
Utilisation responsable de l'apprentissage automatique à Statistique Canada
Par : Keven Bosa, Statistique Canada
De plus en plus de données sont générées au quotidien. On n'a qu'à penser aux données de téléphonie cellulaire, d'images satellites, de navigation sur internet ou de lecteur optique. La profusion de données fait grandir l'appétit de la population pour des statistiques nouvelles, plus détaillées et plus actuelles. Comme plusieurs autres organismes nationaux de statistique, Statistique Canada a adhéré à cette nouvelle réalité et utilise de plus en plus de sources de données alternatives afin d'améliorer et moderniser ses différents programmes statistiques. Étant donné leur volume et leur vélocité, des méthodes d'apprentissage automatique sont souvent nécessaires pour utiliser ces nouvelles sources de données.
Statistique Canada a mené plusieurs projets faisant appel à des méthodes d'apprentissage automatique au cours des trois dernières années. Par exemple, les scientifiques de données se sont servis du traitement de langage naturel pour attribuer une classe à des commentaires provenant de répondants au recensement ainsi qu'à d'autres enquêtes. Des méthodes d'apprentissage non supervisé ont été utilisées pour partitionner la base canadienne de données des coroners et des médecins légistes en groupes homogènes afin d'améliorer la compréhension de certains phénomènes. Un algorithme d'apprentissage supervisé a été développé pour prédire le rendement des cultures. Des projets utilisant des réseaux neuronaux sur des images satellites sont actuellement en cours pour optimiser le programme de l'agriculture. Dans un cas, l'objectif est de détecter la présence de serres alors que dans un autre cas, le but est d'identifier les différents types de grandes cultures. Un algorithme a aussi été élaboré pour extraire de l'information financière provenant de documents PDF. Les exemples précédents donnent une idée de la diversité des problèmes pour lesquels l'apprentissage automatique est utilisé.
L'utilisation de l'apprentissage automatique comprend son lot d'avantages : traitement des données volumineuses et non structurées, automatisation des processus en place, amélioration de la couverture et de la précision et bien d'autres. Toutefois, elle soulève aussi plusieurs questions. Par exemple :
- Est-ce que le processus protège l'intégrité et la confidentialité des données?
- Est-ce que la qualité des données d'entraînement est adéquate pour le but poursuivi?
- Une fois l'algorithme mis en place, qui est responsable des résultats et des effets qui en découlent?
Suite à ces questions et à l'augmentation de l'utilisation de méthodes d'apprentissage automatique à Statistique Canada, la Direction des méthodes statistiques modernes et de la science des données a reconnu le besoin d'un cadre pour guider l'élaboration des processus d'apprentissage automatique et d'en faire des processus responsables.
Le Cadre pour l'utilisation des processus d'apprentissage automatique de façon responsable à Statistique Canada sera présenté dans cet article, puis sera suivi d'une brève explication du processus de revue mis en place pour l'appliquer. Finalement, cet article se conclura en proposant quelques réflexions et en mentionnant quelques travaux futurs.
Présentation du Cadre
Avant de présenter le cadre de travail dont s'est doté Statistique Canada, nous ferons un bref survol de la Directive sur la prise de décisions automatisée établie par le Secrétariat du conseil du trésor. Celle-ci a d'ailleurs fait l'objet d'un article présenté dans l'édition du mois de juin du bulletin. Il y est mentionné que : « La présente Directive a pour objet de veiller à ce que les systèmes décisionnels automatisés soient déployés d'une manière qui permet de réduire les risques pour les Canadiens et les institutions fédérales, et qui donne lieu à une prise de décisions plus efficace, exacte et conforme, qui peut être interprétée en vertu du droit canadien. » Il est aussi mentionné que la Directive « … s'applique à tout système, outil ou modèle statistique utilisé pour recommander ou prendre une décision administrative au sujet d'un client.». À Statistique Canada, tous les projets utilisant l'apprentissage automatique ou, de façon plus générale la modélisation, font partie d'un programme statistique dont le but n'est pas de prendre des décisions administratives sur un client, du moins, pas jusqu'à présent. Statistique Canada n'a donc pas encore eu à se conformer à cette Directive et à évaluer l'incidence de ces décisions à l'aide de l'Outil d'évaluation de l'incidence algorithmique. Toutefois, comme mentionné à la fin de la section précédente, Statistique Canada a été proactif en adoptant ce Cadre afin de s'assurer d'une utilisation responsable de l'apprentissage automatique au sein de l'agence.
