
Conception d'un système d'alerte et de surveillance des mesures
Par : Simardeep Singh, Statistique Canada
Introduction
La conception d'un système d'alerte et de surveillance des mesures est une étape cruciale pour assurer la santé et le rendement de tout système ou de toute application. Un système bien conçu peut aider à repérer les problèmes potentiels avant qu'ils ne deviennent très importants, ce qui permet leur résolution rapide et réduit au minimum le temps d'arrêt.
La première étape de conception d'un système d'alerte et de surveillance des mesures consiste à déterminer les principales mesures qui doivent faire l'objet d'une surveillance. Ces mesures doivent être choisies en fonction des buts et objectifs précis du système ou de l'application ainsi que de ses caractéristiques et de ses exigences uniques. Par exemple, un site Web peut devoir surveiller des mesures comme le temps de chargement des pages, la mobilisation des utilisateurs et le temps de réponse des serveurs, tandis qu'une application mobile peut devoir surveiller des mesures comme l'utilisation de la batterie et le rendement du réseau.
Une fois les principales mesures cernées, la prochaine étape consiste à déterminer la façon dont elles seront recueillies et stockées. Cela peut comprendre la mise en place d'outils de surveillance spécialisés ou l'utilisation d'outils et de services existants. Il est important de s'assurer que les données recueillies sont exactes, fiables et facilement accessibles.
La prochaine étape consiste à établir des alertes et des avis en fonction des mesures qui font l'objet d'une surveillance. Cela peut se faire au moyen de divers outils et méthodes, comme les courriels, les messages textes ou les notifications poussées. Les seuils d'alerte doivent être choisis avec soin afin de s'assurer qu'ils sont suffisamment sensibles pour détecter les problèmes potentiels, mais pas au point de générer des alertes erronées.
Enfin, il est important d'examiner et d'évaluer régulièrement le rendement du système d'alerte et de surveillance des mesures. Il peut s'agir d'analyser les données recueillies, de déterminer les points à améliorer et d'apporter les ajustements nécessaires au système. En améliorant continuellement le système, il peut demeurer efficace et fiable au fil du temps.
Quels sont les principaux éléments du système?
Un système d'alerte et de surveillance des mesures comprend cinq composantes :
- Collecte de données : Sert à recueillir les données relatives aux mesures à partir de différentes sources.
- Transmission des données : Sert à transférer les données depuis les sources vers le système de surveillance des mesures.
- Stockage des données : Sert à organiser et à stocker les données entrantes.
- Alerte : Sert à analyser les données entrantes, à détecter les anomalies et à générer des alertes. Le système doit pouvoir envoyer des alertes à différents canaux de communication configurés par l'organisation.
- Visualisation : Sert à présenter les données sous forme de tableaux, de graphiques ou sous d'autres formes, car il est plus facile de cerner les tendances ou les problèmes lorsque les données sont présentées visuellement.
Façon de concevoir les mesures pour le système d'alerte et de surveillance des mesures
Nous examinerons dans la section qui suit certains principes fondamentaux de conception du système, du modèle de données et de la conception globale.
Modélisation de données : Les données relatives aux mesures sont généralement enregistrées sous la forme d'une série chronologique qui contient l'ensemble de valeurs et les estampilles temporelles connexes. La série elle-même peut être désignée par son nom et, sur le plan opérationnel, par un ensemble d'étiquettes. Chaque série chronologique comprend les éléments suivants :
Tableau 1 : Séries temporelles
| Nom | Type |
|---|---|
| Un nom de mesure | Une chaîne |
| Un ensemble d’étiquettes | Une liste des paires <key : value> |
| Un ensemble de valeurs et leurs estampilles temporelles | Une matrice de paires <value, timestamp> |
Modèle d'accès aux données : Envisager une mise en situation réelle où le système d'alerte doit calculer la charge moyenne de l'unité centrale sur l'ensemble des serveurs Web dans une région précise. La moyenne des données doit être calculée toutes les 10 minutes, ce qui représente environ 10 millions de mesures opérationnelles écrites par jour, et de nombreuses mesures sont recueillies à fréquence élevée. Pour ces systèmes, la charge d'écriture est lourde et la charge de lecture est simultanément irrégulière. Les services de visualisation et d'alerte envoient les requêtes à la base de données et, selon les tendances d'accès et les alertes, le volume de lecture peut augmenter ou diminuer. Le système est soumis à une charge d'écriture constante et lourde, tandis que la charge de lecture est irrégulière.
Système de stockage de données : Une base de données à usage général, en théorie, pourrait prendre en charge les données chronologiques, mais elle nécessitera des ajustements importants pour qu'elle fonctionne à grande échelle. Une base de données relationnelle n'est pas optimisée pour les opérations couramment effectuées sur des données chronologiques.
De nombreux systèmes de stockage sont optimisés pour les données chronologiques. L'optimisation s'appuie sur un moins grand nombre de serveurs pour traiter d'énormes quantités de données. Bon nombre de ces bases de données ont des interfaces de requête sur mesure conçues pour l'analyse de données chronologiques qui sont beaucoup plus faciles à utiliser que le langage relationnel SQL.
Deux bases de données chronologiques très populaires, Influx DB (base de données) et Prometheus, ont été conçues pour stocker de grandes quantités de données chronologiques et effectuer des analyses en temps réel. Une autre caractéristique de la robuste base de données chronologiques est l'agrégation efficace. La base de données Influx DB crée des index sur les étiquettes pour faciliter la consultation rapide de séries chronologiques par étiquettes.
