Le Recensement de l'agriculture offre un portrait statistique de l'industrie de l'agriculture canadienne ainsi que des exploitants agricoles et de leur famille.
AVIS IMPORTANT : Trouvez le dernier contenu du Recensement de l'agriculture sur notre nouveau portail ici : Recensement de l'agriculture.
Les enquêtes de Statistique Canada sont menées en personne, par téléphone ou en ligne. Pour la plupart des enquêtes, Statistique Canada envoie d'abord une lettre ou un courriel d'invitation pour vous informer de l'objectif de l'enquête et vous indiquer qu'un commis à la collecte de données communiquera avec vous.
Si vous n'avez pas reçu de lettre ou de courriel de ce genre, vous pouvez vérifier que l'enquête est bien menée par Statistique Canada en :
*Si vous utilisez un service de relais téléphonique, vous pouvez nous appeler pendant les heures normales de bureau. Il n'est pas nécessaire d'autoriser le téléphoniste à communiquer avec nous.
Statistique Canada valorise le bien-être de l'ensemble du personnel et des répondants dans toutes les communications. Aucun comportement agressif ou abusif ne sera toléré.
Les répondants reconnaissent qu'en utilisant un service de relais téléphonique et en fournissant leurs renseignements personnels au téléphoniste, qu'ils peuvent être assujettis aux conditions d'utilisation du service de relais. Veuillez noter que le téléphoniste n'est pas assujetti aux règles de confidentialité de Statistique Canada.
Ne vous étonnez pas si un employé de Statistique Canada se présente à votre porte ou communique avec vous par téléphone en soirée ou les fins de semaine. Pour s'adapter aux horaires chargés des répondants, les employés de Statistique Canada travaillent à différentes heures de la journée, sept jours par semaine et parfois les jours fériés. Dans le cas d'une enquête téléphonique, il se peut que l'on vous appelle de différentes régions du Canada.
Les employés de Statistique Canada ne sollicitent pas de numéro d'assurance sociale ni de renseignements bancaires ou de cartes de crédit.
Comment m'a-t-on choisi·e?
Comment m'a-t-on choisi?
Tous les ménages canadiens reçoivent le questionnaire du Recensement de la population.
Toute personne responsable d'une exploitation agricole déclarant des revenus ou des dépenses à l'Agence du revenu du Canada doit remplir un questionnaire du Recensement de l'agriculture.
La majorité des enquêtes de Statistique Canada sont des enquêtes sur échantillon. Les participants à ces enquêtes sont choisis au hasard afin d'éviter tout biais. Lorsque vous êtes sélectionné·e pour faire partie de l'échantillon d'une enquête, Statistique Canada ne peut vous remplacer par quelqu'un d'autre, car il ne s'agirait plus d'un échantillon pris au hasard.
J'ai déjà participé à une enquête de Statistique Canada. Pourquoi m'avez-vous sélectionné·e pour une autre enquête?
Cela peut arriver parce que les participants aux enquêtes sont choisis au hasard. Parfois, les caractéristiques que nous recherchons peuvent être les mêmes d'une enquête à l'autre.
Dans certains cas, on peut communiquer de nouveau avec une partie des participants à une enquête pour mener une enquête connexe. Cette façon de faire permet de réduire le temps et les dépenses qui seraient nécessaires pour mener chaque fois une nouvelle enquête.
Comment choisit-on les entreprises ou les exploitations agricoles en vue d'une enquête?
La majorité des enquêtes que Statistique Canada mène auprès des entreprises ou des exploitations agricoles sont des enquêtes sur échantillon. Cela veut dire que seulement un certain nombre d'entreprises ou d'exploitations agricoles d'un secteur d'activité particulier sont choisies dans chaque province et territoire pour remplir le questionnaire d'enquête. Cet échantillon représente toutes les entreprises ou exploitations agricoles du secteur étudié. Dans un échantillon, la plupart des entreprises ou exploitations agricoles sont choisies de façon aléatoire afin de représenter d'autres entreprises ou exploitations agricoles possédant des caractéristiques semblables ayant trait, par exemple, au revenu ou au nombre d'employés. Certaines entreprises ou exploitations agricoles doivent être retenues dans l'échantillon parce qu'elles contribuent de façon significative à l'activité d'un secteur ou d'une région.
Un nombre limité de nos enquêtes menées auprès des entreprises ou des exploitations agricoles sont de type recensement, c'est-à-dire qu'elles incluent toutes les entreprises ou exploitations agricoles de taille notable au sein d'un secteur d'activité particulier. On utilise un recensement lorsque le secteur étudié ne comprend qu'un nombre limité d'entreprises ou d'exploitations agricoles ou lorsqu'il se compose d'entreprises ou d'exploitations agricoles très dissemblables. Dans de tels cas, un échantillon ne refléterait pas fidèlement la totalité du secteur étudié.
Dois-je participer?
Dois-je participer?
La participation au Recensement de la population et au Recensement de l'agriculture est obligatoire en vertu de la Loi sur la statistique. Tous les ménages canadiens doivent remplir le questionnaire du Recensement de la population. Tous les exploitants agricoles doivent remplir le questionnaire du Recensement de l'agriculture.
Si Statistique Canada communique avec vous pour vous demander de prendre part à l'Enquête sur la population active, votre participation est également obligatoire en vertu de la Loi sur la statistique. En outre, la participation à la plupart des enquêtes entreprises et agricoles est obligatoire.
Les autres enquêtes de Statistique Canada sont à participation volontaire.
Votre participation est importante.
Pour obtenir les résultats les plus complets, il est très important que les personnes, les ménages, les entreprises et les exploitations agricoles sélectionnés répondent aux questions d'enquête. Sans votre collaboration, Statistique Canada ne pourrait pas produire de données fiables et essentielles.
Les renseignements recueillis dans nos enquêtes ont des conséquences directes sur la vie des Canadiens. De plus, toutes vos réponses ont la même importance. Par exemple, pour produire des données exactes et objectives sur l'utilisation d'Internet au Canada, les réponses des gens qui n'utilisent pas d'Internet ont autant d'importance que les réponses des personnes qui s'en servent.
