
Tirer le maximum de la synthèse de données grâce au guide d’utilisation des données synthétiques pour les statistiques officielles
Par : Kenza Sallier et Kate Burnett-Isaacs, Statistique Canada
Introduction
Ces dernières années, tout particulièrement devant la révolution des données qui s'opère, les organismes nationaux de statistique (ONS) donnent priorité à l'accès aux données, à la transparence et à l'ouverture dans leurs initiatives de modernisation. Le pari consiste à trouver des moyens sûrs et durables d'offrir un accès plus rapide et plus facile à des données désagrégées et à jour, compilées à partir de sources d'une complexité croissante, tout en respectant les engagements pris à l'égard de la confidentialité. La synthèse de données est une technique qui permet aux utilisateurs d'accéder plus facilement à des données riches sur le plan analytique, tout en veillant au respect des impératifs en matière d'intégrité et de confidentialité. La théorie entourant la génération de données synthétiques à forte valeur analytique ne date pas d'aujourd'hui. En effet, elle a ses racines dans les méthodes d'imputation. Toutefois, pour ce qui est de la mise en œuvre, la production de fichiers de données synthétiques reste une voie nouvelle pour la plupart des ONS, surtout quand il s'agit de les produire à partir de sources de données complexes. Au vu du nombre grandissant de nouvelles méthodes et de nouveaux outils utilisés pour la production et l'évaluation d'ensembles de données synthétiques, un document d'orientation sur l'utilité et le risque s'impose. Plus précisément, pour que les données synthétiques deviennent une solution viable d'accès aux microdonnées, les ONS ont besoin d'une vue d'ensemble des méthodes et des outils existants, ainsi que de l'orientation sur la manière de mesurer la puissance analytique de ces données et leurs risques de divulgation.
Pour répondre à ce besoin, le Groupe de haut niveau sur la modernisation des statistiques officielles (GHN-MSO), un réseau relevant de la Commission économique des Nations Unies pour l'Europe (CEE-ONU), a publié le guide Synthetic Data for Official Statistics – A Starter Guide (en anglais seulement). Celui-ci offre aux organismes de statistique un bon point de départ pour apprendre et réfléchir au sujet des données synthétiques, et comprendre la manière dont elles peuvent être générées et utilisées pour partager ouvertement les données tout en protégeant leur intégrité et leur confidentialité. De plus, ce guide aide les utilisateurs à déterminer si les données synthétiques sont la bonne solution à leur problème, les oriente sur la bonne voie pour la synthèse, et fournit des méthodes d'évaluation pour résoudre les problèmes entourant la divulgation de données.
Cet article traitera des lacunes que les fichiers de données synthétiques peuvent combler, présentera des méthodes d'apprentissage profond qui peuvent être utilisées pour générer des données synthétiques, et traitera de l'importance de se fonder sur des normes claires au moment de créer et d'utiliser des données synthétiques, normes prévues dans le guide du GHN-MSO.
Que sont les données synthétiques?
Le guide du GHN-MSO définit les données synthétiques comme des données générées de manière stochastique, qui ont une valeur analytique et qui permettent des niveaux élevés de contrôle de la divulgation. Le concept de données synthétiques provient, à l'origine, du champ de la vérification et de l'imputation des données, mais le champ des données synthétiques a évolué avec le développement des méthodes informatiques et de science des données. Pour générer des données synthétiques, on utilise un processus de modélisation qui vise la préservation à la fois de la valeur analytique et de la confidentialité. La confidentialité fait référence à la divulgation injustifiée de données personnelles confiées à un ONS, qui peut survenir lorsque des renseignements statistiques sont diffusés.
De façon générale, l'objectif de la synthèse de données consiste en ce qui suit. Supposons qu'il y ait un ensemble de données, , sur lequel les utilisateurs ou les chercheurs souhaitent effectuer un ensemble d'analyses statistiques, qui aboutirait à un ensemble de conclusions statistiques . Toutefois, pour des raisons de confidentialité, on ne peut pas donner accès à aux utilisateurs. Le synthétiseur peut alors utiliser un processus de synthèse de données pour générer une version synthétique de , que nous appellerons . L'objectif de la synthèse de données est de générer de telle manière que , l'ensemble des conclusions statistiques des mêmes analyses maintenant effectuées sur , soit aussi proche que possible de .