Conception globale
Figure 1 : Conception globale d'un système d'alerte et de surveillance des mesures

Figure 1 : Conception globale d'un système d'alerte et de surveillance des mesures
Différentes composantes du système d'alerte et de surveillance des mesures interagissent entre elles. La source des mesures génère les mesures qui sont recueillies par le système de collecte des mesures et qui sont transmises à la base de données de séries chronologiques. La base de données de séries chronologiques est interrogée par le système de visualisation pour afficher les éléments visuels et le système d'alerte pour aviser les développeurs.
- Source des mesures
- Envoi au Système de collecte des mesures
- Système de collecte des mesures
- Envoi au Bases de données chronologiques
- Bases de données chronologiques
- Retour au Source des mesures
- Retour au Services de requêtes
- Services de requêtes
- Retour au Système d’alerte (envoi de requêtes)
- Retour au Système de visualisation (envoi de requêtes)
- Système de visualisation
- Envoi au Services de requêtes
- Système d’alerte
- Envoi au Courriel
- Envoi au Message texte
- Envoi au PagerDuty
- Envoi au Points terminaux HTTPS
- Courriel
- Message texte
- PagerDuty
- Points terminaux HTTPS
- Source des mesures :Il peut s'agir de serveurs d'applications, de bases de données SQL, de files d'attente de messages, etc.
- Système de collecte des mesures : Recueille les données relatives aux mesures et les consignes dans la base de données chronologiques.
- Base de données chronologiques : Sert à stocker les données relatives aux mesures sous forme de séries chronologiques. La base de données fournit habituellement une interface de requête personnalisée pour analyser et résumer une grande quantité de données chronologiques. Elle maintient des index sur les étiquettes pour faciliter la consultation rapide des données à l'aide des étiquettes.
- Service de requêtes : Le service de requêtes facilite la recherche et l'extraction de données à partir des bases de données chronologiques.
- Système d'alerte : Envoie des notifications d'alerte à diverses destinations d'alerte.
- Système de visualisation : Les mesures sont présentées sous diverses formes de graphiques et de tableaux.
Conception en détail
Regardons les conceptions d'un peu plus près :
- Collecte des mesures
- Ajustement du pipeline de transmission de mesures
- Service de requêtes
- Système d'alerte
- Système de visualisation
Collecte des mesures
Il y a deux façons de recueillir les données relatives aux mesures : par extraction ou par diffusion.
Figure 2 : Processus de collecte des mesures
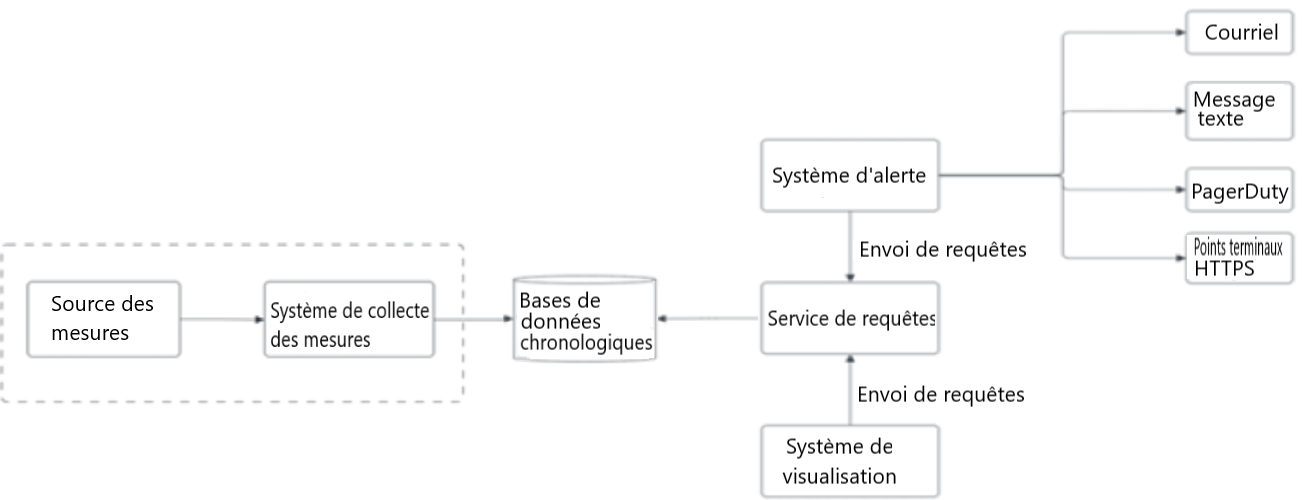
Figure 2 : Processus de collecte des mesures
La source des mesures et le système de collecte des mesures. Ces composantes sont décrites en détail dans les paragraphes suivants.
- Source des mesures
- Envoi au Système de collecte des mesures
- Système de collecte des mesures
- Envoi au Bases de données chronologiques
- Bases de données chronologiques
- Retour au Source des mesures
- Retour au Services de requêtes
- Services de requêtes
- Retour au Système d’alerte (envoi de requêtes)
- Retour au Système de visualisation (envoi de requêtes)
- Système de visualisation
- Envoi au Services de requêtes
- Système d’alerte
- Envoi au Courriel
- Envoi au Message texte
- Envoi au PagerDuty
- Envoi au Points terminaux HTTPS
- Courriel
- Message texte
- PagerDuty
- Points terminaux HTTPS
Modèle de collecte par extraction
Dans un modèle de collecte par extraction, le système de collecte des mesures extrait les mesures à partir des sources. Par conséquent, le système de collecte des mesures doit connaître la liste complète des points terminaux de services pour extraire les données. Nous pouvons utiliser un service fiable, évolutif et maintenable, comme la découverte de services fournie par ETCD et Zookeeper. Un module de découverte de services contient des règles de configuration concernant le moment et l'endroit où recueillir les mesures.