Pourquoi les entreprises et les exploitations agricoles sont-elles légalement tenues de répondre aux enquêtes?
Les Canadiens ont besoin de données exactes et fiables pouvant servir de fondement au processus démocratique de prise de décisions. Par la Loi sur la statistique, le Parlement a chargé Statistique Canada, à titre d'organisme national de la statistique, de recueillir ce genre de données.
Les enquêtes menées auprès des entreprises et des exploitations agricoles permettent de recueillir d'importantes données économiques. Celles-ci sont utilisées par les entreprises, les syndicats, les organismes à but non lucratif et tous les ordres de gouvernement pour leur permettre de prendre des décisions éclairées dans plusieurs domaines.
Puisque les résultats de la plupart des enquêtes-entreprises et enquêtes agricoles sont liés directement ou indirectement à des programmes autorisés par la loi, il est nécessaire de rendre obligatoire la participation à ces enquêtes afin d'assurer un taux de réponse adéquat ainsi que des données fiables.
Comment est-ce que Statistique Canada communiquera avec moi?
Comment est-ce que Statistique Canada communiquera avec moi?
Statistique Canada pourrait communiquer avec vous de diverses façons en utilisant les deux langues officielles. Nos employés travaillent les jours, les soirées, les fins de semaine et même parfois les jours fériés pour s'adapter aux horaires des répondants. Nous communiquons avec les répondants en :
envoyant des lettres;
appelant des numéros de téléphone fixe ou cellulaire;
envoyant des courriels;
envoyant des textos;
Les numéros abrégés SMS de Statistique Canada utilisés pour tous nos messages textes sont le 782-782 et le 236-732. Des frais de messages standard peuvent s'appliquer. Si vous recevez un message texte d'un autre numéro prétendant être celui de Statistique Canada, ce message n'est pas authentique. De plus, tous les messages texte provenant de Statistique Canada sont envoyés en anglais et en français.
visitant en personne le lieu de résidence;
Si un employé se rend à votre lieu de résidence et que vous n'êtes pas disponible, il peut également laisser une note ou une lettre pour vous informer de sa visite.
envoyant des notifications à partir des applications mobiles officielles de Statistique Canada.
Ces notifications seront envoyées uniquement aux utilisateurs qui ont téléchargé l'application mobile et activé les notifications.
Comment puis-je confirmer l'identité d'un employé, ou la légitimité d'un appel téléphonique, d'un message texte ou d'un courriel reçu ?
Comment puis-je confirmer l'identité d'un intervieweur ou la légitimité d'un appel, d'un texto ou d'un courriel que j'ai reçu?
Tous les commis à la collecte de données portent une carte d'identité avec photo délivrée par Statistique Canada. Vous pouvez vérifier l'identité d'un employé en recherchant son nom dans GCannuaire. Pour confirmer la légitimité d'un appel, d'un message texte ou d'un courriel, vous pouvez communiquer avec Statistique Canada en composant l'un des numéros ci-après.
Demandes de renseignements généraux
1-877-949-9492
Ligne ATS : 1-800-363-7629
Demandes en lien avec la participation aux enquêtes
1-833-977-8287
Ligne ATS : 1-866-753-7083
Si vous avez été sélectionné·e pour participer à une enquête, Statistique Canada vous appellera généralement à partir du numéro 1-833-977-8287, les messages texte seront envoyés du 782-782 ou du 236-732 (Des frais de messages standard peuvent s'appliquer), et les courriels proviendront des domaines @statcan.gc.ca ou @canada.ca.
Veuillez noter qu'il est possible que le numéro de téléphone s'affiche sur votre téléphone comme provenant des États-Unis. Cette situation est hors de notre contrôle et est directement liée à un accord nord-américain sur la téléphonie et la répartition des appels. Si vous doutez de la légitimité d'une enquête ou d'un employé, nous vous encourageons à communiquer avec nous pour confirmer.
Comment protège-t-on ma vie privée et mes renseignements personnels?
Comment protège-t-on ma vie privée et mes renseignements personnels?
Statistique Canada prend la confidentialité des renseignements qui vous concernent très au sérieux. Conformément à la Loi sur la statistique, tous les renseignements fournis à Statistique Canada seront tenus confidentiels et utilisés seulement à des fins statistiques.
Statistique Canada se préoccupe aussi du respect de la vie privée des répondants. Si un répondant connaît le commis à la collecte de données et qu'il est mal à l'aise de lui communiquer des renseignements personnels, le répondant peut choisir d'être interviewé par un autre employé de Statistique Canada.
Vos réponses sont confidentielles.
La Loi sur la statistique protège les renseignements des répondants. Statistique Canada ne divulgue pas de renseignements qui pourraient permettre d'identifier des personnes, des ménages, des entreprises, des exploitations agricoles ou autres organisations à moins d'avoir obtenu leur consentement, ou tel que permis par la Loi sur la statistique. Nous examinons minutieusement les résultats finaux avant leur diffusion afin d'éviter que les statistiques publiées ne puissent être utilisées de façon à déduire quelque information que ce soit.
La Loi sur la statistique renferme des dispositions très strictes qui protègent la confidentialité des renseignements recueillis contre tout accès non autorisé. À titre d'exemple, l'Agence du revenu du Canada, la Gendarmerie royale du Canada (GRC) et les tribunaux ne peuvent obtenir les réponses fournies aux enquêtes.
Tous les employés de Statistique Canada ont prêté un serment de discrétion et s'exposent à des peines sévères pour toute violation du secret professionnel.
L'accès est strictement contrôlé.
Tous les employés de Statistique Canada sont tenus de protéger la confidentialité des données recueillies. Seuls les employés qui doivent consulter les dossiers confidentiels pour mener leur tâche à bien sont autorisés à en prendre connaissance. Un ensemble de systèmes et de procédures interdit tout accès non autorisé aux renseignements confidentiels.
Les données confidentielles sont traitées et stockées sur un réseau interne dont les paramètres sont strictement contrôlés afin d'empêcher le piratage informatique.
Je reçois des appels de Statistique Canada qui ne s'affichent pas comme tels. Pourquoi?
Je reçois des appels de Statistique Canada qui ne s'affichent pas comme tel. Pourquoi?
