
Responsible use of machine learning at Statistics Canada
By: Keven Bosa, Statistics Canada
More and more data are being generated on a daily basis. We need only think of data from cellphones, satellite imagery, web browsing or optical readers. The profusion of data is increasing the public's appetite for new, more detailed and timely statistics. Like many other national statistical organizations, Statistics Canada has embraced this new reality and is using more and more alternative data sources to improve and modernize its different statistical programs. Given their volume and speed, machine learning methods are often required to use these new data sources.
Statistics Canada has conducted many projects using machine learning methods over the past three years. For example, data scientists used natural language processing to assign a class to comments from respondents to the census and other surveys. Unsupervised learning methods were used to partition the Canadian Coroner and Medical Examiner Database into homogeneous groups to improve understanding of certain events. A supervised learning algorithm was developed to predict crop yield. Projects using neural networks on satellite images are currently underway to optimize the Agriculture Program. In one project, the goal is to detect the presence of greenhouses, while the other project aims to identify different types of field crops. An algorithm was also developed to extract financial information from PDF documents. The examples above give an idea of the variety of issues for which machine learning is used.
The use of machine learning has its benefits: the ability to process large amounts of unstructured data, automating existing processes, improved coverage and accuracy, and many more. However, it also raises several questions such as:
- Does the process protect data integrity and confidentiality?
- Is the quality of the training data adequate for the desired objective?
- Once the algorithm is in place, who is responsible for the results and their effects?
Following these questions and the increased use of machine learning methods at Statistics Canada, the Modern Statistical Methods and Data Science Branch recognized the need for a framework to guide the development of machine learning processes and to make them responsible processes.
The Framework for Responsible Machine Learning Processes at Statistics Canada will be presented in this article, followed by a brief explanation of the review process put in place to implement the Framework. Finally, this article will conclude with some thoughts regarding future work.
Presentation of the Framework
Before presenting the framework adopted by Statistics Canada, we will give a brief overview of the Treasury Board Secretariat's Directive on Automated Decision-Making, which was the subject of an article in the June issue of the newsletter. It states that: "The objective of this Directive is to ensure that Automated Decision Systems are deployed in a manner that reduces risks to Canadians and federal institutions, and leads to more efficient, accurate, consistent, and interpretable decisions made pursuant to Canadian law." It also states that the Directive "... applies to any system, tool, or statistical models used to recommend or make an administrative decision about a client." At Statistics Canada, all projects that use machine learning or modelling, more generally, are part of a statistical program that does not aim to make administrative decisions about a client, at least not so far. As a result, Statistics Canada has not yet had to comply with this Directive and assess the impact of these decisions using the Algorithmic Impact Assessment Tool. However, as mentioned at the end of the previous section, Statistics Canada was proactive in adopting this Framework to ensure responsible use of machine learning at the agency.
Figure 1 provides a good overview of the Framework for Responsible Machine Learning Processes at Statistics Canada:
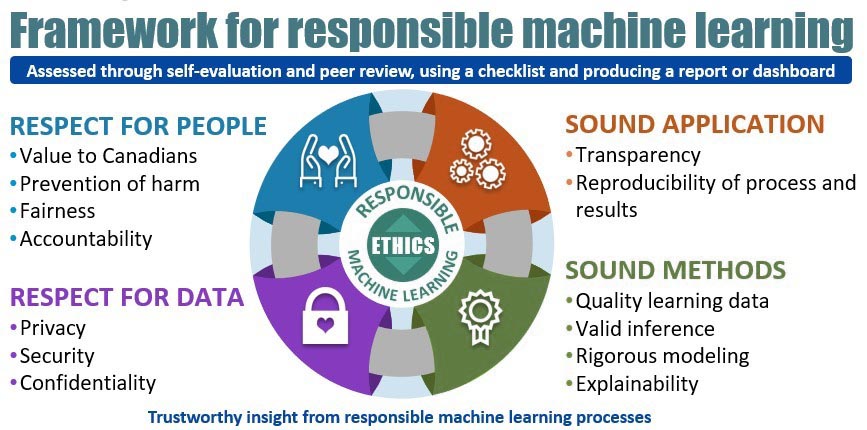
Description - Figure 1
Circular diagram depicting the four pivotal concepts for the production of trustworthy insight from responsible machine learning processes. Starting from the top left and moving clockwise:
Concept #1: Respect for People with attributes such as Value to Canadians; Prevention of harm; Fairness and Accountability.
Concept #2: Sound Application with attributes such as Transparency; Reproducibility of process and results.
Concept #3: Sound Methods with attributes such as Quality learning data; Valid inference; Rigorous modelling and Explainability.
Concept #4: Respect for Data with attributes such as Privacy; Security and Confidentiality.
Assessed through self-evaluation and peer review, using a checklist and producing a report or dashboard.
The Framework consists of guidelines for responsible machine learning, organized into four themes: Respect for People; Respect for Data; Sound Methods; and Sound Application. All four themes work together to ensure the ethical use of both the algorithms and the results of machine learning. These guidelines apply to all of Statistics Canada's statistical programs and projects that use machine learning algorithms, particularly those put into production. This includes supervised and unsupervised learning algorithms.
The theme Respect for People is described using four attributes.
- The concept of Value to Canadians in the context of machine learning means that its use must create added value, whether in the products themselves or through greater efficiency in the production process.
- Prevention of harm requires an awareness of the potential harm and meaningful dialogue with stakeholders, spokespersons and advocates prior to the implementation of a machine learning project.