- Le système de collecte des mesures récupère les métadonnées de configuration du point terminal de service à partir du module de découverte de services. Les métadonnées comprennent l'intervalle d'extraction, les adresses IP, les délais d'expiration ainsi que les paramètres de reprise.
- Le système de collecte des mesures extrait les données relatives aux mesures au moyen du point terminal HTTP (par exemple, les serveurs Web) ou du point terminal TCP (protocole de contrôle de transmission) (pour les groupements de bases de données).
- Le système de collecte des mesures enregistre une notification d'événement de changement dans le répertoire de services pour obtenir une mise à jour chaque fois que les points terminaux de services changent.
Figure 3 : Modèle détaillé de collecte par extraction
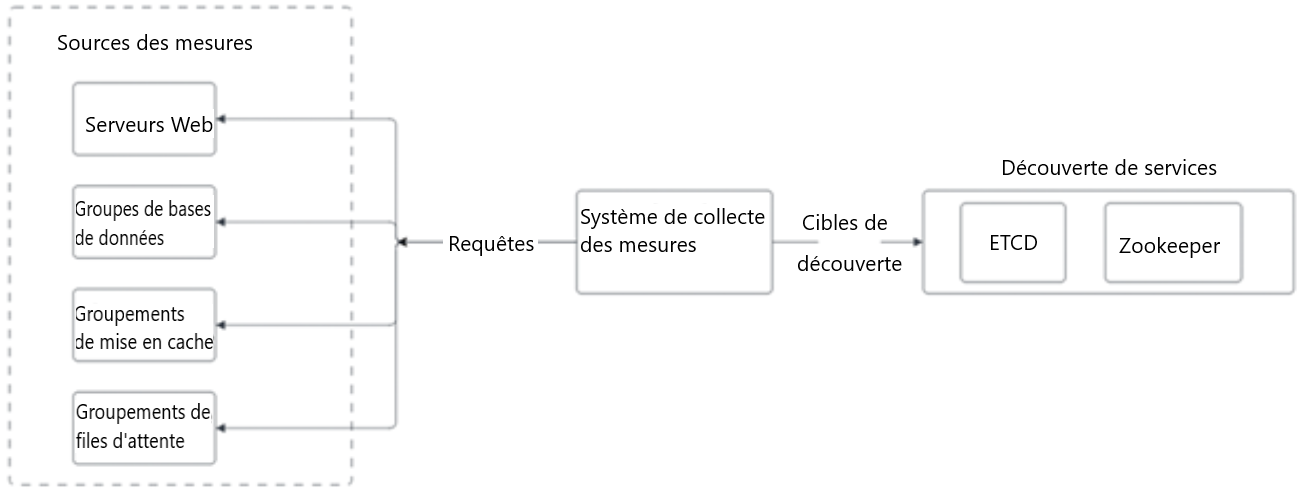
Figure 3 : Modèle détaillé de collecte par extraction
Le système de collecte des mesures extrait les mesures à partir de différentes sources. Les services de collecte des mesures obtiennent les renseignements des points terminaux de services à partir du répertoire de services qui comprend ETCD et Zookeeper.
- Système de collecte des mesures
- Envoi au Découverte de services – ETCD, Zookeeper (via Cibles de découverte)
- Envoi au Sources des mesures - Serveurs Web, Groupe de bases de données, Groupements de mise en cache, Groupements de files d’attente (via Requêtes)
- Découverte de services – ETCD, Zookeeper
- Sources des mesures – Serveurs Web, Groupe de bases de données, Groupements de mise en cache, Groupements de files d’attente
Modèle de collecte par diffusion
Dans un modèle de collecte par diffusion, un module de collecte est installé sur chaque serveur qui fait l'objet d'une surveillance. Un module de collecte est un logiciel de longue durée qui recueille les mesures à partir du service exécuté sur le serveur, et qui les transmet au système de collecte.
Pour éviter que le système de collecte des mesures ne prenne du retard dans un modèle de collecte par diffusion, le système de collecte doit toujours être en mode de mise à l'échelle automatique à l'aide d'un équilibreur de charge en première ligne (Figure 4). Le groupement de services doit être augmenté ou réduit en fonction de la charge de l'UCT (unité centrale de traitement) du système de collecte des mesures.