Comme Statistique Canada fait appel à plusieurs fournisseurs de services téléphoniques à l'échelle du pays, l'option d'affichage des appels n'est pas toujours offerte, et les appels provenant des commis à la collecte de données ou des centres d'appels peuvent être désignés comme des appels « inconnus ». Il est également possible que le numéro de téléphone d'un commis à la collecte de données de Statistique Canada s'affiche sur votre téléphone comme provenant des États-Unis. Cette situation est hors de notre contrôle et est directement liée à un accord nord-américain sur la téléphonie et la répartition des appels.
En outre, plus d'un commis à la collecte de données peut tenter de communiquer avec vous à partir d'un téléphone portable, auquel cas votre afficheur peut vous présenter plusieurs noms et numéros de téléphone.
C'est pourquoi nos appels ne peuvent pas tous s'afficher comme étant de Statistique Canada ou du Gouvernement du Canada.
Si vous doutez de la légitimité d'une enquête ou d'un employé, nous vous encourageons à communiquer avec nous pour confirmer.
Comment puis-je avoir accès aux résultats publiés par Statistique Canada?
Comment puis-je avoir accès aux résultats publiés par Statistique Canada?
Vous trouverez des résultats sous le lien « données publiées » sur la page principale de chacune de nos enquêtes en cours.
Le Quotidien : Le Quotidien est le bulletin de diffusion officielle de Statistique Canada. On y trouve chaque jour ouvrable des résultats d'enquêtes de Statistique Canada. L'archivage permet également de consulter les renseignements diffusés antérieurement.
Le Recensement de la population : Ce module dresse le portrait statistique du Canada et de ses habitants. Vous y retrouverez également les plus récentes données sur le Recensement de 2021.
Mon StatCan : Mon StatCan est un portail complet et personnalisable qui vous permet de mettre un signet à vos articles, rapports, tableaux de données, indicateurs et autres favoris pour y avoir accès rapidement; de recevoir par courriel les avis portant sur les données les plus récentes que nous avons diffusées. Pour obtenir plus de renseignements sur les publications et les produits :
Numéro sans frais (Canada et États-Unis) : 1-800-263-1136
Est-ce que Statistique Canada est exempté de la Liste nationale de numéros de télécommunication exclus?
Est-ce que Statistique Canada est exempté de la liste nationale de numéro de télécommunication exclus?
Statistique Canada tient à informer les clients et les répondants à ses enquêtes qu'il fait partie des organisations exclues de la Liste nationale de numéros de télécommunication exclus (LNNTE).
La LNNTE a été lancée par le Conseil de la radiodiffusion et des télécommunications canadiennes (CRTC) afin de limiter le nombre d'appels de télémarketing.
En somme, les personnes sélectionnées pour les enquêtes de Statistique Canada seront contactées par l'organisme, et ce, même si ces dernières ont enregistré leur numéro de téléphone sur la LNNTE.
En vertu de la Loi sur la statistique, Statistique Canada collecte des données pour fournir aux Canadiens de l'information fiable sur notre société, notre économie et notre population.
Le succès du système statistique du Canada repose sur un partenariat bien établi entre Statistique Canada et la population, les entreprises, les administrations canadiennes et les autres organismes. Sans cette collaboration et cette bonne volonté, il serait impossible de produire des statistiques précises et actuelles.
Pour obtenir plus de renseignements, communiquez avec nos agents au 1-800-263-1136 ou à infostats@statcan.gc.ca.
Les questionnaires en ligne de Statistique Canada permettent-ils d'utiliser la fonction de traduction des navigateurs Web?
Les questionnaires en ligne de Statistique Canada permettent-ils les traductions par les navigateurs Web?
Toutes nos enquêtes sont disponibles en français et en anglais. Nous encourageons les répondants à utiliser le bouton de langue intégré à nos questionnaires pour passer de l'anglais au français, plutôt que d'utiliser la fonction de traduction de leur navigateur. Malheureusement, lorsqu'un navigateur traduit nos questionnaires, il peut produire des traductions incorrectes.
Pourquoi les numéros des questions dans les questionnaires d'enquête n'apparaissent-ils pas toujours dans l'ordre numérique?
Pourquoi les numéros des questions dans les questionnaires d'enquête n'apparaissent-ils pas toujours dans l'ordre numérique?
Les questionnaires d'enquête peuvent utiliser deux formats différents de numérotation des questions. Ils peuvent être numérotés par ordre numérique, de la première à la dernière question, ou chaque section du questionnaire peut recommencer la numérotation à la question 1. Le second format peut générer plusieurs occurrences du même numéro de question dans le questionnaire.
En fonction des réponses fournies tout au long du questionnaire, certaines questions et leurs numéros correspondants pourraient être passés..
Que fait Statistique Canada pour faciliter la tâche des répondants?
Que fait Statistique Canada pour faciliter la tâche des répondants?
Statistique Canada cherche à trouver un équilibre entre le fardeau de réponse imposé aux entreprises et le besoin d'obtenir des statistiques sur les industries et des indicateurs économiques de qualité.
Recours à d'autres sources que les enquêtes pour l'obtention des données
Statistique Canada a beaucoup réduit le fardeau de réponse lié aux enquêtes en ayant recours à des données administratives que les entreprises et les exploitations agricoles fournissent déjà au gouvernement, telles que les déclarations de revenus et les documents relatifs à la paie des employés.
Enquêtes mensuelles moins nombreuses et plus rapides
Les enquêtes mensuelles fournissent des données actuelles permettant de suivre l'évolution des prix, du commerce, de la fabrication et de l'emploi. Statistique Canada s'efforce de rendre les questionnaires faciles à remplir et de les garder aussi courts que possible. Au cours des dernières années, Statistique Canada a réduit considérablement la taille des échantillons des enquêtes mensuelles en utilisant des données administratives.
Déclaration électronique
Pour plusieurs enquêtes-entreprises, Statistique Canada offre aux répondants la possibilité de déclarer leurs données par Internet. La déclaration électronique permet aux entreprises d'extraire directement l'information de leurs systèmes de données ou de remplir un questionnaire en ligne et de le transmettre à Statistique Canada. Des mesures de protection rigoureuses sont alors fournies afin d'assurer la confidentialité des données.
