Analyse des tendances en matière de dépenses et de ressources humaines
Dépenses réelles
Graphique des tendances relatives aux dépenses de l'organisme
Le graphique ci-dessous présente les dépenses prévues (votées et législatives) au fil du temps.
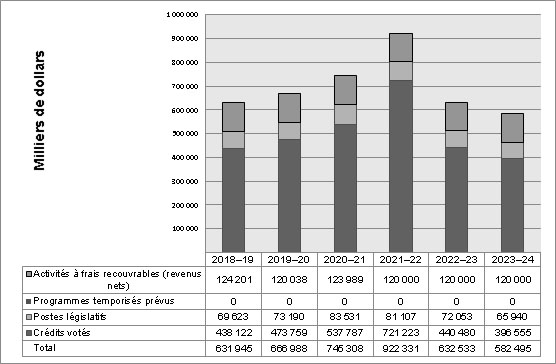
Description - Graphique des tendances relatives aux dépenses de l'organisme
| Exercice | Total | Crédits votés | Postes législatifs | Programmes temporisés prévus | Activités à frais recouvrables (revenus nets) |
|---|---|---|---|---|---|
| 2018-2019 | 631 945 | 438 122 | 69 623 | 0 | 124 201 |
| 2019-2020 | 666 988 | 473 759 | 73 190 | 0 | 120 038 |
| 2020-2021 | 735 308 | 537 787 | 83 531 | 0 | 123 989 |
| 2021-2022 | 922 331 | 721 223 | 81 107 | 0 | 120 000 |
| 2022-2023 | 632 533 | 440 480 | 72 053 | 0 | 120 000 |
| 2023-2024 | 582 495 | 396 555 | 65 940 | 0 | 120 00 |
| Responsabilités essentielles et Services internes | Budget principal des dépenses 2020-2021 | Dépenses prévues 2020-2021 | Dépenses prévues 2021-2022 | Dépenses prévues 2022-2023 | Autorisations totales pouvant être utilisées 2020-2021 | Dépenses réelles (autorisations utilisées) 2018-2019 | Dépenses réelles (autorisations utilisées) 2019-2020 | Dépenses réelles (autorisations utilisées) 2020-2021 |
|---|---|---|---|---|---|---|---|---|
| Renseignements statistiques | 661 506 812 | 661 506 812 | 855 425 655 | 566 602 643 | 715 298 954 | 559 559 344 | 584 770 894 | 666 463 788 |
| Services internes | 73 941 885 | 73 941 885 | 66 905 037 | 65 930 587 | 80 666 297 | 72 385 465 | 82 217 225 | 78 844 148 |
| Total des dépenses brutes | 735 448 697 | 735 448 697 | 922 330 692 | 632 533 230 | 795 965 251 | 631 944 809 | 666 988 119 | 745 307 936 |
| Revenus disponibles | -120 000 000 | -120 000 000 | -120 000 000 | -120 000 000 | -123 989 068 | -124 200 719 | -120 038 495 | -123 989 068 |
| Total des dépenses nettes | 615 448 697 | 615 448 697 | 802 330 692 | 512 533 230 | 671 976 183 | 507 744 090 | 546 949 624 | 621 318 868 |
Le financement de Statistique Canada provient de deux sources, à savoir les crédits parlementaires directs et les activités à frais recouvrables. L'organisme est autorisé à générer 120 millions de dollars par année en revenus disponibles dans deux secteurs : les enquêtes statistiques et les services connexes, ainsi que les demandes personnalisées et les ateliers. Si l'organisme dépasse cette somme en revenus disponibles, il peut présenter une demande d'augmentation de l'autorisation, comme il l'a fait ces dernières années.
Depuis quelques années, les revenus disponibles provenant des activités à frais recouvrables ont représenté de 120 millions de dollars à 124 millions de dollars par année du total des ressources budgétaires de l'organisme. Une part importante de ces revenus disponibles provient de ministères et d'organismes fédéraux et sert à financer des projets statistiques précis.