La figure 1 donne un bon aperçu du Cadre pour l’utilisation des processus d’apprentissage automatique de façon responsable à Statistique Canada.
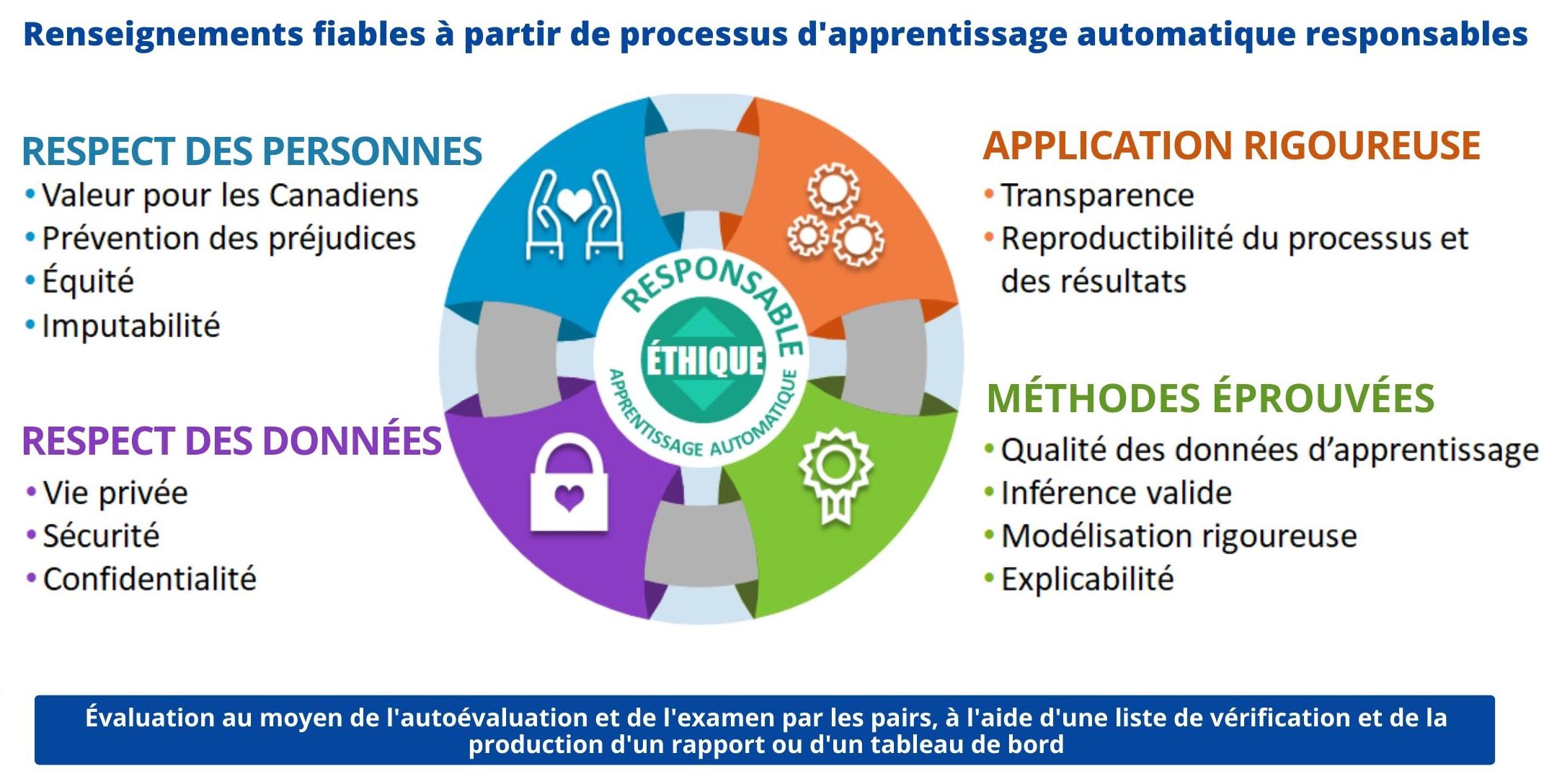
Description - Figure 1
Diagramme de flux circulaire décrivant les 4 concepts essentiels pour la production d'informations fiables à partir de processus d'apprentissage automatique responsables. À partir du haut à gauche et en se déplaçant dans le sens des aiguilles d'une montre :
Concept # 1: Respect des Personnes avec pour attributs : Valeur pour les Canadiens; Prévention des dommages; Équité et responsabilité.