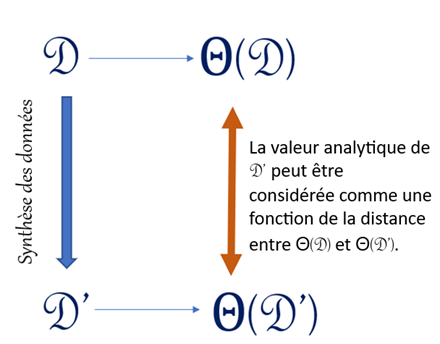
Figure 1 : Illustration de la génération de données synthétiques. Source : Sallier (2020).
Architecture de la synthèse de données. Les analyses fondées sur l'ensemble de données synthétiques fourniraient des conclusions statistiques comparables aux analyses fondées sur l'ensemble de données original.
Texte : La valeur analytique de peut être considérée comme une fonction de la distance entre et .
Pour discuter de données synthétiques, nous devons d'abord définir et comprendre l'utilité et les risques liés à la divulgation. Dans le contexte des données synthétiques, l'utilité correspond à la valeur analytique, il s'agit de l'utilité de l'ensemble de données synthétiques pour l'utilisateur. De façon générale, la valeur analytique est liée à la mesure dans laquelle les résultats de l'ensemble de données synthétiques sont proches de ceux générés à partir des données d'origine. Par conséquent, la valeur analytique de peut être considérée comme une fonction de la distance entre et .
Alors que la synthèse de données vise à accroître la valeur analytique, elle cherche aussi à réduire le plus possible le risque de divulgation. Le risque de divulgation peut être défini comme le risque d'une diffusion inappropriée de données ou de renseignements d'attribut (OCDE, 2003) et s'applique à la diffusion de toute statistique agrégée ou d'ensemble de microdonnées, y compris les données synthétiques.
Utilisations recommandées des données synthétiques
Les données synthétiques sont un outil utile pour certains problèmes ou cas d'utilisation auxquels sont confrontés les ONS. Pour chaque problème vient un équilibre nécessaire entre l'utilité et le risque de divulgation. Le guide du GDN-MSO décrit quatre catégories de cas d'utilisation :
- diffusion au public;
- mise à l'essai d'analyses;
- enseignement;
- mise à l'essai de technologies.
Diffusion au public : Ce cas d'utilisation découle généralement du désir de fournir des données utiles aux parties concernées. La principale difficulté que pose ce cas d'utilisation est que l'ONS ne sait pas la manière dont les données seront utilisées : il n'exerce aucun contrôle sur l'utilisation des données (et ignore donc quelles analyses seront effectuées) et ne sait pas par qui elles seront utilisées ou encore avec qui elles seront partagées (ce qui signifie un risque élevé de divulgation).
Analyse d'essai : La mise à l'essai de la valeur analytique est actuellement le cas d'utilisation le plus courant pour les ONS. De nombreux ONS fournissent des microdonnées confidentielles à des parties de confiance, comme des chercheurs ou des services partenaires, mais cet exercice est régi par de stricts accords d'accès aux données, ainsi que par des contrôles des antécédents et de la sécurité. Les procédures et contrôles connexes peuvent être longs et fastidieux. Les données synthétiques peuvent être une option plus efficace pour le partage de données avec des parties de confiance. Dans ce cas d'utilisation, les ONS peuvent savoir quelle analyse sera effectuée avec les données synthétiques et peuvent personnaliser le mode de génération selon l'analyse, augmentant ainsi l'utilité. Ce cas d'utilisation est souvent le plus utile pour les scientifiques des données, qui cherchent un accès plus rapide aux données d'entraînement pour leurs modèles d'apprentissage automatique.