Figure 4 : Modèle détaillé de la collecte par diffusion
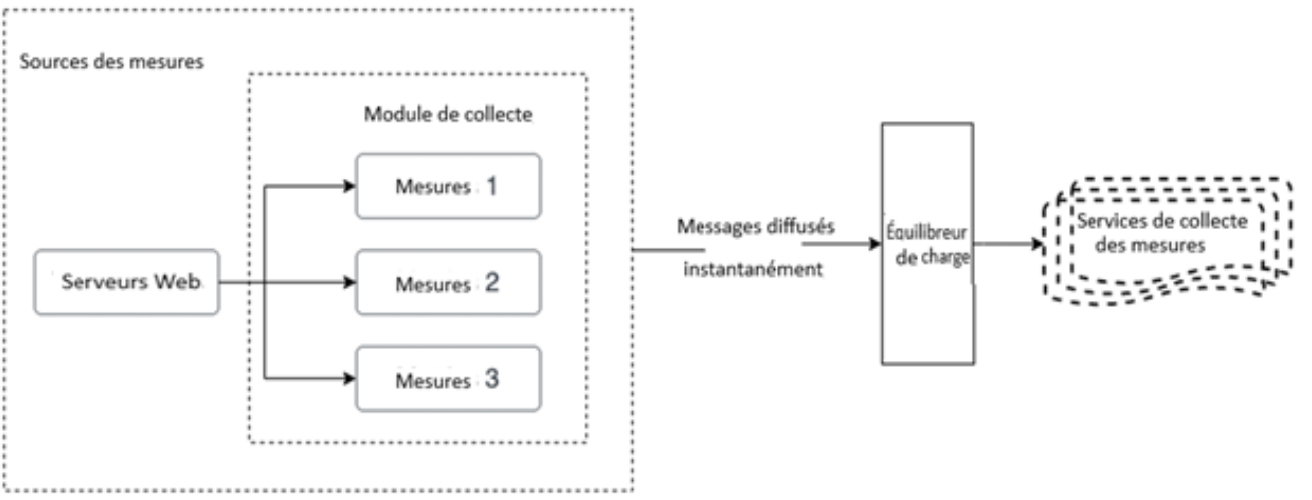
Figure 4 : Modèle détaillé de la collecte par diffusion
Le module de collecte recueille les mesures à partir des serveurs Web et les diffuse à un équilibreur de charge. L'équilibreur de charge équilibre la charge des mesures et les diffuse vers le groupement de services de collecte des mesures.
- Sources des mesures
- Serveurs Web
- Envoi au Mesures 1
- Envoi au Mesures 2
- Envoi au Mesures 3
- Envoi à l’Équilibreur de charge
- Serveurs Web
- Équilibreur de charge (via Messages diffuses instantanément)
- Envoi au Services de collecte des mesures
- Services de collecte des mesures
Quel modèle de collecte est préférable? Par extraction ou par diffusion
Alors, qu'est-ce qui est le mieux pour une grande organisation? Il est important de connaître les avantages et les inconvénients liés à chacune des approches. Une grande organisation doit prendre en charge les deux, en particulier dans le cas d'une architecture sans serveur.
Système de surveillance par diffusion :
Avantages :
- Notifications en temps réel des problèmes et des alertes.
- Peut alerter plusieurs destinataires en même temps.
- Peut être personnalisé en fonction d'exigences et de besoins précis.
- Peut être intégré à d'autres systèmes et applications.
Inconvénients :
- Nécessite une connexion Internet constante et fiable pour fonctionner correctement.
- Le nombre de notifications et d'alertes peut devenir trop lourd.
- Peut être vulnérable aux cyberattaques et aux atteintes à la sécurité.
Système de surveillance par extraction :
Avantages :
- Accessible à distance et à partir de plusieurs appareils.
- Peut être configuré pour vérifier des mesures et des paramètres précis à intervalles réguliers.
- Peut être facilement configuré et personnalisé.
- Peut fournir des données détaillées et historiques aux fins d'analyse et de production de rapports.
Inconvénients :
- Nécessite une intervention manuelle pour vérifier et examiner les données.
- Peut ne pas fournir d'alertes et de notifications en temps réel.
- Peut être moins efficace pour cerner les problèmes et les anomalies et y remédier.
Ajustement du pipeline de transmission de mesures
Que nous utilisions le modèle de collecte par diffusion ou par extraction, le système de collecte des mesures des serveurs et le regroupement de services reçoivent d'énormes quantités de données. Il y a un risque de perte de données si la base de données chronologiques n'est pas disponible. Pour gérer le risque de perte de données, nous pouvons utiliser un composant de mise en file d'attente, comme le montre la figure 5.
Figure 5 : Ajouter des files d'attente
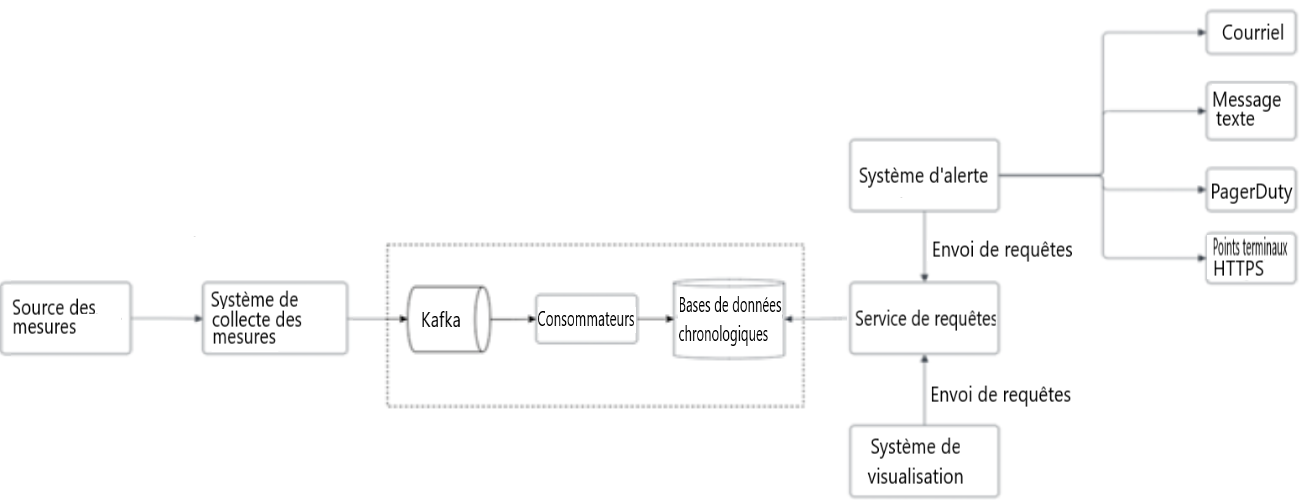
Figure 5 : Ajouter des files d'attente
Étapes pour ajuster le pipeline de transmission des mesures. La conception tire parti de l'utilisation du mécanisme de partition intégrée de Kafka pour ajuster le système. Kafka aide à catégoriser les mesures et à établir leur ordre de priorité afin que les mesures importantes soient traitées en premier par la base de données chronologiques.