Concept #2 : Application Rigoureuse avec pour attributs : Transparence; Reproductibilité du processus et des résultats.
Concept #3 : Méthodes Éprouvées avec pour attributs : Qualité des données d'apprentissage; Inférence valide; Modélisation rigoureuse et Explicabilité.
Concept #4 : Respect des Données avec pour attributs : Protection de la vie privée; Sécurité et Confidentialité.
Évaluation au moyen de l'auto-évaluation et de l'examen par les pairs, liste de vérification et production d'un rapport ou d'un tableau de bord.
Le cadre comprend des lignes directrices pour l'usage responsable de l'apprentissage automatique organisées en quatre thèmes : respect des personnes; respect des données; application rigoureuse; méthodes éprouvées. Les quatre thèmes mis en commun assurent l'utilisation éthique des algorithmes et des résultats de l'apprentissage automatique. Ces lignes directrices s'appliquent à tous les programmes et projets statistiques menés par Statistique Canada qui utilisent des algorithmes d'apprentissage automatique, particulièrement ceux mis en production. Cela comprend les algorithmes d'apprentissage supervisé et non supervisé.
Le thème respect des personnes est décrit à l'aide de quatre attributs.
- Le concept de valeur pour les Canadiens dans un contexte d'apprentissage automatique implique que son utilisation doit avoir une valeur ajoutée, que ce soit dans les produits eux-mêmes ou par une plus grande efficacité dans le processus de production.
- La prévention des préjudices nécessite d'être au courant des dangers potentiels et d'avoir un dialogue constructif avec les intervenants et les porte-paroles du milieu avant la mise en œuvre d'un projet d'apprentissage automatique.
- L'équité implique que le principe de la proportionnalité entre les moyens et les fins soit respecté, et qu'un équilibre soit maintenu entre des intérêts et des objectifs différents. L'équité veille à ce que les personnes et les groupes ne soient pas victimes de préjugés injustes, de discrimination ou de stigmatisation.
- L'imputabilité est l'obligation juridique et éthique d'une personne ou d'une organisation d'être responsable de son travail et de communiquer les résultats du travail de façon transparente. Les algorithmes ne sont pas responsables; quelqu'un est responsable des algorithmes.
Statistique Canada prend les données au sérieux. Le thème respect des données a trois attributs : la protection de la vie privée des personnes auxquelles les données appartiennent; la sécurité des renseignements tout au long du cycle de vie des données; et la confidentialité de renseignements identifiables.
- La vie privée est le droit de se retirer et de ne pas être sujet à une quelconque forme de surveillance ou d'intrusion. Lors de l'acquisition de renseignements de nature délicate, les gouvernements ont des obligations relativement à la collecte, à l'utilisation, à la divulgation et à la conservation des renseignements personnels. Le terme vie privée réfère généralement à des renseignements concernant des particuliers (définition tirée de Politique sur la protection des renseignements personnels et la confidentialité).
