
Mise en œuvre des pratiques MLOps avec Azure
Par : Jules Kuehn, Services partagés Canada
Les pratiques MLOps sont une variante des pratiques DevOps qui répondent à des préoccupations relatives à l'apprentissage automatique (AA). Tout comme le processus DevOps, le processus MLOps permet l'intégration et le déploiement continus (IC/DC) (le contenu de cette page est en anglais) de modèles d'apprentissage automatique (AA), mais automatise en outre le réentraînement sur de nouvelles données et effectue le suivi des résultats des différentes sessions d'entraînement (ou expériences).
Un problème courant avec les modèles d'AA est la baisse du rendement au fil du temps. C'est ce que l'on appelle une « dérive » (consultez le guide ultime du réentraînement de modèle (le contenu de cette page est en anglais) pour obtenir de plus amples renseignements sur la dérive). Imaginez un modèle d'AA prédisant si une maison à Ottawa se vendra au-dessus du prix demandé, selon les renseignements sur la maison et le prix d'inscription. Lorsque le modèle a été déployé il y a cinq ans, il a été en mesure de fournir cette prédiction avec 95 % d'exactitude. Toutefois, si le modèle n'était pas réentraîné avec des données mises à jour, ses prédictions ne refléteraient pas le marché du logement actuel d'Ottawa et seraient donc moins exactes. Pour résoudre ce problème, un système MLOps peut automatiquement réentraîner et redéployer des modèles, afin d'intégrer des données plus récentes et suivre le rendement du modèle au fil du temps.
L'équipe de la Science des données et de l'Intelligence artificielle de Services partagés Canada (SPC) a élaboré plusieurs modèles d'AA comme solutions de validation de principe aux problèmes opérationnels de SPC. Le point de départ du parcours du processus MLOps a été la collaboration de l'équipe avec Microsoft afin de développer une solution MLOps fonctionnelle entièrement au sein de l'écosystème Azure.
Le système MLOps comprend plusieurs composantes, comme le contrôle des sources, le suivi des expériences, les registres de modèles, les pipelines IC/DC, les API Azure ML, Docker et Kubernetes. L'utilisation de ce système permet à l'équipe de continuellement livrer des API REST pour les modèles d'AA les plus performants et de les mettre à disposition dans le nouveau magasin des API du gouvernement du Canada.
Élaboration d'un modèle
Pour accélérer la mise en œuvre, l'équipe a utilisé les fonctions SaaS (logiciel en tant que service) d'Azure pour exécuter la majorité des tâches. Cela comprenait le chargement des données avec Azure Data Factory, le développement de modèle dans les carnets Azure Databricks, le suivi expérimental et le déploiement de modèle avec Azure ML, ainsi que le contrôle des sources et l'IC/DC avec Azure DevOps.
Suivi des expériences et des modèles
Les carnets Databricks journalisent les mesures des sessions et enregistrent les modèles dans un espace de travail Azure ML à la fin d'une session entraînement (consultez les pages Journaliser et afficher les métriques et les fichiers journaux et Classe de modèle pour de plus amples détails). Cela est utile lorsque les sessions sont lancées manuellement pendant l'élaboration du modèle et lorsqu'elles sont exécutées comme une tâche au sein de pipelines IC/DC. Au cours de l'élaboration d'un modèle, il est possible de suivre les améliorations apportées aux mesures, comme l'exactitude, tout en ajustant les hyperparamètres. Dans le cas d'une session en tant que tâche de pipeline, il est alors possible de surveiller les changements apportés aux mesures lorsque de nouvelles données sont utilisées dans le cadre d'un réentraînement.
Contrôle des sources et intégration continue
Le répertoire de contrôle des sources pour ce modèle est composé de trois dossiers :
- Carnets : le code des carnets Databricks
- Pipelines : deux pipelines pour entraîner et déployer les modèles
- API : le code servant à envelopper le modèle entraîné dans une API REST.
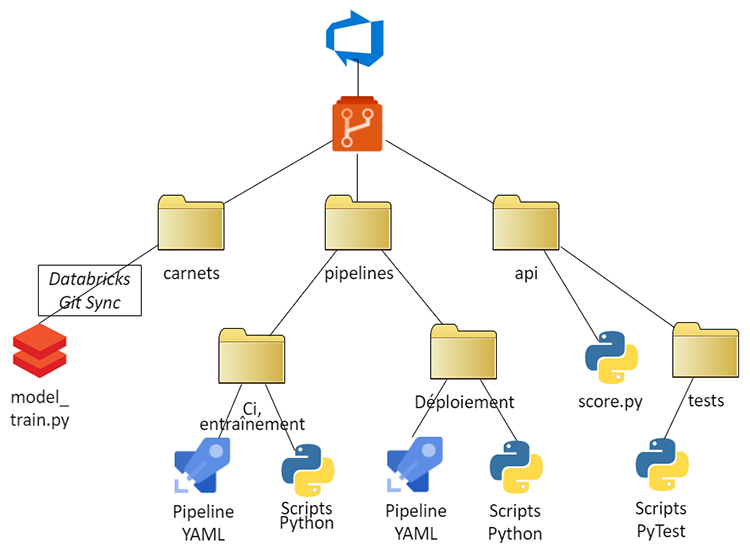
Figure 1 – Structure générale du répertoire de contrôle des sources
Description - Figure 1
Arborescence du dépôt DevOps avec 3 dossiers de haut niveau. Le premier dossier est le Carnet de notes, qui est connecté via Databricks Git Sync à model_train.py. Le deuxième dossier est Pipelines, qui contient deux sous-dossiers, chacun contenant Pipeline YAML et des scripts Python. Ces sous-dossiers sont nommés "ci / train" et "deploy". Le troisième dossier de premier niveau est "API", qui contient score.py et un sous-dossier tests, qui contient des scripts PyTest.