Modalités de participation personnalisées
Les grandes entreprises actives dans diverses industries et provinces peuvent choisir des modalités de participation personnalisées au Programme intégré de la statistique des entreprises. Par exemple, une telle entreprise peut recevoir à son siège social tous les questionnaires concernant ses succursales. Elle peut également décider de recevoir, pour chaque province et pour chaque industrie où elle exerce ses activités, un questionnaire combiné visant toutes ses succursales œuvrant dans cette province ou cette industrie.
Qu'est-ce que le Programme intégré de la statistique des entreprises?
Qu'est-ce que le Programme intégré de la statistique des entreprises?
Le Programme intégré de la statistique des entreprises (PISE) est une initiative menée par Statistique Canada pour garantir la cohérence et la qualité des données à l'échelle de son programme de statistiques économiques et produire une image cohérente de l'économie canadienne. Cette initiative intègre des enquêtes-entreprises en un seul cadre de travail en utilisant des questionnaires et des guides de déclaration semblables en ce qui a trait à la présentation, à la structure et au contenu.
Les questionnaires types du PISE permettent de recueillir des données homogènes auprès d'entreprises de différentes industries. Le regroupement des résultats permet d'obtenir des statistiques plus cohérentes et plus précises sur l'économie, plus particulièrement à l'échelle provinciale et territoriale ainsi qu'au niveau des industries.
L'approche intégrée rend la déclaration plus facile pour les entreprises ayant des activités dans différentes industries, puisqu'elles fournissent des renseignements similaires pour chacune de leurs succursales. Cette approche leur évite d'avoir à répondre, pour chaque industrie, à des questionnaires qui diffèrent en ce qui a trait au format, à la formulation des questions et même aux concepts.
Pourquoi Statistique Canada n'obtient-il pas l'ensemble des renseignements financiers des entreprises de l'Agence du revenu du Canada?
Pourquoi Statistique Canada n'obtient-il pas l'ensemble des renseignements financiers des entreprises de l'Agence du revenu du Canada?
Dans la mesure du possible, Statistique Canada utilise les données administratives qui sont déjà entre les mains du gouvernement, telles que les déclarations de revenus.
Toutefois, ces dossiers ne contiennent pas toutes les données nécessaires pour produire un profil adéquat d'une industrie. On observe plus particulièrement cette situation dans le cas de grandes entreprises dont les activités se déroulent dans différentes industries et dans plus d'une province.
Statistique Canada ne partage aucune donnée individuelle d'enquête avec l'Agence du revenu du Canada.
Les renseignements fournis par les entreprises seront-ils partagés?
Les renseignements fournis par les entreprises seront-ils partagés?
La Loi sur la statistique interdit à Statistique Canada de diffuser tout renseignement permettant d'identifier une personne, un ménage, une entreprise ou une exploitation agricole. Toutefois, la collecte conjointe et le partage des données d'enquête avec de tierces parties sont permis dans certaines circonstances prévues par la Loi sur la statistique.
Ententes de partage de données
Pour éviter la redondance des enquêtes, Statistique Canada conclut parfois des ententes de collecte conjointe et de partage des données avec des ministères fédéraux ou provinciaux ainsi qu'avec d'autres organismes. Cela réduit le fardeau administratif imposé aux entreprises.
Dans de tels cas, Statistique Canada doit, au moment de la collecte, indiquer aux répondants si une entente de partage de données s'applique aux renseignements qu'ils fournissent, et avec quel organisme leurs renseignements seront partagés. Statistique Canada doit également informer les répondants de tout droit qu'ils pourraient avoir, en vertu de la Loi sur la statistique, de refuser de partager les renseignements fournis.
Couplage de microdonnées
Pour améliorer les données et réduire au minimum le fardeau de réponse, Statistique Canada pourrait combiner les renseignements recueillis au moyen d'une enquête avec ceux provenant d'autres enquêtes ou de sources des données administratives.
Renonciations à la confidentialité
Statistique Canada peut divulguer les renseignements permettant d'identifier un répondant si celui-ci y a consenti par écrit. La Loi sur la statistique permet également au statisticien en chef d'autoriser la divulgation de certaines données relatives aux entreprises et aux organismes — sans le consentement du répondant — dans des situations précises et limitées.
Renseignements recueillis en vertu de la Loi sur les déclarations des personnes morales
Outre le mandat principal qui lui est confié en vertu de la Loi sur la statistique, Statistique Canada est également responsable de l'application de la Loi sur les déclarations des personnes morales. L'objectif de cette loi est de surveiller l'ampleur de la propriété étrangère des sociétés canadiennes.
Les enquêtes menées en vertu de la Loi sur les déclarations des personnes morales constituent les seuls cas où Statistique Canada est autorisé à diffuser certains renseignements non financiers concernant des sociétés précises. Il s'agit de renseignements relatifs à la propriété, à la province d'établissement, à la nationalité des capitaux majoritaires et à la classification industrielle.
L'Agence du revenu du Canada n'a pas accès aux données individuelles d'enquête
La Loi sur la statistique permet à Statistique Canada d'obtenir des dossiers de l'Agence du revenu du Canada pour réduire le fardeau administratif imposé par le gouvernement. Toutefois, le contraire ne s'applique pas : l'Agence du revenu du Canada n'a pas accès aux dossiers individuels de Statistique Canada et ne fait partie d'aucune entente de partage de données avec Statistique Canada.
Qui utilise les résultats des enquêtes-entreprises?
Qui utilise les résultats des enquêtes-entreprises?
Les entreprises bénéficient directement des renseignements qu'elles fournissent à Statistique Canada. Les données d'enquête servent à compiler des statistiques complètes et exactes sur de nombreux produits et industries.
Les entreprises utilisent les données pour :
comparer leur rendement aux moyennes de l'industrie;
préparer des plans d'activités pour les investisseurs;
rajuster les contrats indexés en fonction de l'inflation;
préparer des stratégies de marketing et évaluer les occasions d'expansion.
Les associations industrielles, les analystes commerciaux et les investisseurs utilisent les données pour :
établir des points de repère afin d'analyser le rendement économique de diverses industries;
comprendre les environnements commerciaux qui évoluent rapidement, tels que les réseaux de communication mondiaux, le libre-échange et les nouvelles technologies.