- La sécurité représente les dispositions fondées sur l'évaluation de la menace et des risques qu'utilisent les organisations pour empêcher l'obtention ou la divulgation inadéquate de renseignements confidentiels. Les mesures de sécurité protègent aussi l'intégrité, la disponibilité et la valeur des fonds de renseignements. Cela englobe les protections matérielles, comme l'accès restreint aux zones où les renseignements sont entreposés et utilisés ou les autorisations de sécurité des employés, ainsi que les protections technologiques utilisées pour empêcher l'accès électronique non autorisé (définition tirée de la Politique sur la protection des renseignements personnels et la confidentialité).
- La confidentialité fait référence à la protection contre la divulgation de renseignements personnels identifiables concernant une personne, une entreprise ou une organisation. La confidentialité suppose une relation de « confiance » entre le fournisseur de renseignements et l'organisation qui les recueille; cette relation s'appuie sur l'assurance que ces renseignements ne seront pas divulgués sans l'autorisation de la personne ou sans l'autorité législative appropriée (définition tirée de la Politique sur la protection des renseignements personnels et la confidentialité).
Une application rigoureuse signifie de mettre en place, de maintenir et de documenter les processus d'apprentissage automatique de façon à ce que les résultats soient toujours fiables et que l'ensemble du processus puisse être compris et recréé. Ce thème a deux attributs : la transparence et la reproductibilité du processus et des résultats.
- La transparence fait référence au fait d'avoir une justification claire de la raison pour laquelle cet algorithme et les données d'apprentissage sont les plus appropriés pour l'étude en cours. Pour être transparents, les développeurs devraient produire une documentation complète, y compris rendre accessible le code informatique à d'autres personnes, et ce, sans compromettre la confidentialité ou la protection des renseignements personnels.
- La reproductibilité du processus signifie qu'il y a suffisamment de documentation et que le code informatique a été suffisamment partagé pour faire en sorte que le processus soit reproduit, à partir de rien. La reproductibilité des résultats signifie que les mêmes résultats peuvent être reproduits de façon fiable lorsque toutes les conditions sont contrôlées. Il n'y a pas d'étapes qui modifient les résultats à la suite d'une intervention ponctuelle ou humaine.
Les méthodes éprouvées sont celles qui peuvent être invoquées de manière efficace et efficiente afin de produire les résultats espérés. Statistique Canada suit habituellement des protocoles reconnus qui comportent une consultation avec des pairs et des experts, de la documentation et des tests lorsque nous élaborons des méthodes éprouvées. Ce thème a quatre attributs : la qualité des données d'apprentissage; l'inférence valide; la modélisation rigoureuse; l'explicabilité.
- Dans un contexte d'apprentissage automatique, la qualité des données d'apprentissage est mesurée par la cohérence et l'exactitude des données étiquetées. La couverture, ce qui signifie que les étiquettes et les descriptions couvrent tous les cas auxquels l'algorithme peut faire face dans la production, est également importante pour réduire le risque de partialité ou de discrimination (équité). La couverture est également importante pour assurer la représentativité des variables, ce qui est important lorsqu'on veut obtenir des mesures de rendement réalistes.
- Une inférence valide désigne la capacité d'obtenir, à partir d'un échantillon, des conclusions plausibles et d'une précision connue de la population cible. Dans un contexte d'apprentissage automatique, une conclusion valable signifie que les prédictions à partir de données tests (jamais utilisées pour la modélisation) doivent être, dans une grande proportion, raisonnablement près de leurs vraies valeurs ou, dans le cas de données catégoriques, les prédictions sont exactes dans une grande proportion.
- Une modélisation rigoureuse en apprentissage automatique consiste à s'assurer que les algorithmes sont vérifiés et validés. Cela permettra aux utilisateurs et aux décideurs de faire confiance à l'algorithme à juste titre du point de vue de l'adaptation des données à leur utilisation, de la fiabilité et de la robustesse.
