléatoire, norme, max_iter, max_features, C, noyeau, ngram_range
Mesures : score moyen F1 - val
| état_aléatoire | norme | Max_iter | Max_features | C | noyeau | ngram_range | Score moyen F1-val | |
|---|---|---|---|---|---|---|---|---|
| 46.20000 | -1.10000 | 500.00000 | 1.10000 | 0.69400 | ||||
| 46.0000 | -1.10000 | 500.00000 | 1.10000 | (1.3) | 0.68000 | 0.68 | ||
| 45.0000 | 450.00000 | |||||||
| 44.0000 | -1.05000 | 400.00000 | 1.05000 | 0.66000 | 0.66 | |||
| 43.0000 | 350.00000 | |||||||
| 42.0000 | -1.0000 | 300.00000 | 1.00000 | poly | (1.2) | 0.64000 | 0.64 | |
| 41.0000 | 250.00000 | |||||||
| 40.0000 | -0.95000 | 200.00000 | 0.95000 | 0.62000 | 0.62 | |||
| 39.0000 | 150.00000 | |||||||
| 38.0000 | -0.9000 | 100.00000 | 0.90000 | (1.1) | 0.60000 | 0.6 | ||
| 37.80000 | -0.90000 | 100.0000 | 0.9000 | 0.59700 |
Autres aspects intéressants du suivi avec MLflow Tracking
Autres éléments importants à noter relativement à MLflow Tracking :
- Les passages peuvent être directement exportés dans un fichier CSV à l'aide de l'IU de MLflow.
- Il est possible d'accéder à l'aide d'un programme à toutes les fonctions de l'IU de suivi; vous pouvez interroger et comparer les passages avec du code, charger des artéfacts de passages journalisés ou exécuter une recherche automatisée de paramètre en appliquant une requête sur les mesures de passages journalisés pour décider des nouveaux paramètres. Vous pouvez également journaliser de nouvelles données sur un passage déjà journalisé dans un essai après l'avoir chargé à l'aide d'un programme (consultez Querying Runs Programmatically pour de plus amples détails - le contenu de cette page est en anglais).
- En utilisant l'IU de MLflow, les utilisateurs peuvent rechercher des passages présentant des valeurs de données particulières à partir de la barre de recherche. Un exemple de cela serait d'utiliser
metrics.rmse < 1etparams.model='tree'. Cela est très utile lorsque vous avez besoin de trouver un passage à paramètres particuliers exécuté par le passé. - Le carnet Jupyter utilisé comme exemple dans ce billet de blogue est accessible sur GitHub (le contenu de cette page est en anglais).
N'hésitez pas à communiquer avec nous à l'adresse statcan.dsnfps-rsdfpf.statcan@statcan.gc.ca pour nous faire part d'autres fonctionnalités intéressantes ou cas d'utilisation que vous aimez utiliser qui auraient pu être mentionnés selon vous. Nous vous offrirons également l'occasion de rencontrer le scientifique des données pour discuter de MLFlow plus en détail. Trouvez de plus amples détails ci-dessous.

Si vous avez des questions à propos de cet article ou si vous souhaitez en discuter, nous vous invitons à notre nouvelle série de présentations Rencontre avec le scientifique des données où le(s) auteur(s) présenteront ce sujet aux lecteurs et aux membres du RSD.
Mardi, le 18 octobre
14 h 00 à 15 h 00 HAE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données. À bientôt !
- Date de modification :