Enseignement : Un troisième cas d'utilisation dans le contexte des ONS consiste à fournir des données de grande qualité aux étudiants, aux universitaires et aux utilisateurs en général. En particulier, la formation relative à des méthodes complexes comme l'apprentissage automatique nécessite des données qui donneront des résultats réalistes. L'équilibre entre l'utilité et le risque de divulgation dans ce cas d'utilisation est que les ONS peuvent être au courant du sujet particulier à l'étude et, ainsi, préserver les distributions spécifiques en question. Toutefois, les données synthétiques pourraient être réutilisées à différentes fins éducatives, de sorte qu'en fin de compte, l'ONS pourrait ne pas être en mesure de déterminer toutes les utilisations des données ni tous les utilisateurs.
Mise à l'essai de technologies : Des données fictives sont souvent utilisées pour faire l'essai de nouveaux logiciels et de nouvelles technologies. Toutefois, avec l'avènement de technologies plus complexes, les ONS et les intervenants cherchent des données plus réalistes afin de pouvoir évaluer et vérifier les systèmes adéquatement.
| Cas d’utilisation | Principales considérations | Équilibre entre l’utilité et la confidentialité |
|---|---|---|
| Diffusion de microdonnées au public | Le synthétiseur ne sait pas qui utilisera les donnes ou de quelle manière elles seront utilisées. | Niveaux élevés d’utilité et de confidentialité requis |
| Mise à l’essai d’analyses | Les analyses particulières ou les distributions de variables qui doivent être maintenues peuvent éventuellement être connues au moment de la synthèse. | Niveaux élevés d’utilité et de confidentialité requis |
| Enseignement | Le synthétiseur peut savoir l’analyse qui sera effectuée et les utilisateurs peuvent éventuellement avoir une autorisation de sécurité ou un accord avec l’ONS, mais peuvent aussi ne pas en avoir. | Niveau élevé d’utilité et niveau variable possible de confidentialité |
| Mise à l’essai de technologies | La valeur des données synthétiques dépend de la complexité du système et de la mesure à laquelle des données d’essai doivent être complexes. De nombreuses méthodes de génération de données synthétiques peuvent être trop lourdes sur le plan informatique pour que cet effort en vaille la peine. | Niveaux moyens d’utilité et de confidentialité |
Méthodes pour générer des données synthétiques
Il existe un nombre grandissant de méthodes pour générer des données synthétiques, et la méthode choisie dépendra du cas d'utilisation. Au moment de créer des données synthétiques, il faut tenir compte de la valeur analytique cible ainsi que du risque de divulgation pour le cas d'utilisation.
Le guide du GHN-MSO présente les méthodes couramment utilisées par les ONS aujourd'hui. Elles se répartissent en trois catégories :
- modélisation séquentielle;
- données simulées;
- méthodes d'apprentissage profond.
Toutes les méthodes sont présentées dans le guide du GHN-MSO, mais aux fins du présent article, nous nous attardons aux méthodes d'apprentissage profond mises au point récemment pour générer des données synthétiques. Les méthodes d'apprentissage profond sont de plus en plus prisées dans le domaine des données synthétiques, car les synthétiseurs sont de plus en plus nombreux à travailler avec de grands ensembles de données non structurés. À l'heure actuelle, la seule méthode d'apprentissage profond utilisée par les ONS pour générer des données synthétiques est celle des réseaux antagonistes génératifs.
Pour en apprendre davantage sur les trois catégories de méthodes de synthèse, leurs avantages et inconvénients et leur adéquation à chacun des quatre cas d'utilisation de données synthétiques pour les statistiques officielles, voir le chapitre 3 du document Synthetic Data for Official Statistics : A Starter Guide (en anglais seulement).
L'utilisation de réseaux antagonistes génératifs pour générer des données synthétiques
Un réseau antagoniste génératif (RAG) (Goodfellow et coll., 2014) est un modèle génératif utilisé pour produire des données synthétiques. Ce modèle tente d'apprendre la structure sous-jacente des données d'origine en générant de nouvelles données (de nouveaux échantillons, plus précisément) à partir de la même distribution statistique que les données d'origine, au moyen de deux réseaux neuronaux, qui se font concurrence. Comme la théorie et la mise en œuvre de processus liés à l'apprentissage profond et aux réseaux neuronaux peuvent être complexes sur le plan technique, nous nous attarderons ici aux concepts généraux (des renseignements plus détaillés peuvent être obtenus dans les publications fournies en référence). Parce que les RAG reposent sur des réseaux de neurones, l'approche peut être utilisée pour générer des données synthétiques discrètes, continues ou textuelles.