Les gouvernements utilisent les données pour prendre des décisions sur :
les investissements dans les infrastructures afin de favoriser la compétitivité sur la scène nationale et internationale;
les politiques budgétaires, monétaires et de change;
les programmes et les politiques qui viennent en aide aux entreprises;
les transferts fiscaux et les paiements de péréquation fédéraux-provinciaux.
Ombudsman pour les répondants aux enquêtes-entreprises
Ombudsman pour les répondants aux enquêtes-entreprises
Statistique Canada travaille sans relâche à réduire le fardeau de réponse et offre les services d'un ombudsman pour les entreprises afin de soutenir les participants aux enquêtes-entreprises.
L'ombudsman étudie les plaintes des participants aux enquêtes-entreprises qui croient avoir un fardeau de réponse trop élevé ou qui croient que Statistique Canada a agi de façon peu professionnelle envers eux. Les services de l'ombudsman sont impartiaux et gratuits.
Efforts de réduction du fardeau de réponse
Efforts de réduction du fardeau de réponse
Statistique Canada travaille depuis longtemps à gérer et à réduire le fardeau pour ses répondants, car leur contribution est essentielle et fort appréciée. Grâce à la coopération assidue des répondants, l'organisme parvient à traiter les données d'enquête et à produire des renseignements fiables. Ces renseignements permettent aux décideurs de faire leur travail de façon plus éclairée et ainsi de mieux servir l'ensemble des Canadiens.
Statistique Canada prend des mesures pour alléger le fardeau de réponse des entreprises
Statistique Canada vise à réduire le temps que les entreprises consacrent à répondre aux enquêtes, que ce soit en :
diminuant le nombre d'enquêtes ou le nombre de questions;
limitant la période pendant laquelle l'entreprise fait partie de l'échantillon;
utilisant des méthodes plus conviviales de collecte de données.
Réduction de la redondance des demandes de données gouvernementales
Statistique Canada vise à réduire la redondance des demandes de renseignements des ministères et organismes fédéraux par les moyens suivants :
continuer de collaborer avec l'Agence du revenu du Canada afin de remplacer des données d'enquêtes par des données fiscales que les entreprises ont déjà fournies;
évaluer s'il est possible de remplacer les données d'enquêtes par des données provenant d'autres sources;
travailler avec d'autres organismes gouvernementaux afin d'étudier les possibilités de remplacer les enquêtes par des données administratives ou autres comme la télédétection ou la traçabilité;
collaborer avec d'autres ministères fédéraux afin d'harmoniser et de coordonner les besoins en information.
Répit d'enquêtes pour les petites entreprises
Le 1er janvier 2015, Statistique Canada a mis en œuvre l'Initiative sur le fardeau de réponse cumulatif (IFRC) afin d'alléger le fardeau de réponse des petites entreprises ayant un bon dossier de déclaration.
Ce programme offre un an de répit de toute participation lorsque des seuils préétablis de fardeau de réponse ont été franchis. Le programme s'inscrit dans la stratégie d'ensemble de Statistique Canada qui, sans altérer grandement la qualité de ses produits statistiques, vise à :
réduire le nombre de questionnaires envoyés aux petites entreprises;
limiter les périodes durant lesquelles une petite entreprise doit faire partie d'un échantillon.
Communications avec les répondants
Communications avec les répondants
Afin de réduire la frustration des entreprises et de procurer aux intervenants des renseignements pertinents, Statistique Canada examine et met à jour ses outils de communication pour :
expliquer l'importance et l'utilité des enquêtes-entreprises aux répondants;
améliorer la compréhension des répondants quant au lien entre les renseignements recueillis et les bienfaits et utilisations des statistiques;
améliorer son site Web et y augmenter la visibilité et le contenu destiné aux participants aux enquêtes;
sensibiliser davantage le public quant aux initiatives en cours pour réduire le fardeau de réponse.
Questions propres aux enquêtes-ménages
Information sur les enquêtes menées auprès des ménages
Les renseignements fournis par les répondants seront-ils partagés?
Les renseignements fournis par les répondants seront-ils partagés?
Statistique Canada s'engage à respecter les renseignements personnels de tous. La Loi sur la statistique interdit à Statistique Canada de diffuser tout renseignement identifiant ou permettant d'identifier une personne. Toutefois, la collecte conjointe et le partage des données d'enquête avec des tierces parties sont permis dans certaines circonstances prévues par la Loi sur la statistique.
Ententes de partage de données
Pour éviter les chevauchements d'enquêtes, Statistique Canada conclut parfois des ententes de collecte conjointe et de partage des données avec des ministères fédéraux ou provinciaux ainsi qu'avec d'autres organismes. Les réponses d'une personne à une enquête ne seront partagées qu'avec son consentement.
Couplages de microdonnées
Le couplage de données d'enquête et de données administratives est un élément clé permettant de réduire le fardeau de réponse et d'améliorer la qualité et l'uniformité des données des enquêtes-ménages. Statistique Canada informe les répondants du couplage de leurs réponses aux renseignements d'autres enquêtes ou aux données administratives. Les répondants sont également avisés de la possibilité de couplage éventuel de leurs réponses avec d'autres données. De plus, Statistique Canada applique un processus d'examen et d'approbation bien défini à l'égard de tous les couplages.
Consentement à la divulgation
Conformément à la Loi sur la statistique, Statistique Canada est autorisé à divulguer les renseignements permettant d'identifier un répondant si celui-ci y a consenti par écrit.
Qui utilise les résultats des enquêtes-ménages?
Qui utilise les résultats des enquêtes-ménages?
Les données recueillies par Statistique Canada sont utilisées par un certain nombre de personnes ou d'organismes, notamment :
les divers échelons de gouvernement (fédéral, provincial, territorial et municipal);
les organismes communautaires, les éducateurs et les chercheurs;
les urbanistes et les décideurs.
Concepts pour les enquêtes-ménages
Quelle est la différence entre un logement, une famille et un ménage?
Quelle est la différence entre un logement, une famille et un ménage?