Les fluctuations des dépenses observées entre les années figurant dans le graphique et celles figurant dans le tableau ci-dessus sont principalement attribuables au Programme du recensement. Les dépenses votées ont diminué en 2018-2019, au moment où le Recensement de la population de 2016 et le Recensement de l'agriculture de 2016 tiraient à leur fin. Cette tendance est typique pour l'organisme en raison de la nature cyclique du Programme du recensement. Les dépenses recommencent à augmenter et culminent de nouveau en 2021-2022, au moment de la tenue du Recensement de la population de 2021 et du Recensement de l'agriculture de 2021, puis diminueront de façon importante au cours des années suivantes lorsque ces activités prendront fin.
La différence entre les dépenses réelles de 2020-2021 et les autorisations totales pouvant être utilisées de 2020-2021 est surtout attribuable à la manière dont l'organisme assure la gestion stratégique de ses investissements. L'organisme s'est servi du mécanisme de report du budget d'exploitation pour gérer la nature cyclique des opérations normales des programmes, de manière à favoriser les priorités stratégiques de l'organisme et à maintenir la qualité des programmes existants. Tout au long de l'année, les crédits inutilisés prévus et les fonds reportés sont gérés de façon centralisée dans le cadre des responsabilités essentielles liées aux renseignements statistiques, en fonction des priorités établies.
La différence est également attribuable à plusieurs modifications apportées au plan de dépenses initial du Recensement de la population de 2021, ce qui a entraîné une diminution des dépenses pour 2020-2021. Ces modifications découlent principalement de la pandémie de COVID-19.
Les dépenses au titre des Services internes de 2018-2019 à 2020-2021 tiennent compte de ressources prévues provenant du financement temporaire lié à une nouvelle initiative approuvée en 2018-2019, soit la migration de l'infrastructure de l'organisme vers le nuage.
| Responsabilités essentielles et Services internes | Dépenses brutes réelles 2020-2021 | Revenus réels affectés aux dépenses 2020-2021 | Dépenses réelles nettes (autorisations utilisées) 2020-2021 |
|---|---|---|---|
| Renseignements statistiques | 666 463 788 | -123 989 068 | 542 474 720 |
| Services internes | 78 844 148 | 0 | 78 844 148 |
| Total des dépenses brutes | 745 307 936 | -123 989 068 | 621 318 868 |
Statistique Canada a généré des revenus disponibles de 124 millions de dollars grâce à la vente de produits et services statistiques.
Ressources humaines réelles
| Responsabilités essentielles et Services internes | Nombre d'équivalents temps plein réels 2018-2019 | Nombre d'équivalents temps plein réels 2019-2020 | Nombre d'équivalents temps plein prévus 2020-2021 | Nombre d'équivalents temps plein réels 2020-2021 | Nombre d'équivalents temps plein prévus 2021-2022 | Nombre d'équivalents temps plein prévus 2022-2023 |
|---|---|---|---|---|---|---|
| Renseignements statistiques | 5 498 | 5 595 | 5 800 | 6 099 | 6 026 | 5 065 |
| Services internes | 645 | 626 | 585 | 684 | 563 | 546 |
| Total des dépenses brutes | 6 143 | 6 221 | 6 385 | 6 783 | 6 589 | 5 611 |
| Revenus disponibles | -1 380 | -1 366 | -1 251 | -1 340 | -1 231 | -1 241 |
| Total des dépenses nettes | 4 763 | 4 856 | 5 134 | 5 443 | 5 358 | 4 370 |
Tout comme les tendances des dépenses prévues, les variations des équivalents temps plein (ETP) d'une année à l'autre sont en grande partie attribuables à la nature cyclique du Programme du recensement. Les activités ont diminué en 2018-2019, alors que le Recensement de la population de 2016 et le Recensement de l'agriculture de 2016 tiraient à leur fin. Les activités recommencent à augmenter et culminent de nouveau en 2021-2022, au moment de la tenue du Recensement de la population de 2021 et du Recensement de l'agriculture de 2021. Il y a aussi eu une augmentation temporaire des ETP en 2020-2021, qui est attribuable à l'embauche d'intervieweurs par Statistique Canada, en vertu de la Loi sur la statistique, afin de fournir une capacité supplémentaire aux gouvernements provinciaux et territoriaux pour effectuer la recherche des contacts.