Dans un RAG, il existe deux modèles de réseau de neurones concurrents :
- le générateur prend le bruit ou les valeurs aléatoires à l'entrée et génère des échantillons;
- le discriminateur reçoit des échantillons du générateur et des données d'entraînement et tente de faire la distinction entre les deux sources.
Le discriminateur est comparable à un classificateur binaire, car il prend à la fois des données réelles (ou originales) à l'entrée, et des données générées (ou synthétiques) et calcule une valeur de pseudoprobabilité, laquelle serait comparée avec une valeur de seuil fixe pour classifier l'entrée du générateur comme générée ou réelle.
Comme le montre la figure 2, le processus d'entraînement est un processus itératif, au cours duquel les deux réseaux jouent un jeu continu où le générateur apprend à produire des échantillons plus réalistes, alors que le discriminateur apprend à mieux faire la distinction entre les données générées et les données réelles. Cette interaction entre les deux réseaux est nécessaire pour le succès de RAG, car ils apprennent tous deux au détriment de l'autre, pour finir par atteindre un équilibre.

Figure 2 : Illustration de l'entraînement d'un RAG dans le contexte de la synthèse de données. Source : Kaloskampis et coll. (2020).
Le modèle est constitué de deux réseaux : le générateur apprend à produire des échantillons plus réalistes et le discriminateur apprend à mieux classer les données générées comme étant « réelles » ou « synthétiques ». Il s'agit d'un processus itératif où les deux apprennent au détriment de l'autre, jusqu'à ce qu'un équilibre soit atteint.
Toutes les méthodes de données synthétiques ont leurs avantages et leurs considérations. Le tableau 2 présente les avantages, les inconvénients et les considérations liés à l'utilisation des RAG pour produire des données synthétiques.
| Avantages | Inconvénients |
|---|---|
|
Les réseaux antagonistes génératifs (RAG) sont utilisés par les ONS pour générer des ensembles de données continus, discrets et textuels, tout en s’assurant que la distribution et les modèles sous-jacents des données originales sont préservés. En outre, des recherches récentes ont porté sur la productionde données en texte libre, qui peuvent être pratiques dans les situations où des modèles doivent être élaborés pour classifier les données en texte libre. |
Les RAG peuvent être perçus comme étant trop complexes pour être compris, expliqués ou mis en œuvre lorsqu’il n’y a qu’une connaissance minimale des réseaux de neurones. Il y a souvent une critique associée aux réseaux de neurones comme manque de transparence. La méthode prend du temps et a une forte demande de ressources informatiques. Les RAG peuvent souffrir de l’effondrement du mode, et du manque de diversité, bien que de nouvelles variations de l’algorithme semblent corriger ces problèmes. La modélisation de données discrètes peut être difficile pour les modèles RAG. |
Autres méthodes d'apprentissage profond
D'autres méthodes de génération de données synthétiques d'apprentissage profond, dont certains ONS pourraient tirer profit, gagnent du terrain dans les milieux de la recherche et du développement.
Par exemple, les autoencodeurs sont des réseaux de neurones profonds à propagation avant utilisés pour compresser et décompresser les données d'origine. Ceci se compare quelque peu à l'enregistrement d'un fichier image à une résolution inférieure pour ensuite essayer de reconstruire l'image à haute résolution à partir de la version à résolution inférieure.
La première partie du processus est effectuée par un réseau de neurones seul, appelé l'encodeur, qui limite la quantité d'information qui voyage à travers le réseau à l'aide d'une convolution. Les autoencodeurs utilisent un deuxième réseau d'apprentissage profond, appelé le décodeur, qui tente d'inverser l'effet de l'encodeur en essayant de reconstruire l'entrée d'origine, la reconstruction étant des données synthétiques (Kaloskampis et coll., 2020). La figure 3 montre l'architecture d'un autoencodeur.