Un logement est un ensemble de pièces d'habitation structurellement distinctes qui a une entrée privée à l'extérieur de l'immeuble, ou à partir d'un couloir commun ou d'un escalier à l'intérieur de l'immeuble.
Une famille est un groupe de deux personnes ou plus qui habitent le même logement et qui ont des liens de parenté par le sang, le mariage (y compris l'union libre) ou l'adoption. Une personne qui habite seule ou qui n'a de lien avec personne d'autre dans le logement où elle habite est classée comme personne hors famille.
Un ménage est une personne ou un groupe de personnes habitant un logement. Un ménage peut être une personne qui habite seule, une ou plusieurs familles qui vivent ensemble, ou encore un groupe de personnes sans lien de parenté, mais qui habite le même logement.
Pourquoi Statistique Canada recueille-t-il des renseignements sur le genre et le sexe?
Pourquoi Statistique Canada recueille-t-il des renseignements sur le genre et le sexe?
Méthodologie/DEM
En 2019, Statistique Canada a commencé à recueillir par défaut des renseignements sur le genre, parfois en combinaison avec la question sur le sexe à la naissance, lorsqu'il est nécessaire de mesurer la population transgenre ou de dériver des indicateurs sur la santé ou des indicateurs démographiques. La question sur le genre comprend une réponse écrite « Ou veuillez préciser » pour permettre aux personnes de s'auto-identifier d'une manière inclusive et respectueuse.
Le Recensement de la population de 2021 comprenait pour la première fois une question sur le genre et la précision « à la naissance » à la question sur le sexe. En 2022, on a ajouté à l'Enquête sur la population active une question sur le genre en plus de la question sur le sexe à la naissance.
Ces modifications sont le reflet d'une plus grande reconnaissance sociale et législative des personnes transgenres et non binaires. En 2017, le gouvernement du Canada a modifié la Loi canadienne sur les droits de la personne et le Code criminel du Canada afin de protéger les personnes contre la discrimination et les crimes haineux fondés sur l'identité et l'expression de genre. Ces modifications sont conformes aux orientations stratégiques de 2018 du Secrétariat du Conseil du Trésor du Canada visant à moderniser les pratiques du gouvernement du Canada en matière d'information relative au sexe et au genre.
Bien qu'ils renvoient à deux concepts différents, le sexe à la naissance et le genre sont étroitement liés. Le sexe à la naissance est principalement considéré sous l'angle physique et biologique, alors que le genre est un concept multidimensionnel qui est influencé par plusieurs autres facteurs, dont les normes culturelles et comportementales ainsi que l'identité personnelle.
Le genre d'une personne peut différer de son sexe à la naissance et de la mention qui figure sur ses pièces d'identité ou documents juridiques actuels, tels que son certificat de naissance, son passeport ou son permis de conduire. Il peut changer au fil du temps. Certaines personnes peuvent ne pas s'identifier à un genre en particulier.
Numéros de téléphone et adresses électroniques utilisés par Statistique Canada
Comment Statistique Canada obtient-il les numéros de téléphone et les adresses électroniques?
Comment Statistique Canada obtient-il les numéros de téléphone et les adresses électroniques?
Afin de s'assurer que les échantillons d'enquête sont représentatifs de la population canadienne, Statistique Canada accède à l'information depuis une variété de dossiers administratifs qui incluent :
des listes de numéros de téléphone et de numéros de téléphone cellulaire;
des listes d'adresses et des renseignements sur les courriels provenant des dossiers du recensement;
des renseignements qui proviennent d'autres ministères, de bureaux municipaux, d'associations professionnelles, d'entreprises ou d'organisations avec lesquels nous avons des ententes et un pouvoir juridique en ce qui concerne l'accès à des dossiers administratifs.
Les listes utilisées contiennent uniquement des numéros de ligne terrestre, des numéros de téléphone cellulaire, des adresses ou des renseignements sur le courriel.
À partir de ces listes, Statistique Canada sélectionne au hasard des échantillons d'enquête représentatifs de la population canadienne.
Pourquoi Statistique Canada pose-t-il des questions sur les numéros de téléphone et les adresses électroniques utilisés à la maison?
Pourquoi Statistique Canada pose-t-il des questions sur les numéros de téléphone et les adresses électroniques utilisés à la maison?
Nous posons ces questions afin de bien associer l'ensemble des numéros de téléphone et des adresses électroniques aux bons ménages et ainsi éviter de sélectionner un ménage plus d'une fois pour la même enquête. Comme chaque ménage sélectionné représente un certain nombre de ménages ayant des caractéristiques semblables, en nous assurant d'avoir associé les bons numéros de téléphone et adresses électroniques aux bons ménages, nous pouvons attribuer le poids de chaque ménage, c'est-à-dire combien d'autres ménages il représente, de façon plus précise. Cette étape est essentielle pour obtenir des statistiques de qualité pour l'ensemble de la population.
Pourquoi Statistique Canada utilise-t-il les numéros de téléphone cellulaire et les adresses électroniques?
Pourquoi Statistique Canada utilise-t-il les numéros de téléphone cellulaire et les adresses électroniques?
L'utilisation des téléphones cellulaires augmente et celle des lignes téléphoniques conventionnelles diminue. On considère que les adresses électroniques sont une autre façon moderne de communiquer avec les répondants en cette ère numérique.
En vertu de la Loi sur la statistique, Statistique Canada acquiert et utilise des numéros de téléphone cellulaire et des adresses électroniques, afin de réduire les coûts de la collecte et d'assurer une bonne représentativité de tous les ménages canadiens, incluant ceux qui utilisent uniquement le téléphone cellulaire ou d'autres services de communication.
Les numéros de téléphone cellulaire et les adresses électroniques ne sont-ils pas considérés comme des renseignements personnels?
Les numéros de téléphone cellulaire et les adresses électroniques ne sont-ils pas considérés comme des renseignements personnels?
Statistique Canada comprend parfaitement que certains Canadiens peuvent s'inquiéter de recevoir des appels sur leur téléphone ou des courriels provenant de personnes qu'ils ne connaissent pas personnellement.
Statistique Canada traite tous les renseignements relatifs aux numéros de téléphone et aux adresses électroniques obtenus en vertu de la Loi sur la statistique de manière confidentielle.
Les renseignements recueillis en vertu de cette loi sont utilisés uniquement pour appuyer les programmes autorisés de Statistique Canada. Les renseignements ne sont pas utilisés à d'autres fins et ne sont pas transmis à des tiers, même au sein du gouvernement du Canada.
Que se passe-t-il si j'ai inscrit mon numéro de téléphone sur la Liste nationale de numéros de télécommunication exclus?
Que se passe-t-il si j'ai inscrit mon numéro de téléphone sur la liste nationale de numéros de téléphone exclus?
Cette liste a été créée pour limiter le nombre d'appels de télémarketing. Cela ne s'applique pas à Statistique Canada.
Statistique Canada n'est pas une agence de télémarketing. Loi sur la statistique donne à l'organisme le mandat de mener des enquêtes dans le but de fournir aux Canadiens de l'information exacte sur notre société, notre économie et notre population.
Ainsi, les personnes qui inscrivent leur numéro de téléphone sur la Liste nationale de numéros de télécommunication exclus continueront de recevoir des appels ou des textos de Statistique Canada dans le cadre de ses enquêtes.
Comment mon numéro de téléphone ou mon adresse électronique sont-ils utilisés?
Comment mon numéro de téléphone ou mon adresse électronique sont-ils utilisés?
Les listes utilisées ne renferment que des numéros de ligne terrestre, des numéros de téléphone cellulaire, des adresses ou des renseignements sur le courriel.
Les renseignements sont utilisés afin de mener des enquêtes.
Les renseignements relatifs aux numéros de téléphone, aux adresses ou aux courriels obtenus par Statistique Canada ne sont jamais transmis à un autre organisme ou à une personne, même au sein du gouvernement du Canada.
Pendant combien de temps mon numéro de téléphone ou mon adresse électronique sont-ils conservés?
Pendant combien de temps mon numéro de téléphone ou mon adresse électronique sont-ils conservés?
Statistique Canada obtient continuellement des renseignements sur les numéros de téléphone et les adresses électroniques, et met à jour ses bases de données afin d'accroître l'efficacité de ses programmes d'enquêtes.
Il n'est pas utile de conserver un numéro de téléphone ou une adresse électronique qui n'existe plus ou qui n'est plus lié à une adresse résidentielle précise.
Quelle est la probabilité que Statistique Canada communique avec moi par téléphone, par texto ou par courriel?
Quelle est la probabilité que Statistique Canada communique avec moi par téléphone, par texto ou par courriel?
Chaque année, seul un petit pourcentage de logements est sélectionné pour participer aux enquêtes-ménages menées par Statistique Canada.
La plupart du temps, Statistique Canada contacte les personnes (ou les ménages) par la poste, par courriel, par téléphone ou en personne.
Quelles sont les heures d'appel de Statistique Canada?
Quelles sont les heures d'appel de Statistique Canada?
Les bureaux régionaux gèrent les jours et les heures d'appel selon le type d'enquête. Cela diffère pour chaque bureau régional. En général, les heures d'appel sont de 8 h à 21 heures, du lundi au vendredi; ces heures sont réduites le samedi et le dimanche.
Statistique Canada a été fondé pour veiller à ce que les Canadiens aient accès à une source fiable de statistiques sur le Canada afin de répondre à leurs besoins les plus prioritaires. L'accès à une information statistique fiable est un fondement essentiel de toute société démocratique, à la fois pour appuyer la prise de décisions en fonction de données probantes dans les secteurs public et privé ainsi que pour éclairer le débat sur les questions de politique publique.
Pour de plus amples renseignements concernant les consultations actuelles ou à venir sur les projets de règlement fédéraux, veuillez consulter la Gazette du Canada ou le site Web Consultations auprès des Canadiens.
Q1. Qu’est-ce que la Biobanque de Statistique Canada?
La Biobanque de Statistique Canada a pour but d’accélérer les futurs projets de recherche et de créer des possibilités de suivi de la santé sur un échantillon de Canadiens représentatif à l’échelle nationale. La biobanque reçoit des échantillons d’enquêtes telles que l’Enquête canadienne sur les mesures de la santé ou l’Enquête canadienne sur la santé et les anticorps contre la COVID-19, qui permettent de recueillir des échantillons de gouttes de sang séché, de sang, d’urine et de salive de plus de 22 000 Canadiens consentants. Ces échantillons sont entreposés en lieu sûr aux fins d’études futures sur la santé. Pour obtenir l’autorisation d’utiliser ces échantillons dans le cadre de projets de recherche, il est nécessaire de suivre un processus d’examen scientifique, éthique et relatif à la sécurité approfondi.
Voici les avantages qu’offrent les échantillons de la biobanque :
Ils offrent aux chercheurs un meilleur accès aux échantillons de Canadiens consentants;
Ils offrent un processus accéléré de recherche puisque les échantillons sont déjà accessibles aux fins d’analyse;
Ils aident les Canadiens à tirer parti des progrès réalisés dans les domaines de la science et de la médecine.
Q2. Où puis-je obtenir de plus amples renseignements sur la Biobanque de Statistique Canada?
Vous trouverez de plus amples renseignements, tels que les descriptions des études autorisées de la Biobanque de Statistique Canada, sur la page Web de la biobanque : Biobanque du Statistique Canada
Q3. Où les échantillons sont-ils entreposés?
Tous les échantillons de sang, de gouttes de sang séché, d’urine et de salive sont entreposés sans aucun renseignement personnel au Laboratoire national de microbiologie de l’Agence de la santé publique du Canada à Winnipeg, au Manitoba. Ces installations hautement sécurisées respectent les normes internationales de sécurité s’appliquant aux laboratoires. Les échantillons y sont entreposés conformément aux exigences strictes de Statistique Canada en matière de confidentialité.
Q4. Pendant combien de temps conserverez-vous mes échantillons?
Les échantillons sont entreposés dans la Biobanque de Statistique Canada jusqu’à ce qu’ils ne soient plus scientifiquement viables. Ils sont retirés de la biobanque lors de leur utilisation pour un projet de recherche approuvé ou sur demande d’un répondant à l’enquête pour qu’ils soient retirés et détruits.