- Un modèle qui est explicable est un modèle qui est suffisamment documenté. Les documents doivent expliquer clairement de quelle façon les résultats devraient être utilisés et permettre de déterminer quelles conclusions on peut tirer ou encore ce qui devrait être exploré plus en profondeur. En d'autres mots, un modèle explicable n'est pas une boîte noire.
Processus de revue
Le processus de revue constitue la mise en œuvre du Cadre. L'accent est mis sur les projets ayant des visées pour l'utilisation de méthodes d'apprentissage automatique dans une ou plusieurs étapes menant à la production de statistiques officielles. Le processus comprend trois étapes : l'auto-évaluation à l'aide de la liste de contrôle; l'évaluation par des pairs; une présentation du projet au comité d'examen scientifique de la Direction des méthodes statistiques modernes et de la science des données.
Dans un premier temps, l'équipe ayant développé le projet à l'aide de méthodes d'apprentissage automatique devra faire une auto-évaluation concernant l'utilisation de ces techniques. Pour se faire, l'équipe devra prendre connaissance du Cadre et répondre aux questions présentes dans la liste de contrôle. La liste de contrôle prend la forme d'un questionnaire où, de façon générale, chaque ligne directrice du Cadre est reformulée sous forme d'une ou plusieurs questions. Par la suite, ce questionnaire et la documentation du projet et des méthodes utilisées sont envoyés à l'équipe de revue.
L'évaluation par les pairs peut maintenant débuter. Des réviseurs provenant de deux équipes différentes seront impliqués. Les questions et la documentation concernant les deux premiers thèmes du Cadre, respect des personnes et respect des données, seront évaluées par l'équipe du Secrétariat de l'éthique des données alors que la partie concernant les deux derniers thèmes, application rigoureuse et méthodes éprouvées, sera évaluée par une équipe de la section des méthodes et de la qualité en science des données. À la fin de cette évaluation, un rapport contenant des recommandations sera envoyé au gestionnaire du projet.
La dernière étape du processus de revue est la présentation du projet au comité d'examen scientifique de la Direction des méthodes statistiques modernes et de la science des données. Cette présentation expose la méthodologie utilisée lors du processus d'apprentissage automatique devant un comité d'experts. Le rôle de ce comité est de remettre en question la méthodologie notamment en identifiant certaines lacunes ou problèmes potentiels et en proposant des améliorations et des corrections. Ultimement, ce comité recommandera ou non la mise en œuvre de la méthodologie proposée dans le contexte de production de statistiques officielles.
Et après?
Est-ce la fin de l'histoire? Non, en fait c'est plutôt le début. De nouvelles sources de données et méthodes d'apprentissage automatique émergent pratiquement chaque jour. Afin de demeurer pertinent, le Cadre présenté dans cet article devra être fréquemment adapté et révisé pour tenir compte des nouveaux enjeux d'éthique et de qualité. Statistique Canada continue à appliquer ce Cadre aux processus qui utilisent l'apprentissage automatique et est à l'affût d'applications où la Directive sur la prise de décisions automatisée pourrait s'appliquer. L'agence va constituer un registre de toutes les applications qui ont passé ce processus de revue pour pouvoir y référer facilement. Et vous, faites-vous face à des questions concernant l'utilisation responsable de certaines méthodes d'apprentissage automatique? Avez-vous déjà appliqué la Directive du Secrétariat du Conseil du trésor et avez-vous déjà dû obtenir une évaluation indépendante d'une de vos applications? À Statistique Canada nous avons déjà fait ce genre de revue pour un autre ministère à l'aide du Cadre discuté dans cet article et sommes disponibles pour faire d'autres revues si le besoin se présente. Veuillez contacter statcan.dscd-ml-review-dscd-revue-aa.statcan@statcan.gc.ca.
- Date de modification :