- Fairness implies that the principle of proportionality between means and ends is respected, and that a balance is struck between competing interests and objectives. Fairness ensures that individuals and groups are free from unfair bias, discrimination and stigmatization.
- Accountability is the legal and ethical obligation on an individual or organization to be responsible for its activities and to disclose the results in a transparent manner. Algorithms are not accountable; somebody is accountable for the algorithms.
Statistics Canada takes data seriously. The theme of Respect for Data has three attributes: privacy of the people to whom the data pertain; security of information throughout the data lifecycle; and confidentiality of identifiable information.
- Privacy is the right to be left alone, to be free from interference, surveillance and intrusions. When acquiring sensitive information, governments have obligations with respect to the collection, use, disclosure and retention of personal information. Privacy generally refers to information about individual persons (definition from the Policy on Privacy and Confidentiality).
- Security is the arrangements organizations use to prevent confidential information from being obtained or disclosed inappropriately, based on assessed threats and risks. Security measures also protect the integrity, availability and value of the information assets. This includes both physical safeguards, such as restricted access to areas where the information is stored and used, and security clearances for employees, as well as technological safeguards to prevent unauthorized electronic access (definition from the Policy on Privacy and Confidentiality).
- Confidentiality refers to a protection not to release identifiable information about an individual (such as a person, business or organization). It implies a relationship of "trust" between the supplier of the information and the organization collecting it; this relationship is built on the assurance that the information will not be disclosed without the individual's permission or without due legal authority (definition from the Policy on Privacy and Confidentiality).
Sound application refers to implementing, maintaining and documenting machine learning processes in such a way that the results are always reliable and the entire process can be understood and recreated. This theme has two attributes: transparency and reproducibility of process and results.
- Transparency refers to having a clear justification for what makes this particular algorithm and learning data the most appropriate for the application under study. To achieve transparency, machine learning developers should create comprehensive documentation, including making code accessible and available to others, without compromising confidentiality or privacy.
- Reproducibility of process means that there is sufficient documentation and code sharing such that the machine learning process could be recreated "from scratch." Reproducibility of results means that the same results are reliably produced when all the operating conditions are controlled. There are no ad hoc or human intervention steps that could alter the results.
Sound methods are those that can be relied on to efficiently and effectively produce the expected results. Statistics Canada typically follows recognized protocols involving consultation with peers and experts, documentation and testing in developing sound methods. This theme has four attributes: quality of learning data; valid inference; rigorous modelling; and explainability.
- In the context of machine learning, the quality of learning data is measured by both the consistency and accuracy of labelled data. Coverage, meaning that the labels and descriptions cover the entire span of what the algorithm will encounter in production is also important to reduce the risk of bias or discrimination (fairness), and representativity in terms of the distribution of the input or feature variables is important for realistic measures of performance.
- Valid inference refers to the ability to extrapolate based on a sample to arrive at correct conclusions with a known precision about the population from which the sample was drawn. In the machine learning context, valid inference means that predictions made on never-before-seen data using the trained model are reasonably close to their respective true values in a high proportion, or in the case of categorical data, predictions are correct in a high proportion.
- Rigorous modelling in machine learning means ensuring that the algorithms are verified and validated. This will enable users and decision-makers to justifiably trust the algorithm in terms of fitness for use, reliability and robustness.
- An explainable model is one with sufficient documentation that it is clear how the results should be used, and what sorts of conclusions or further investigations can be supported. In other words, an explainable model is not a black box.
Review process
The review process consists of the implementation of the Framework. The focus is on projects with targets for using machine learning methods in one or more steps leading to the production of official statistics. The process includes three steps: self-assessment using the checklist; peer review; presentation of the project to the Modern Statistical Methods and Data Science Branch's Scientific Review Committee.
First, the team that developed the project using machine learning methods must conduct a self-assessment of the use of those techniques. To that end, the team must review the Framework and answer the questions in the checklist. The checklist is a questionnaire in which each guideline in the Framework is generally reformulated into one or more questions. That questionnaire and the project documentation and methods used are then sent to the review team.
Peer review can then begin. Reviewers from two different teams will be involved. The questions and the documentation on the first two themes of the Framework, Respect for People and Respect for Data, will be assessed by the Data Ethics Secretariat team while the section on the last two themes, Sound Application and Sound Methods, will be assessed by a team from the Data Science Methods and Quality Section. Following that assessment, a report containing recommendations will be sent to the project manager.
The final step in the review process is presenting the project to the Modern Statistical Methods and Data Science Branch's Scientific Review Committee. This presentation sets out the methodology used during the machine learning process before an expert panel. The role of this committee is to challenge the methodology, including identifying potential gaps or problems and proposing improvements and corrections. Ultimately, the committee will recommend whether or not to implement the proposed methodology for the production of official statistics.
What's next?
Is this the end of the story? No, it is actually the beginning. New data sources and machine learning methods are emerging almost every day. To remain relevant, the Framework presented in this article must be frequently adapted and revised to reflect emerging issues of ethics and quality. Statistics Canada continues to apply this Framework to machine learning processes and to be aware of applications where the Directive on Automated Decision-Making could apply. The agency is in the process of establishing a register of all applications that have gone through this review process so it can be easily referenced when requests arise. Do you have questions about the responsible use of certain machine learning methods? Are you required to submit your projects to the Treasury Board Secretariat's Directive and to submit an independent assessment of your application? At Statistics Canada, we have already done this type of review for another department using the Framework discussed in this article and are available to do other reviews if need be. Please contact statcan.dscd-ml-review-dscd-revue-aa.statcan@statcan.gc.ca.
- Date modified: