
Apprentissage automatique explicable, théorie des jeux et valeurs de Shapley : un examen technique
Par : Soufiane Fadel, Statistique Canada
Les modèles d'apprentissage automatique sont souvent considérés comme une boîte noire opaque. Ils regroupent des caractéristiques à utiliser comme données d'entrée et génèrent des prédictions. Après la phase d'entraînement, quelques questions courantes se posent. Comment les différentes caractéristiques influent-elles sur les résultats de la prédiction? Quelles sont les variables les plus importantes qui influent sur les résultats de la prédiction? Dois-je croire les conclusions, bien que les indicateurs de rendement du modèle semblent être excellents? Par conséquent, l'explicabilité du modèle s'avère importante dans l'apprentissage automatique. Les renseignements obtenus à partir de ces méthodes d'intelligibilité sont utiles pour effectuer le débogage, guider l'ingénierie des caractéristiques, orienter les futures collectes des données, éclairer la prise de décision humaine et instaurer la confiance.
Pour être plus précis, distinguons deux idées essentielles dans l'apprentissage automatique : l'intelligibilité et l'explicabilité. L'intelligibilité désigne le degré avec lequel un modèle d'apprentissage automatique peut lier avec précision une cause (données d'entrée) à un résultat (données de sortie). L'explicabilité fait référence au degré avec lequel le fonctionnement interne d'une machine ou d'un système d'apprentissage profond peut être articulé avec des mots humains. En d'autres termes, c'est la capacité d'expliquer ce qui se passe.
Dans le présent article, nous nous penchons également sur les valeurs de Shapley, qui constituent l'une des méthodes d'explicabilité des modèles les plus utilisées. Nous donnons un aperçu technique des détails sous-jacents à l'analyse de la valeur de Shapley et décrivons les bases du calcul des valeurs de Shapley en formalisant mathématiquement le concept et en donnant également un exemple pour illustrer l'analyse de la valeur de Shapley dans un problème d'apprentissage automatique.
Quelles sont les valeurs explications additives de Shapley (SHAP)?
Si vous recherchez l'expression anglaise « SHAP analysis » (analyse SHAP), vous découvrirez qu'elle provient d'un article de 2017 de Lundberg et Lee, intitulé « A Unified Approach to Interpreting Model Predictions » (le contenu de cette page est en anglais), qui introduit l'idée de « Shapley Additive exPlanations » (explications additives de Shapley, également appelée SHAP). SHAP permet de fournir une explication pour la prédiction d'un modèle d'apprentissage automatique en calculant la contribution de chaque caractéristique à la prédiction. L'explication technique du concept de SHAP repose sur le calcul des valeurs Shapley à partir de la théorie des jeux de coalition. Les valeurs de Shapley ont été nommées en l'honneur de Lloyd Shapley, qui a introduit le concept en 1951 et a ensuite remporté le Prix de la Banque de Suède en sciences économiques en mémoire d'Alfred Nobel en 2012. Concrètement, les valeurs de Shapley s'apparentent à une méthode permettant de montrer l'impact relatif de chaque caractéristique (ou variable) que nous mesurons sur les données de sortie finales du modèle d'apprentissage automatique en comparant l'effet relatif des données d'entrée à la moyenne.
Théorie des jeux et théorie des jeux coopératifs
Tout d'abord, expliquons la théorie des jeux afin de comprendre comment elle est utilisée pour analyser les modèles d'apprentissage automatique. La théorie des jeux constitue un cadre théorique pour les interactions sociales avec des acteurs en concurrence. C'est l'étude de la prise de décision optimale par des agents indépendants et concurrents dans un contexte stratégique. Un « jeu » s'entend d'un scénario comportant de nombreux décideurs, chacun d'entre eux cherchant à maximiser ses résultats. Le choix optimal sera influencé par les décisions des autres. Le jeu détermine les identités, les préférences et les tactiques possibles des participants, ainsi que la manière dont ces stratégies influent sur le résultat. Dans le même contexte, la théorie des jeux coopératifs (une branche de la théorie des jeux) postule que les coalitions de joueurs constituent les principales unités de prise de décision et peuvent contraindre à une conduite coopérative. Par conséquent, au sein des jeux coopératifs, la compétition s'opère davantage entre une coalition de joueurs qu'entre des joueurs individuels. L'objectif vise à mettre au point une « formule » pour mesurer la contribution au jeu de chaque joueur, cette formule est la valeur de Shapley.
Valeurs de Shapley : intuition
Le scénario s'entend comme suit : une coalition de joueurs collabore afin d'obtenir un bénéfice total particulier grâce à leur collaboration. Étant donné que certains joueurs peuvent contribuer davantage à la coalition que d'autres et que divers joueurs peuvent présenter divers degrés d'influence ou d'efficacité, quelle devrait être la répartition finale des bénéfices entre les joueurs dans un jeu donné? En d'autres termes, nous voulons connaître l'importance de la collaboration de chaque participant et le type de gain qu'il peut escompter en conséquence. Une solution potentielle à ce problème est fournie par les valeurs du coefficient de Shapley. Ainsi, dans le contexte de l'apprentissage automatique, les valeurs des caractéristiques d'une instance de données servent de membres de la coalition. Les valeurs de Shapley nous indiquent alors comment répartir le « gain » entre les caractéristiques de manière équitable, ce qui constitue la prédiction. Un joueur peut être une valeur de caractéristique unique, comme dans les données tabulaires. Un joueur peut également être défini comme un ensemble de valeurs des caractéristiques.
Valeurs de Shapley : formalisme
Il est important de comprendre la base mathématique et les propriétés qui soutiennent le cadre de la valeur de Shapley. Ce point est abordé plus en détail dans cette section.
Formule de la valeur de Shapley
La valeur de Shapley est définie comme la contribution marginale de la valeur de la variable à la prédiction parmi toutes les « coalitions » concevables ou sous-ensembles de caractéristiques. En d'autres termes, il s'agit d'une approche visant à redistribuer les bénéfices globaux entre les joueurs, étant donné qu'ils coopèrent tous. Le montant que chaque « joueur » (ou caractéristique) obtient après une partie est défini comme suit :
Où :
- : données d'entrée observées
- : valeur de Shapley pour la caractéristique des données d'entrée pour le jeu/modèle .
- : ensemble de toutes les caractéristiques
- : modèle formé sur le sous-ensemble de caractéristiques .
- : modèle formé sur le sous-ensemble de caractéristiques et .
- : données d'entrée restreintes de étant donné le sous-ensemble de caractéristiques .
- : données d’entrée restreintes de étant donné le sous-ensemble de caractéristiques et .
Cela pourrait être reformulé et exprimé comme suit :
Le concept des valeurs de Shapley peut être divisé en trois composantes : contribution marginale, pondération combinatoire et moyenne. Il est préférable de lire de droite à gauche tout en développant son intuition.
- La contribution marginale s'entend de la mesure dans laquelle le modèle change lorsqu'une nouvelle caractéristique est ajoutée. Étant donné un ensemble de caractéristiques , nous désignons comme le modèle formé avec les caractéristiques présentes. est le modèle formé avec une caractéristique supplémentaire . Lorsque ces deux modèles présentent des prédictions différentes, la quantité entre crochets indique exactement de combien ils diffèrent l'un de l'autre.
- La pondération combinatoire s'entend de la pondération à donner à chacun des différents sous-ensembles de caractéristiques de taille (en excluant la caractéristique ).
- Enfin, la moyenne déterminera la moyenne de toutes les contributions marginales de toutes les tailles de sous-ensembles imaginables allant de à . Nous devons omettre la seule caractéristique pour laquelle nous souhaitons évaluer l'importance.