- Source des mesures
- Envoi au Système de collecte des mesures
- Système de collecte des mesures
- Envoi au Kakfa
- Kafka
- Envoi au Consommateur
- Consommateur
- Envoi au Bases de données chronologiques
- Bases de données chronologiques
- Retour au Services de requêtes
- Services de requêtes
- Retour au Système d'alerte (envoi de requêtes)
- Retour au Système de visualisation (envoi de requêtes)
- Système de visualisation
- Envoi au Services de requêtes
- Système d’alerte
- Envoi au Courriel
- Envoi au Message texte
- Envoi au PagerDuty
- Envoi au Points terminaux HTTPS
- Courriel
- Message texte
- PagerDuty
- Points terminaux HTTPS
Dans cette conception, le système de collecte des mesures envoie des données relatives aux mesures à un système de file d'attente comme Kafka. Ensuite, les consommateurs ou les services de traitement en continu comme Apache Spark traitent les données et les diffusent vers la base de données chronologiques. Cette approche présente plusieurs avantages :
- Kafka est une plateforme de diffusion de messagerie hautement fiable et évolutive.
- L'application dissocie les services de collecte et de traitement des données les uns des autres.
- Elle peut facilement prévenir la perte de données lorsque la base de données n'est pas disponible en conservant les données dans Kafka.
Service de requêtes
Le service de requêtes est constitué d'un groupement de serveurs de requêtes qui accèdent à la base de données chronologiques et traitent les requêtes provenant des systèmes de visualisation ou d'alerte. Une fois qu'un ensemble dédié de serveurs de requêtes est en place, il est possible de dissocier la base de données chronologiques des systèmes de visualisation et d'alerte. Cela permet la modification de la base de données chronologiques ou des systèmes de visualisation et d'alerte, au besoin.
Pour réduire la charge de la base de données chronologiques et rendre le service de requêtes plus performant, des serveurs cache peuvent être ajoutés pour stocker les résultats de la requête, comme le montre la figure 6.
Figure 6 : Couche de mise en cache
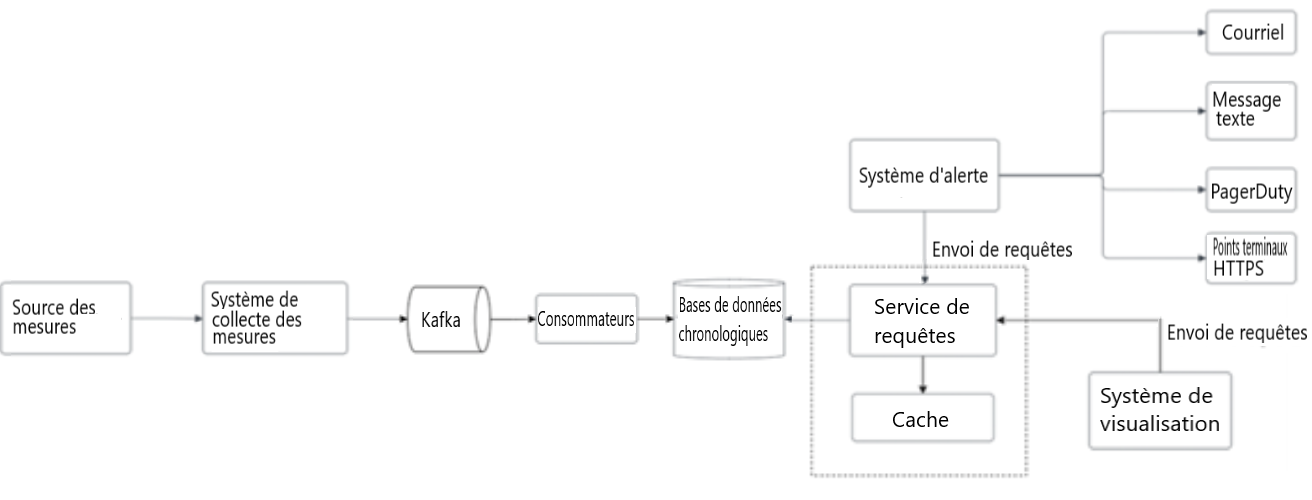
Figure 6 : Couche de mise en cache
L'intégration du service de requêtes et de la couche de mise en cache. La couche de mise en cache réduit le temps de chargement de la base de données chronologiques et rend la requête plus performante.