Pipeline de demandes d'extraction de carnets
Même si la programmation littéraire à l'aide de carnets (p. ex. Jupyter) est une pratique courante en science des données, les environnements de carnets infonuagiques ne s'intègrent pas toujours efficacement au contrôle des sources. Le travail de plusieurs membres de l'équipe sur un projet peut entraîner une désorganisation des carnets. L'équipe a élaboré un déroulement des opérations qui intègre des pratiques exemplaires de gestion du contrôle des sources, comme les branches par fonctionnalité et les essais d'intégration dans des demandes d'extraction.

Figure 2 – Carnets de science des données
Description - Figure 2
Bureau désordonné recouvert de documents éparpillés sur sa surface, au sol et dans la corbeille à proximité. Les documents sont intitulés "Carnets de science des données".
Dans Databricks, tous les carnets se trouvant dans un dossier principal à emplacement fixe sont synchronisés pour suivre la branche principale dans un répertoire Git Azure DevOps. Avant de modifier le code de modèle, un membre de l'équipe crée une copie de ce dossier dans Databricks et une nouvelle branche correspondante dans DevOps, puis configure la synchronisation Git entre eux. Lorsque les modifications sont satisfaisantes, le membre de l'équipe consigne les carnets dans Databricks, puis crée une demande d'extraction dans DevOps.
Toute demande d'extraction comprenant des changements au code du carnet déclenche un pipeline d'intégration continue garantissant que les modifications aux carnets ne seront pas annulées. Cela commence par la copie des carnets de la branche par fonctionnalité dans un dossier d'essai d'intégration à emplacement fixe référencé par une tâche Databricks; cette tâche étant ensuite déclenchée par le pipeline au moyen de l'API Databricks.
Pour accélérer l'exécution de cet essai, un paramètre est transféré au carnet pour indiquer qu'il s'agit d'un essai et non d'une tâche d'entraînement complète. Le modèle est entraîné sur un échantillon de 5 % pour une époque, et le modèle résultant n'est pas enregistré.
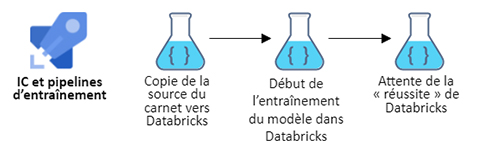
Figure 3 – IC et pipelines d'entraînement avec Databricks
Description - Figure 3
Diagramme des pipelines de IC et pipelines d'entraînement. Étape 1 : Copie de la source du carnet vers Databricks. Étape 2 : Début de l'entraînement du modèle dans Databricks. Étape 3 : Attente de la « réussite » de Databricks.
Le pipeline continue de sonder Databricks jusqu'à ce que le travail soit terminé. Si l'exécution du carnet est réussie, la fusion vers la branche principale peut se poursuivre.
Déploiement de modèle
Puisque l'équipe de SPC prévoit livrer la plupart de ses modèles dans le magasin des API du gouvernement du Canada, elle souhaite passer des carnets aux applications API REST le plus rapidement et le plus efficacement possible.
Conteneurisation du modèle
Pour des applications simples, l'API d'Azure ML peut déployer un modèle enregistré en tant qu'application conteneurisée en utilisant quelques lignes de code à la fin d'un carnet. Toutefois, cette option ne répond pas à plusieurs exigences opérationnelles telles que l'échelonnage. Plus important encore, elle n'offre pas beaucoup de souplesse pour les intrants et les extrants des modèles avant et après le processus. Nous utilisons plutôt la fonction Model.package() à partir de la trousse de développement logiciel à partir de la trousse de développement logiciel (SDK) d'Azure ML pour créer une image Docker. L'image est ensuite déployée dans un espace Kubernetes antérieurement configuré, et le point de terminaison est enregistré dans le magasin des API du gouvernement du Canada.
Par défaut, la fonction extrait la dernière version enregistrée du modèle, mais peut également utiliser les journaux d'expériences afin de sélectionner dynamiquement un modèle en fonction de n'importe quelle mesure enregistrée dans le carnet (p. ex. pour minimiser les pertes).