Propriétés théoriques
Les valeurs de Shapley présentent un certain nombre de caractéristiques souhaitables; de telles valeurs satisfont aux quatre propriétés suivantes : efficacité, symétrie, joueur nul et linéarité. Ces aspects peuvent être considérés comme une définition d'une pondération équitable lorsqu'ils sont pris ensemble.
| Définition | Formalisme mathématique | |
|---|---|---|
| Efficacité | La somme des valeurs de Shapley de toutes les caractéristiques est égale à la valeur de la prédiction formée avec toutes les caractéristiques, de sorte que la prédiction totale est répartie entre les caractéristiques. | |
| Symétrie | Les contributions de deux valeurs des caractéristiques devraient être les mêmes si elles contribuent de manière égale à toutes les coalitions possibles. | |
| Joueur nul | Une caractéristique qui ne modifie pas la valeur prédite, quelle que soit la coalition de valeurs des caractéristiques à laquelle elle est ajoutée, doit avoir une valeur de Shapley de . | |
| Linéarité | Si deux modèles décrits par les fonctions de prédiction et sont combinés, la prédiction distribuée devrait correspondre aux contributions dérivées de et aux contributions dérivées de . |
Considérez le scénario suivant : vous avez entraîné un modèle de forêt aléatoire, ce qui implique que la prédiction est basée sur une moyenne de plusieurs arbres de décision différents. Vous pouvez calculer la valeur de Shapley pour chaque arbre indépendamment, en faire la moyenne, et utiliser la valeur de Shapley résultante pour calculer la valeur de la caractéristique dans une forêt aléatoire. Cela est garanti par la propriété de linéarité.
Exemple d'application d'apprentissage automatique : intelligibilité
Les qualités théoriques des valeurs de Shapley sont toutes intéressantes et souhaitables, mais en pratique, il se peut que nous ne soyons pas en mesure de déterminer la valeur de Shapley précise en raison de contraintes pratiques. L'obtention de la formulation précise de la valeur de Shapley nécessite un temps de traitement important. Lorsqu'il s'agit de situations réelles, la réponse approximative est souvent la plus pratique, car il existe coalitions potentielles des valeurs des caractéristiques. Le calcul de la valeur exacte de Shapley est trop coûteux d'un point de vue informatique. Heureusement, nous pouvons appliquer certaines approches d'approximation; la qualité de ces techniques influe sur la robustesse des caractéristiques théoriques. Plusieurs tests en recherche ont été menés (en anglais seulement) pour démontrer que les résultats de l'approximation SHAP sont plus cohérents par rapport aux valeurs produites par d'autres algorithmes couramment utilisés.
La figure suivante fournit un exemple de la façon d'examiner les contributions des caractéristiques pour étudier les prédictions d'un modèle « Xgboost » qui estime le prix de vente des maisons à l'aide de 237 variables explicatives, décrivant presque tous les aspects des maisons résidentielles à Ames, dans l'lowa. L'ensemble des données liées à cette analyse est accessible au public sur Kaggle - House Prices - Advanced Regression Techniques (le contenu de cette page est en anglais).
Figure 1
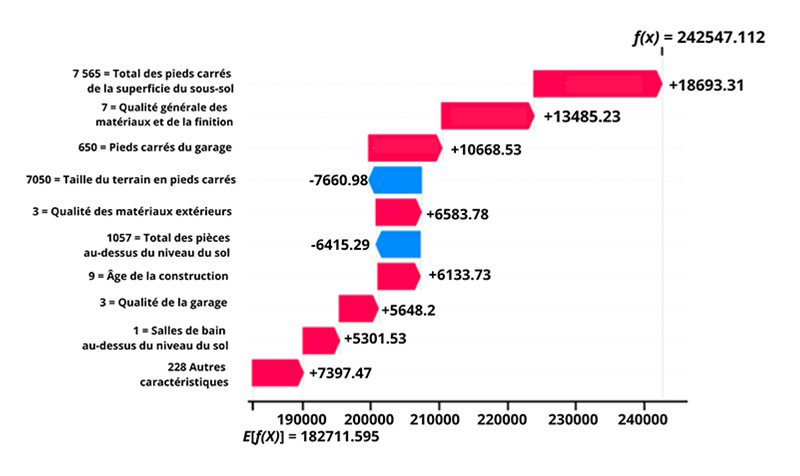
Description - Figure 1
Un graphique en cascade montrant l'évolution prévue de la valeur d'une maison en fonction de caractéristiques telles que la taille de la surface habitable, la taille du garage, la superficie en pieds carrés, la salle de bain, etc. La sortie du modèle pour cette prédiction varie en fonction de chaque caractéristique pour obtenir une valeur prédite complète de la maison. L'axe y contient la liste des caractéristiques et leur valeur associée. L'axe x représente la valeur attendue de la sortie du modèle, = 182711.595. Les caractéristiques, et leur valeur, sont listées avec leur contribution positive ou négative comme suit :