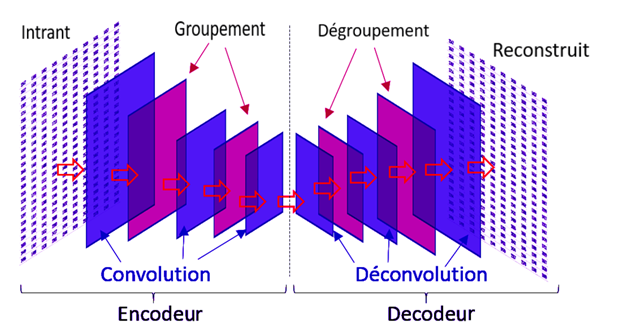
Figure 3 : Illustration de l’architecture d’un autoencodeur. Source : Kaloskampis et coll. (2020).
Les autoencodeurs utilisent des réseaux de neurones profonds pour compresser (au moyen de couches convolutionnelles et de couches agrégées), puis décompresser (au moyen de couches de déconvolution et des couches non agrégées) les données d'origine. Ceci est presque comparable à la sauvegarde d'un fichier image dans une résolution inférieure, pour ensuite essayer de reconstruire l'image à haute résolution à partir de la version à résolution inférieure.
Des modèles autorégressifs sont à l'étude pour améliorer certaines des lacunes des modèles RAG (Leduc et Grislain, 2021). Les modèles autorégressifs utilisent une variante d'une formule de régression, qui permet de prédire le point suivant d'une séquence en se basant sur des observations antérieures de cette séquence.
Entre autres méthodes, il y a la technique de suréchantillonnage synthétique des cas minoritaires, qui crée des instances de données synthétiques basées sur des instances existantes à partir des données originales (Chawla et coll., 2002). Bon nombre de ces méthodes d'apprentissage profond sont utilisées pour créer des données synthétiques différentiellement privées. Pour en savoir plus sur la confidentialité différentielle et sur les données synthétiques différentiellement privées, voir le chapitre 4 du document Synthetic Data for Official Statistics : A Starter Guide.
Avec l'amélioration de la technologie et de la capacité de calcul, la mise en œuvre des processus d'apprentissage automatique est devenue plus facile et plus accessible. Il est donc naturel que les approches d'apprentissage automatique soient de plus en plus utilisées pour générer des ensembles de données synthétiques. Plus précisément, l'utilisation de modèles d'apprentissage profond est devenue attrayante en raison de leur capacité à développer de puissants modèles prédictifs fondés sur de grands ensembles de données.
L'équilibre entre l'utilité et le risque de divulgation
Considérations liées au risque de divulgation : L'Organisation de coopération et de développement économiques définit la divulgation comme la diffusion inappropriée de données ou de renseignements sur les attributs d'une personne ou d'un organisme (OCDE, 2003). Lorsqu'il est question de risque de divulgation, il s'agit de la possibilité qu'une divulgation survienne. Le risque de divulgation s'applique à toute donnée divulguée : données agrégées, microdonnées ou données synthétiques.
Il y a deux grands types de divulgation, soit la divulgation de l'identité et celle des attributs. La divulgation de l'identité se produit lorsqu'un enregistrement dans les données diffusées est reconnu comme correspondant à une personne pour laquelle l'attaquant (quelqu'un qui cherche délibérément à divulguer ou à enfreindre les règles de confidentialité) connaît les valeurs des données diffusées d'une autre source. La divulgation d'un attribut survient quand un attaquant observe une personne dans les données qui semble être une correspondance unique avec une personne connue. Un attaquant peut utiliser les renseignements diffusés dans les données pour obtenir plus d'information sur la personne.
Bien qu'aucun enregistrement dans un fichier de données entièrement synthétique ne corresponde à une personne réelle ou à un ménage réel, dans le sens où toutes les valeurs ont été générées, on craint que l'attribut et le risque de divulgation de l'identité puissent encore être présents ainsi que le risque de divulgation perçu. Ces situations pourraient nuire à la réputation des détenteurs de données et mettre en péril la volonté des répondants de participer aux enquêtes ou aux recensements. Par conséquent, les ONS peuvent encore décider d'ajouter des couches de contrôle de la divulgation en utilisant des mesures de contrôle de la divulgation statistique plus traditionnelles en plus du processus de génération de données synthétique.