Sont compris dans les dépenses nettes pour les ETP environ 410 ETP pour les fonctionnaires en poste au Canada, à l'extérieur de la région de la capitale nationale. En ce qui a trait aux intervieweurs en fonction hors de la région de la capitale nationale, ces dépenses comprennent environ 1 095 ETP (ce qui représente environ 2 100 intervieweurs). Ces intervieweurs sont des travailleurs à temps partiel dont la semaine de travail désignée est déterminée par le volume de travail de collecte à effectuer. Ils sont embauchés en vertu de la Loi sur la statistique, sous l'autorité du ministre de l'Innovation, des Sciences et de l'Industrie. Les intervieweurs sont régis par deux conventions collectives distinctes, et ils sont embauchés par l'entremise des Opérations des enquêtes statistiques. Bon nombre des principaux produits de Statistique Canada reposent en grande partie sur la collecte de données et sur l'administration de ces activités, qui se déroulent partout au pays.
Dépenses par crédit voté
Pour obtenir de plus amples renseignements au sujet des dépenses votées et des dépenses législatives de Statistique Canada, veuillez consulter les Comptes publics du Canada 2020-2021.
Dépenses et activités du gouvernement du Canada
Des renseignements concernant l'harmonisation des dépenses de Statistique Canada avec les dépenses et les activités du gouvernement du Canada sont disponibles dans l'InfoBase du GC.
États financiers et faits saillants des états financiers
États financiers
Les états financiers (non audités) de Statistique Canada pour l'exercice se terminant le 31 mars 2021 se trouvent sur le site Web de l'organisme.
L'organisme utilise la méthode de comptabilité d'exercice intégrale pour la préparation et la présentation de ses états financiers annuels, lesquels font partie du processus de production de rapports sur les résultats ministériels. Toutefois, les autorisations de dépenses présentées dans les sections précédentes du présent rapport continuent de reposer sur la comptabilité des dépenses. Un rapprochement entre les bases de rapport figure à la note 3 des états financiers.
Faits saillants des états financiers
| Renseignements financiers | Résultats prévus 2020-2021 | Résultats réels 2020-2021 | Résultats réels 2019-2020 (redéfinis) | Écart (résultats réels 2020-2021 moins résultats prévus 2020-2021) | Écart (résultats réels 2020-2021 moins résultats réels 2019-2020) |
|---|---|---|---|---|---|
| Total des dépenses | 848 569 377 | 852 413 139 | 757 438 321 | 3 843 762 | 94 974 818 |
| Total des revenus | 120 000 000 | 120 247 616 | 121 936 643 | 247 616 | -1 689 027 |
| Coût de fonctionnement net avant le financement du gouvernement et les transferts | 728 569 377 | 732 165 523 | 635 501 678 | 3 596 146 | 96 663 845 |
L'état des résultats prospectifs (non audité) des opérations de Statistique Canada pour l'exercice se terminant le 31 mars 2021 est disponible sur le site Web de l'organisme. Les hypothèses qui sous-tendent les prévisions ont été formulées avant la fin de l'exercice 2019-2020.
Le coût de fonctionnement net avant le financement du gouvernement et les transferts s'est établi à 732,2 millions de dollars, ce qui représente une augmentation de 96,7 millions de dollars (15,2 %) par rapport au coût de 635,5 millions de dollars enregistré en 2019-2020. La hausse des dépenses est principalement attribuable à une augmentation globale des activités de l'organisme, en particulier pour le Programme du Recensement de la population de 2021, le programme de l'infonuagique et de la migration de la charge de travail, ainsi que les initiatives liées à la COVID-19 en partenariat avec Santé Canada. De plus, les coûts salariaux ont augmenté en raison de la ratification de certaines conventions collectives en 2020-2021. Cette hausse est contrebalancée par une diminution négligeable des revenus liés aux projets à frais recouvrables, principalement auprès de clients non fédéraux.