- Source des mesures
- Envoi au Système de collecte des mesures
- Système de collecte des mesures
- Envoi au Kakfa
- Kafka
- Envoi au Consommateur
- Consommateurs
- Envoi au Bases de données chronologiques
- Bases de données chronologiques
- Retour au Services de requêtes
- Services de requêtes
- Envoi au Cache
- Retour au Système d'alerte (Envoi de requêtes)
- Retour au Système de visualisation (Envoi de requêtes)
- Cache
- Système de visualisation
- Envoi au Services de requêtes
- Système d'alerte
- Envoi au Courriel
- Envoi au Message texte
- Envoi au PagerDuty
- Envoi au Points terminaux HTTPS
- Courriel
- Message texte
- PagerDuty
- Points terminaux HTTPS
Couche de stockage
Optimisation de l'espace – afin d'optimiser le stockage, les stratégies suivantes peuvent être utilisées pour résoudre ce problème :
Codage et compression des données : Le codage des données est le processus de traduction des données d'un format à un autre, habituellement à des fins de transmission ou de stockage efficace. La compression des données est un processus connexe qui consiste à réduire la quantité de données requises pour représenter un élément d'information donné. Le codage et la compression des données peuvent réduire considérablement la taille des données. Il s'agit du processus de codage, de restructuration ou de modification des données pour en réduire la taille. Essentiellement, il s'agit de recodage de l'information en utilisant moins d'octets que la représentation originale.
Sous-échantillonnage : Le sous-échantillonnage est le processus qui consiste à réduire le nombre d'échantillons dans un ensemble de données en supprimant certains points de données. Le processus est souvent utilisé pour réduire la quantité de données qui doivent être traitées et pour simplifier l'analyse. Le sous-échantillonnage peut être effectué de diverses façons, notamment par la sélection aléatoire d'un sous-ensemble de points de données, l'utilisation d'un algorithme particulier pour sélectionner les points de données ou l'utilisation d'une fréquence d'échantillonnage précise pour réduire les données. Si la politique de conservation des données est établie à un an, il est possible d'échantillonner les données de la façon suivante.
- Conservation : sept jours, pas d'échantillonnage
- Conservation : 30 jours, sous-échantillonnage jusqu'à une résolution d'une minute
- Rétention : un an, sous-échantillonnage à une résolution d'une heure
Système d'alerte
Bien qu'un système de surveillance soit très utile pour l'interprétation et l'examen proactifs, l'un des principaux avantages d'un système de surveillance complet est que les administrateurs peuvent être déconnectés du système. Les alertes permettent de définir des situations à gérer activement tout en s'appuyant sur la surveillance passive des logiciels pour surveiller l'évolution des conditions.
Le flux d'alerte fonctionne comme suit :
- Charger les fichiers de configuration sur les serveurs cache. Les règles sont définies comme des fichiers de configuration sur le disque, comme l'indique la figure 7.
Figure 7 : Système d'alerte
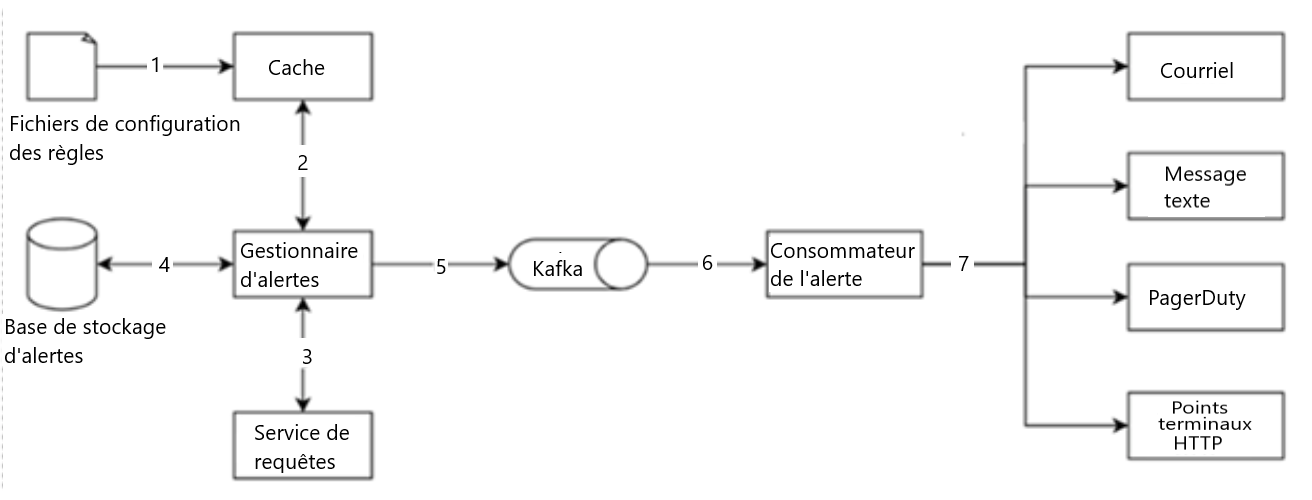
Figure 7 : Système d'alerte
Les fichiers de configuration bruts sont mis en cache et transmis au gestionnaire d'alertes. Le gestionnaire d'alertes transmet ces fichiers à Kafka qui sont ensuite utilisés par les consommateurs d'alertes, y compris les courriels, les messages textes, PagerDuty et les points terminaux HTTP.