7 565 = Total des pieds carrés de la superficie du sous-sol +18693.31
7 = Qualité Générale des matériaux et de la finition +13485.23
650 = Pieds carrés du garage +10668.53
7050 = Taille du terrain en pieds carrés -7660.98
3 = Qualité des matériaux extérieurs +6583.78
1057 = Total des pièces au-dessus du niveau du sol -6415.29
9 = Âge de la construction +6133.73
3 = Qualité de la garage +5648.2
1 = Salles de bain au-dessus du niveau du sol +5301.53
228 autres caractéristiques +7397.47
En bas du graphique est indiquée la valeur prévue des données de sortie du modèle (182 000 $). Chaque ligne au-dessus montre comment la contribution positive (en rouge) ou négative (en bleu) de chaque caractéristique fait évoluer la valeur en la faisant passer des données de sortie prévues du modèle aux données de sortie du modèle pour cette prédiction (242 000 $). Les informations en gris devant les noms des caractéristiques indiquent la valeur de chaque caractéristique pour cet échantillon. À partir de ce graphique, nous pouvons conclure que 228 caractéristiques ajoutent un total de 7 397,47 $ à la valeur prédite, et que chacune des variables énumérées ci-dessus a un impact supérieur à 5 000 $. Le prix prévu de cette maison particulière grimpe à plus de 18 000 $ avec une surface habitable au sol de 7 500 pieds carrés. Le prix est réduit de 7 660,98 $ en raison de la taille du terrain de 7 050 pieds carrés.
Conclusion
Comme nous l'avons vu, les valeurs de Shapley comportent des propriétés théoriques mathématiquement satisfaisantes en tant que solution aux problèmes de la théorie des jeux. Le cadre fournit des explications contrastives, ce qui signifie qu'au lieu de comparer une prédiction à la prédiction moyenne de l'ensemble des données, il est possible de la comparer à un sous-ensemble ou même à un seul point des données. Il explique qu'une prédiction est un jeu joué par les valeurs des caractéristiques.
En outre, cette méthodologie constitue l'une des rares méthodes explicatives fondées sur une théorie solide, puisque les axiomes mathématiques (efficacité, symétrie, joueur nul, linéarité) fournissent une base raisonnable pour l'explication.
Enfin, il convient de préciser que cette stratégie figure parmi les nombreuses solutions possibles. Cependant, la valeur de Shapley est souvent préférable, car elle est basée sur une théorie solide, répartit équitablement les effets et fournit une explication complète.
Références
Bosa, K. (2021). Utilisation responsable de l'apprentissage automatique à Statistique Canada.
Cock, D. D. (2011). Ames, Iowa: Alternative aux données sur le logement à Boston. Journal of Statistics Education.
Molnar, C. (2021). Apprentissage automatique interprétable : Un guide pour rendre les modèles de la boîte noire explicables.
Scott Lundberg, S.-I. L. (2017). Une approche unifiée de l'interprétation des prédictions des modèles.
Yadvinder Bhuller, H. C., & O'Rourke, K. (n.d.). De l'exploration à l'élaboration de modèles d'apprentissage automatique interprétables et précis pour la prise de décision : privilégiez la simplicité et non la complexité.
Tous les projets d'apprentissage automatique à Statistique Canada sont conçus dans le contexte du Cadre pour l'utilisation des processus d'apprentissage automatique de façon responsable de l'organisme, qui vise à proposer des orientations et des conseils pratiques sur la façon responsable d'élaborer ces processus automatisés.
- Date de modification :