L'écart entre les coûts nets prévus et réels pour 2020-2021 est de 3,6 millions de dollars (0,5 %). Les dépenses ont été supérieures de 3,8 millions de dollars à ce qui avait été prévu. La ratification de conventions collectives, ainsi que l'augmentation des indemnités de vacances et de congés compensatoires accumulés et les dépenses supplémentaires pour les initiatives liées à la COVID-19 en partenariat avec Santé Canada, ont contribué à une hausse importante des dépenses. Cela est principalement compensé par un changement du profil des dépenses du Programme du Recensement de la population de 2021, en raison de la pandémie de COVID-19 et d'autres facteurs, ce qui a entraîné une diminution des dépenses non salariales. Les revenus ont été supérieurs de 0,2 million de dollars à ce qui avait été prévu.
Pour obtenir de plus amples renseignements sur la répartition des dépenses selon le programme et le type de dépense, veuillez consulter les deux graphiques ci-dessous.
Dépenses brutes, selon la responsabilité essentielle
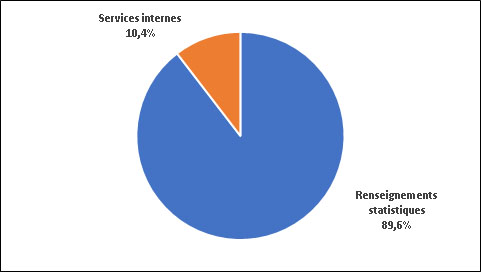
Les dépenses totales, y compris les revenus disponibles et les services fournis sans frais par les ministères et organismes fédéraux, se sont chiffrées à 852,4 millions de dollars en 2020-2021. Ces dépenses comprennent 763,4 millions de dollars (89,6 %) engagés pour les renseignements statistiques et 89,0 millions de dollars (10,4 %) affectés aux Services internes.
Dépenses brutes, selon le type de dépense
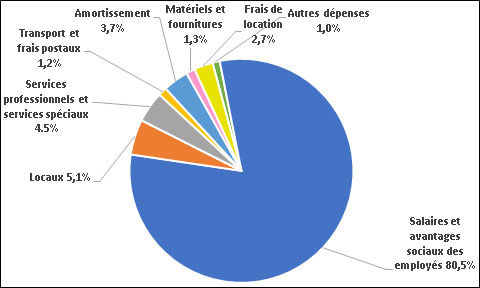
Statistique Canada a dépensé 852,4 millions de dollars en 2020-2021. Ces dépenses comprennent 685,9 millions de dollars (80,5 %) engagés pour les salaires et avantages sociaux des employés, 43,6 millions de dollars (5,1 %) pour les locaux, 38,0 millions de dollars (4,5 %) pour les services professionnels et les services spéciaux, 31,5 millions de dollars (3,7 %) pour l'amortissement, 23,1 millions de dollars (2,7 %) en frais de location, 10,8 millions de dollars (1,3 %) en matériels et fournitures, 10,6 millions de dollars (1,2 %) pour le transport et les frais postaux, et 8,5 millions de dollars (1,0 %) pour les autres dépenses.
| Renseignements financiers | 2020-2021 | 2019-2020 (reformulé) | Écart (2020-2021 moins 2019-2020) |
|---|---|---|---|
| Total des passifs nets | 160 919 348 | 130 839 608 | 30 079 740 |
| Total des actifs financiers nets | 77 141 756 | 66 957 087 | 10 184 669 |
| Dette nette | 83 777 592 | 63 882 521 | 19 895 071 |
| Total des actifs non financiers | 170 230 625 | 170 649 354 | -418 729 |
| Situation financière nette | 86 453 033 | 106 766 833 | -20 313 800 |
La situation financière nette de Statistique Canada s'établissait à 86,5 millions de dollars à la fin de 2020-2021, ce qui constitue une diminution de 20,3 millions de dollars par rapport à la situation financière nette de 2019-2020 qui se situait à 106,8 millions de dollars.