- Fichiers de configutation des règles
- Envoi au Cache
- Cache
- Envoi au Gestionnaire d’alertes
- Gestionnaire d’alertes
- Retour au Cache
- Envoi au Service de requêtes
- Lateral au Consommateur de l’alerte
- Envoi au Kafka
- Service de requêtes
- Retour au Consommateur de l’alerte
- Consommateur de l’alerte
- Retour au Gestionnaire d’alertes
- Kafka
- Envoi au Consommateur de l’alerte
- Consommateur de l’alerte
- Envoi au Courriel
- Envoi au Message texte
- Envoi au PagerDuty
- Envoi au Points terminaux HTTPS
- Courriel
- Message texte
- PagerDuty
- Points terminaux HTTPS
- Le gestionnaire d'alertes récupère les configurations relatives aux alertes à partir du cache.
- Sur la base des règles de configuration, le gestionnaire d'alertes appelle le service de requêtes à un intervalle prédéfini. Si la valeur dépasse le seuil, un événement d'alerte est créé. Le gestionnaire d'alertes a les responsabilités suivantes :
- Filtrer et fusionner les alertes, et éliminer les dédoublements. Voici un exemple d'alertes fusionnées qui sont signalées en une seule alerte dans un court délai.
Figure 8 : Alertes fusionnées
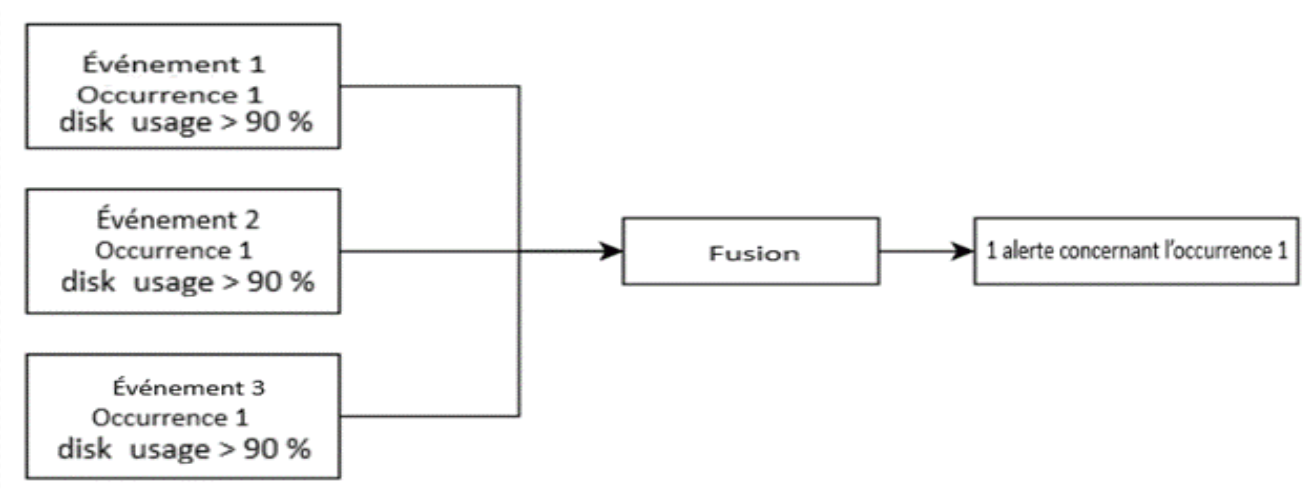
Figure 8 : Alertes fusionnées
Fusion d'alertes par rapport aux différents événements.
- Événement 1, Occurence 1, disk usage > 90%
- Envoi au Fusion
- Événement 2, Occurence 1, disk usage > 90%
- Envoi au Fusion
- Événement 3, Occurence 1, disk usage > 90%
- Envoi au Fusion
- Fusion
- Envoi à l'1 alerte concernant l’occurrence 1
- 1 alerte concernant l'occurrence 1
- Contrôle de l'accès – pour éviter les erreurs humaines et assurer la sécurité du système, il est essentiel de limiter l'accès à certaines opérations de gestion des alertes aux personnes autorisées seulement.
- Réessayer – le gestionnaire d'alertes vérifie les états d'alerte et s'assure qu'une notification est envoyée au moins une fois.
- La base de stockage d'alertes est une base de données ayant une valeur essentielle comme Cassandra qui maintient l'état de toutes les alertes (active, en attente, déclenchée, résolue). Cela permet de s'assurer qu'une notification est envoyée au moins une fois.
- Les alertes admissibles sont insérées dans un système de messagerie et de mise en file d'attente comme Kafka.
- Les consommateurs d'alertes extraient les événements d'alerte à partir du système de messagerie et de mise en file d'attente.
- Les consommateurs d'alertes traitent les événements d'alerte à partir du système de messagerie et de mise en file d'attente, et envoient des notifications par différents canaux, comme le courrier électronique, la messagerie texte, PagerDuty ou les points terminaux HTTP.
Système de visualisation
Le système de visualisation est créé au-dessus la couche de données. Les mesures peuvent être présentées dans le tableau de bord des mesures sur diverses échelles de temps, et les alertes peuvent être affichées dans le tableau de bord. Un système de visualisation de haute qualité est difficile à concevoir. Il y a de bons arguments en faveur d'un système standard. Par exemple, Grafana peut être un très bon système à cette fin.
Récapitulation
Dans le présent article, nous avons discuté de la conception d'un système d'alerte et de surveillance des mesures. De façon générale, nous avons parlé de la collecte de données, de la base de données chronologiques, des alertes et de la visualisation. Nous nous sommes également penchés sur certaines des techniques et des composantes importantes, notamment :
- Le modèle de collecte par extraction ou par diffusion pour les données relatives aux mesures.