Pipeline de déploiement
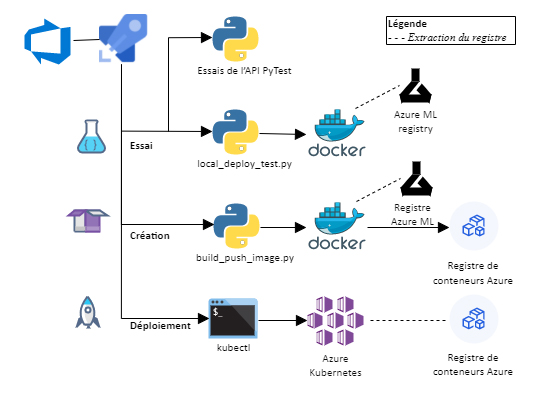
Figure 4 – Pipeline de déploiement
Description - Figure 4
Diagramme du pipeline de déploiement avec 3 étapes principales : Essai, Création et Déploiement. L'étape Essai exécute les tests de l'API PyTest et local_deploy_test.py, ce qui implique que Docker récupère un modèle dans le registre Azure ML. L'étape Création exécute build_push_image.py, qui implique également que Docker récupère un modèle dans le registre Azure ML, mais pousse également le conteneur Docker vers le registre Azure Container. L'étape Déploiement exécute l'application en ligne de commande kubectl, qui se connecte à Azure Kubernetes et récupère le conteneur dans Azure Container Registry.
Comme son nom l'indique, Azure DevOps ne se limite pas au contrôle des sources, mais peut également définir des pipelines permettant d'automatiser les tâches d'intégration et de développement continus. Les pipelines sont définis par les fichiers YAML et ont recours à des scripts Bash et Python.
Contrairement au pipeline de demande d'extraction de carnet, le pipeline de déploiement est déclenché par tout engagement envers la branche principale. Il comprend trois étapes :
- Mise à l'essai du code : À l'aide de PyTest, effectuer l'essai unitaire de l'API à l'aide d'intrants corrects et incorrects. À titre d'essai d'intégration, déployer avec Model.deploy() le service Web localement sur la machine virtuelle du bassin d'agents et exécuter des essais semblables, mais dans un contexte HTTP.
- Construction et enregistrement du conteneur Docker : Avec Model.package(), créer une image Docker en entrant un code API personnalisé. Enregistrer le conteneur dans un registre de conteneurs Azure.
- Déploiement vers Kubernetes : Avec kubectl apply, se connecter au service Azure Kubernetes, se connecter au service Azure Kubernetes configuré précédemment. Transférer un fichier manifeste pointant vers la nouvelle image dans le registre des conteneurs.
Ce processus conserve les mêmes points de terminaison d'API au moyen de redéploiements et ne perturbe pas la livraison de l'application par l'entremise du magasin des API du gouvernement du Canada.
Pipeline de réentraînement de modèle
Le pipeline de réentraînement de modèle est semblable à celui de demande d'extraction, mais exécute une tâche Databricks différente qui pointe vers le carnet de la branche principale. Le carnet journalise les mesures de session et enregistre le nouveau modèle dans Azure ML, puis déclenche le pipeline de déploiement.
L'entraînement du modèle peut nécessiter beaucoup de ressources. L'exécution du carnet en tant que tâche Databricks offre la possibilité de sélectionner un espace de calcul de haute performance (y compris les processeurs graphiques (GPU)). Les espaces sont automatiquement désassociés à la fin de la session d'entraînement.
Plutôt que d'être déclenchées par un événement particulier, les sessions du pipeline peuvent également être planifiées (consultez la page relative à la configuration de calendriers de pipelines pour obtenir de plus amples détails). Bon nombre des modèles reposent sur les données du dépôt de données d'entreprise de SPC, de sorte que l'équipe peut planifier le pipeline de réentraînement de modèle pour suivre le cycle de mise à jour du dépôt. Le modèle déployé peut ainsi toujours reposer sur les données les plus récentes.
Conclusion
Pour fournir un déroulement des opérations reproductible pour le déploiement de modèles d'AA dans le magasin des API du gouvernement du Canada, SPC a intégré plusieurs offres de SaaS Azure afin de créer une solution MLOps fonctionnelle.
- Azure DevOps : Répertoire de code source; pipelines d'IC/DC et de réentraînement;
- Azure Databricks : Développement de modèles d'AA dans des carnets; synchronisé avec le répertoire Git DevOps;
- Azure ML : Expériences de suivi et d'enregistrement de modèles; création d'images Docker;
- Service Azure Kubernetes : Service pour conteneur; vers lequel pointe le magasin des API du gouvernement du Canada.
Enfin, il convient de souligner que cette approche ne constitue qu'une des nombreuses solutions possibles. Les API Azure ML sur lesquelles la trousse de développement logiciel est basée sont en cours de développement actif et font l'objet de changements fréquents. L'équipe continue d'explorer des options en source ouverte et autohébergées. Le parcours de MLOps est loin d'être terminé, mais il est déjà bien engagé!
Si vous avez des questions au sujet de cette mise en œuvre ou si vous souhaitez simplement discuter de l'apprentissage automatique, veuillez envoyer un courriel à l'équipe de la Science des données et de l'Intelligence artificielle de SPC : ssc.dsai-sdia.spc@canada.ca.
- Date de modification :