L'augmentation du total des passifs nets s'explique principalement par une hausse des charges à payer pour les indemnités de vacances et de congés compensatoires découlant de l'accumulation de jours de vacances par les employés pendant la pandémie de COVID-19 et une augmentation des comptes créditeurs, principalement pour le Programme du Recensement de la population de 2021.
L'augmentation du total des actifs financiers nets s'explique principalement par une hausse des montants à recevoir du Trésor au 31 mars pour les comptes créditeurs et les salaires à payer. Cela est contrebalancé par une diminution des comptes débiteurs d'autres ministères et organismes gouvernementaux et de parties externes.
Pour obtenir de plus amples renseignements sur la répartition des bilans dans l'état de la situation financière, veuillez consulter les deux graphiques ci-dessous.
Actifs, selon le type d'actif
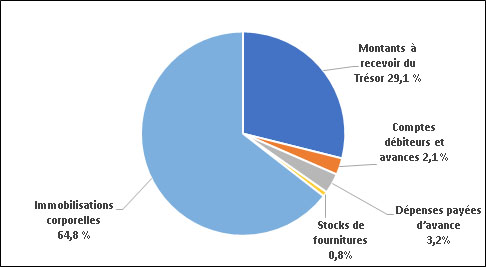
Le total des actifs, y compris les actifs financiers et non financiers, s'établissait à 247,4 millions de dollars à la fin de 2020-2021. Les immobilisations corporelles représentent la partie la plus importante des actifs, soit 160,4 millions de dollars (64,8 %). Ces actifs comprennent les logiciels (77,0 millions de dollars), les logiciels en voie de développement (66,9 millions de dollars), les améliorations locatives (14,6 millions de dollars) et d'autres actifs (1,9 million de dollars). La partie qui reste comprend les montants à recevoir du Trésor (71,9 millions de dollars) [29,1 %], les dépenses payées d'avance (7,9 millions de dollars) [3,2 %], les comptes débiteurs et avances (5,3 millions de dollars) [2,1 %] et les stocks de fournitures (1,9 million de dollars) [0,8 %].
Passifs, selon le type de passif
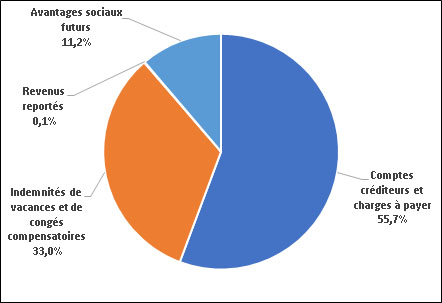
Le total des passifs s'élevait à 160,9 millions de dollars à la fin de 2020-2021. Les comptes créditeurs et charges à payer constituent la partie la plus importante, soit 89,6 millions de dollars (55,7 %) du passif total. Les comptes créditeurs et charges à payer comprennent les comptes créditeurs de tiers (41,7 millions de dollars), les comptes créditeurs d'autres ministères et organismes fédéraux (11,6 millions de dollars) et les salaires à payer (36,3 millions de dollars). La proportion suivante en importance est celle correspondant aux indemnités de vacances et de congés compensatoires, soit 33,0 % (53,1 millions de dollars). Les avantages sociaux futurs représentaient 18,1 millions de dollars, ou 11,2 %, du passif total. La part restante se compose des revenus reportés, soit 0,1 % (0,1 million de dollars) du passif total.







 L'arrière de la carte saturée de gouttes de sang séché
L'arrière de la carte saturée de gouttes de sang séché