- L'utilisation de Kafka pour ajuster le système.
- Le choix de la bonne base de données chronologiques.
- Le recours au sous-échantillonnage pour réduire la taille des données.
- Les options de conception ou d'achat en ce qui a trait aux systèmes d'alerte et de visualisation.
Nous avons procédé à quelques itérations pour affiner le diagramme, et notre conception finale ressemble à ceci :
Figure 9 : Conception finale
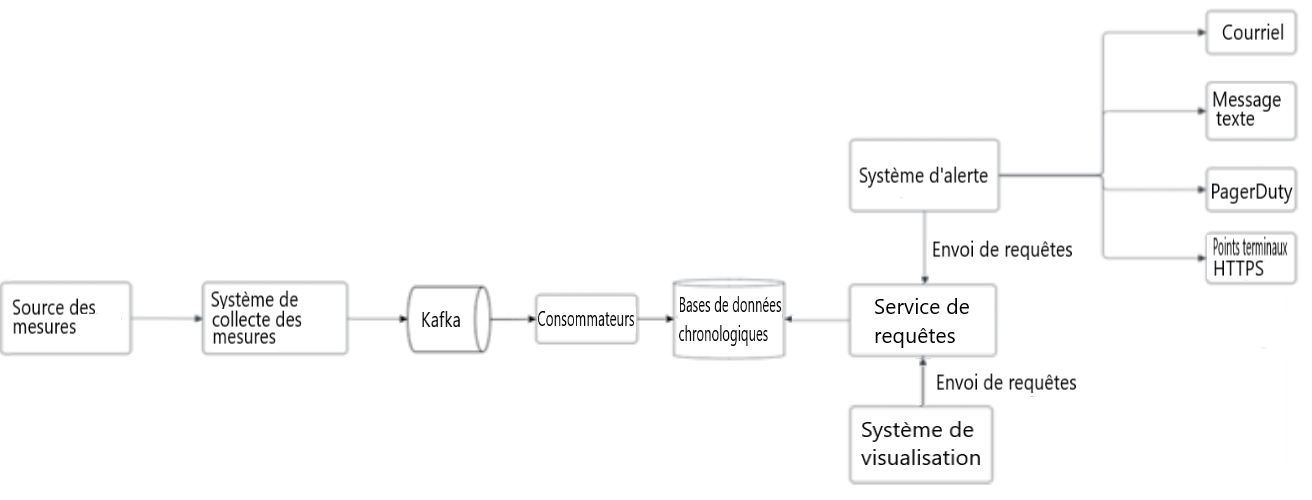
Figure 9 : Conception finale
Conception affinée du système d'alerte et de surveillance des mesures
- Source des mesures
- Envoi au Système de collecte des mesures
- Système de collecte des mesures
- Envoi au Kakfa
- Kafka
- Envoi au Consommateur
- Consommateur
- Envoi au Bases de données chronologiques
- Bases de données chronologiques
- Retour au Services de requêtes
- Services de requêtes
- Retour au Système d'alerte (Envoi de requêtes)
- Retour au Système de visualisation (Envoi de requêtes)
- Système de visualisation
- Envoi au Services de requêtes
- Système d’alerte
- Envoi au Courriel
- Envoi au Message texte
- Envoi au PagerDuty
- Envoi au Points terminaux HTTPS
- Courriel
- Message texte
- PagerDuty
- Points terminaux HTTPS
En conclusion, la conception d'un système d'alerte et de surveillance des mesures est une étape cruciale pour assurer la santé et le rendement de tout système ou application. En sélectionnant soigneusement les mesures clés pour la surveillance, la collecte et le stockage des données avec exactitude, en établissant des alertes et des notifications efficaces et en examinant et en améliorant régulièrement le système, il est possible de créer un système robuste et fiable qui peut aider à cerner et à résoudre les problèmes potentiels avant qu'ils ne deviennent critiques.
Rencontre avec le scientifique des données

Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 16 février
De 14 00 h à 15 00 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Inscrivez-vous à la présentation Rencontre avec le scientifique des données.
À bientôt!
Abonnez-vous au bulletin d'information du Réseau de la science des données pour la fonction publique fédérale pour rester au fait des dernières nouvelles de la science des données.
Ressources additionnelles
- Datadog (en anglais seulement)
- Splunk (en anglais seulement)
- PagerDuty (en anglais seulement)
- Elastic stack (en anglais seulement)
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure (en anglais seulement)
- Distributed Systems Tracing with Zipkin (en anglais seulement)
- Prometheus (en anglais seulement)
- OpenTSDB-A Distributed, Scalable Monitoring System (en anglais seulement)
- Data model (en anglais seulement)
- MySQL (en anglais seulement)
- Schema design for time-series data | Cloud Bigtable Documentation (en anglais seulement)
- MetricsDB (en anglais seulement)
- Amazon Timestream (en anglais seulement)
- DB-Engines Ranking of time-series DBMS (en anglais seulement)
- InfluxDB (en anglais seulement)
- etcd (en anglais seulement)
- Service Discovery with Zookeeper (en anglais seulement)
- Amazon CloudWatch (en anglais seulement)
- Graphite (en anglais seulement)
- Push vs. Pull (en anglais seulement)
- Pull doesn't scale or does it? (en anglais seulement)
- Monitoring Architecture (en anglais seulement)
- Push vs. Pull in Monitoring Systems (en anglais seulement)
- Date de modification :