En fin de compte, il importe de préciser que les ONS devraient choisir de mettre en œuvre des méthodes supplémentaires de contrôle en ce qui concerne la divulgation de leurs données synthétiques, ainsi que des techniques spécifiques de protection de la vie privée, fondées sur leurs propres cadres législatifs et opérationnels. Le chapitre 4 du guide du GNH-MSO présente des techniques communes de protection de la vie privée et d'autres mesures de contrôle de la divulgation statistique, y compris la confidentialité différentielle.
Utilité : L'utilité, ou la valeur analytique, d'un ensemble de données synthétiques renvoie à l'utilité de l'ensemble de données pour l'objet ou le cas d'utilisation. La plupart du temps, l'utilité des données synthétiques repose sur la mesure dans laquelle les conclusions les données synthétiques et les données confidentielles originales sont similaires.
Le guide du GNH-MSO présente deux grandes catégories de mesures de l'utilité : des mesures « spécifiques » et des mesures « générales ». Les mesures spécifiques sont utiles pour évaluer l'utilité d'une analyse particulière. Quand des ajustements sont nécessaires, cependant, les mesures générales sont préférables, car elles permettent notamment de :
- comparer différentes méthodes de synthèse pour le même ensemble de données afin de générer l'ensemble de données synthétique le plus utile pour l'utilisateur;
- déterminer à quel endroit les distributions de données d'origine et de synthèse diffèrent, et ajuster les méthodes de synthèse en conséquence pour améliorer l'utilité des données synthétiques.
Le chapitre 5 du guide orientera l'utilisateur dans le choix de la mesure qui répond le mieux à votre objectif, l'aidera à évaluer les résultats. Lors de l'évaluation de données synthétiques axées sur l'utilité, il est préférable de commencer simplement. Des méthodes comme la comparaison de distributions ou la possibilité pour les données synthétiques de réaliser une tâche ciblée peuvent déterminer une utilité primaire fondamentale. Ensuite, il convient de se demander pourquoi l'on veut mesurer l'utilité. Est-ce pour comparer les méthodes de synthèse et choisir la meilleure? Est-ce pour améliorer le processus de synthèse, soit de l'ajuster? Est-ce pour évaluer la qualité du fichier synthétique en fonction de sa valeur analytique? Après avoir déterminé la raison pour laquelle on veut mesurer l'utilité, il importe de se rappeler qui est utilisateur final et quelles sont les exigences du fichier de données synthétiques final.
L'équilibre entre le risque de divulgation et l'utilité
Au moment d'évaluer la qualité des données synthétiques, nous évaluons les résultats en termes de compromis entre le risque de divulgation et l'utilité. Cette situation est souvent présentée sous forme graphique, comme le montre la figure 4.
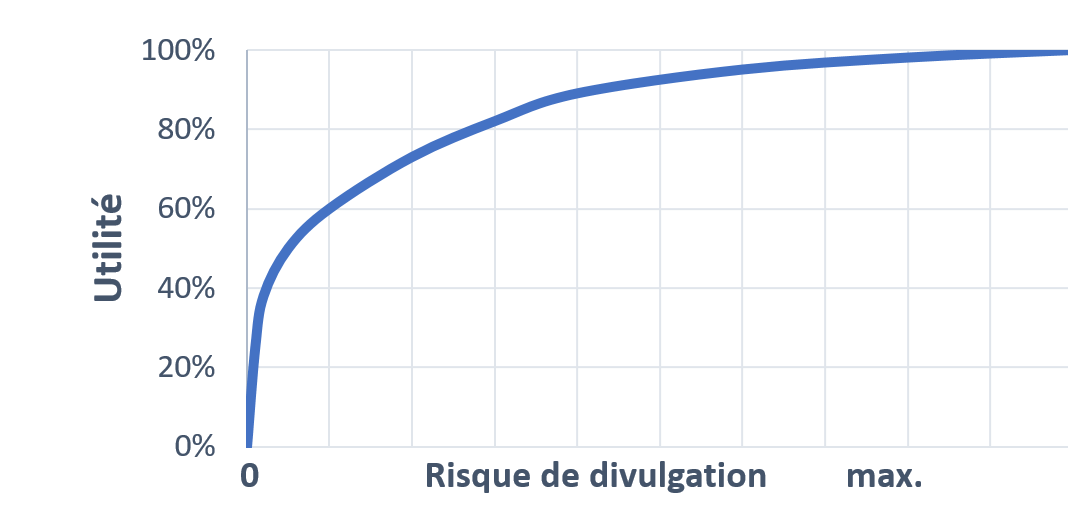
Figure 4 : Le compromis entre l'utilité et le risque de divulgation
Le graphique décrit le lien entre le risque de divulgation et l'utilité. Le risque de divulgation associé à l'ensemble de données est sur l'axe des x et l'utilité se trouve sur l'axe des y. La courbe est concave, elle augmente, reliant le coin inférieur gauche à l'angle supérieur droit. Cela signifie qu'aucun ensemble de données ne peut avoir en même temps un score élevé quant à l'utilité et un score faible quant au risque de divulgation.
Il convient de se rappeler que dans le contexte des données synthétiques, l'utilité est une mesure de la proximité des résultats des données synthétiques par rapport aux données originales. Les données dont tous les enregistrements avaient des valeurs identiques peuvent avoir une utilité de zéro, et un risque de divulgation de zéro, tandis que les données originales auront une utilité de 100 %. Le risque de divulgation des données synthétiques est maximal lorsque les données originales ne sont pas modifiées. L'emplacement idéal sur ce graphique est en haut à gauche, avec une utilité parfaite et aucun risque de divulgation. Toutefois, ce point n'est jamais atteignable, car la modification des données en vue de leur protection contre les risques de divulgation modifiera toujours leur valeur. Plus important encore, quand on produit et évalue des données synthétiques, il faut toujours tenir compte à la fois de l'utilité et des risques de divulgation.
Conclusion
Le guide Synthetic Data for Official Statistics: A Starter Guide est le fruit d'une collaboration internationale entre des spécialistes des données synthétiques. Il fournit des recommandations sur le moment et la manière d'utiliser, de générer et de valider des données synthétiques dans le contexte des statistiques officielles. Il offre aussi des recommandations et de l'information pertinente sur la manière dont les données synthétiques peuvent accroître la portée et la valeur des fonds de données des ONS.
Bien que les données synthétiques ne puissent pas résoudre tous les problèmes de divulgation auxquels sont confrontés les organismes statistiques, elles peuvent offrir la solution pour étendre l'utilisation des données au grand public, au milieu universitaire, aux parties concernées et même à notre propre personnel. Avec l'avènement de méthodes d'apprentissage profond, les ONS disposent maintenant d'outils pour créer des données synthétiques à partir de grands ensembles de données non structurés. Quelle que soit la manière dont vous générez vos données synthétiques, il est essentiel d'établir un équilibre entre l'utilité des données de sortie et les risques de divulgation. Ne manquez pas de lire le document Synthetic Data for Official Statistics : A Starter Guide pour orienter votre projet de données synthétiques.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 16 mars
De 14 00 h à 15 30 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
Références
Chawla, N. V., K. W. Bowyer, L. O. Hall et W. P. Kegelmeyer. 2002. « SMOTE: Synthetic Minority Over-sampling Technique », Journal of Artificial Intelligence Research, vol. 16, p. 321 à 357.
Goodfellow, I., J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville et Y. Bengio. 2014. « Generative Adversarial Networks », Advances in Neural Information Processing Systems, vol. 3. 10.1145/3422622.
Kaloskampis, I., C. Joshi, C. Cheung, D. Pugh. et L. Nolan. 2020. « Synthetic data in the civil service », Significance, vol. 17, p. 18 à 23. (en anglais seulement)
Leduc, J. et N. Grislain. 2021. Composable Generative Models, arXiv: 2102.09249v1. (en anglais seulement)
OCDE. 2003. Glossaire de termes statistiques de l’OCDE, consulté le 21 août 2022 sur le site.
Sallier, K. 2020. « Toward More User-centric Data Access Solutions: Producing Synthetic Data of High Analytical Value by Data Synthesis », Statistical Journal of the IAOS, vol. 36, no 4, pp. 1059-1066. (en anglais seulement)
- Date de modification :