Q5. Qu’arrive-t-il à mon échantillon lorsqu’il n’a plus de valeur scientifique?
Tous les échantillons qui n’ont plus aucune valeur scientifique sont détruits au moyen de protocoles normalisés de destruction de déchets biologiques. Des directives canadiennes sont en place pour gérer certains types de déchet, par exemple, les directives pour la gestion des déchets biomédicaux au Canada du Conseil canadien des ministres de l’environnement, qui sont suivies par la plupart des provinces et des municipalités.
Q6. Mes échantillons se dégraderont-ils avec le temps? Oui, les échantillons se dégradent avec le temps. Certaines mesures d’échantillon se dégradent plus vite que d’autres. Les échantillons seront conservés uniquement s’ils ont un mérite scientifique. Les chercheurs qui présentent une demande pour utiliser ces échantillons tiendront compte de l’âge de l’échantillon et des mesures pour les analyser dans leurs laboratoires avant de choisir les bons échantillons pour leur analyse.Q7. Dans quelles circonstances les chercheurs auront-ils accès à mes échantillons?
Les échantillons sont à la disposition des chercheurs canadiens qui satisfont aux exigences d’admissibilité, telles qu’elles sont décrites dans la politique d’accès à la Biobanque de Statistique Canada, qui se trouve sur la page Web de la Biobanque de Statistique Canada. Aux fins de respect de la vie privée et de la confidentialité, les chercheurs accèdent aux données produites par l’intermédiaire des centres de données de recherche de Statistique Canada répartis au Canada.
Statistique Canada donnera aux chercheurs un accès restreint aux échantillons (exempts de tout renseignement personnel) pour réaliser des tests et des études uniquement dans les circonstances suivantes :
Les chercheurs doivent utiliser les échantillons pour effectuer des analyses scientifiques d’intérêt national.
Les chercheurs doivent respecter des directives strictes en matière de confidentialité.
Le projet de recherche doit recevoir une aide financière par l’entremise d’un processus d’examen scientifique établi tel que celui de trois organismes (en anglais seulement) (Conseil de recherches en sciences naturelles et en génie du Canada, Instituts de recherche en santé du Canada ou Conseil de recherches en sciences humaines du Canada) ou d’organismes fédéraux.
Le projet doit être approuvé par un comité d’éthique de la recherche.
Le sommaire du projet doit être affiché sur le site Web de Statistique Canada Projets Biobanque.
Q8. Les participants peuvent-ils retirer leur consentement concernant l’entreposage de leurs échantillons biologiques dans la Biobanque de Statistique Canada?
Le consentement peut être retiré à n’importe quel moment. Les participants peuvent demander que leurs échantillons soient retirés de l’entreposage et détruits en composant le 1-888-253-1087, ou en envoyant un courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca.
Q9. Si j’ai participé lorsque j’étais enfant, mes échantillons seront-ils toujours entreposés lorsque j’atteindrai l’âge adulte?
Oui, car le consentement a été donné lorsque les échantillons ont été recueillis. Cependant, les participants peuvent demander — en tout temps — que leurs échantillons biologiques soient retirés et détruits de l’entreposage en faisant parvenir une demande écrite à Statistique Canada ou en envoyant un courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca. Lorsque l’enfant aura 16 ans, Statistique Canada enverra un nouvel avis de consentement aux coordonnées fournies.
Q10. Quels types d’analyses sont effectuées sur les échantillons entreposés dans la Biobanque de Statistique Canada?
Les échantillons entreposés dans la Biobanque de Statistique Canada sont utilisés dans les études sur la santé. Les études sur la santé comprennent ce qui suit :
recherches se penchant sur les expositions antérieures à de nouveaux contaminants environnementaux;
nouvelles façons de surveiller la nutrition humaine;
prévalence antérieure de maladies infectieuses et découverte et validation de nouveaux biomarqueurs pour diagnostiquer les maladies;
recherche génétique pour évaluer l’état de santé et la susceptibilité des Canadiens aux maladies, aux infections ou aux expositions à des contaminants environnementaux.
Vous trouverez des renseignements sur les projets antérieurs et actuels de la biobanque sur le page Web de la Biobanque de Statistique Canada Projets Biobanque.
Q11. Mes échantillons seront-ils utilisés pour effectuer des tests génétiques?
Oui, il est possible que votre échantillon soit utilisé pour effectuer des tests génétiques. Les tests génétiques pourraient comprendre des études d’association de génomes, ou génotypage.
Deux projets de la biobanque ont utilisé de l’information génétique des échantillons de la biobanque pour coupler des données génétiques à des résultats sur l’état de santé. Le premier projet, réalisé par l’Agence de la santé publique du Canada, s’est penché sur la mesure dans laquelle les différences dans le code génétique entre les Canadiens pouvaient influencer la manière dont ces Canadiens absorbaient les nutriments. Le second projet, en cours à l’Université McGill, étudie comment les différences dans le code génétique influencent les résultats en matière de santé après une exposition à des contaminants environnementaux et des métaux.
Statistique Canada ne divulguera jamais votre génome au public. Statistique Canada, comme tout autre ministère fédéral agissant conformément à la Loi sur la protection des renseignements personnels du Canada, ne permettrait jamais que votre ADN soit utilisé de cette façon.
Il est possible de retirer un consentement pour certains tests génétiques, tout en conservant vos échantillons dans la Biobanque de Statistique Canada pour d’autres projets. Un participant peut retirer son consentement à tout moment en utilisant les coordonnées suivantes :Participants de la biobanque
Q12. Y a-t-il des fins auxquelles mon ADN ne sera PAS utilisé?
Oui. L’utilisation des échantillons d’ADN est strictement limitée aux projets et aux demandes qui obtiennent l’approbation du Comité d’éthique de la recherche, ainsi que l’examen de faisabilité de Statistique Canada et l’approbation du Comité consultatif de la biobanque. Votre ADN ne sera pas utilisé ou partagé aux fins suivantes :
clonage
action en justice ou toute autre poursuite;
à des fins d’appartenance ancestrale ou de généalogie;
compagnies d’assurance ou employeurs.
Q13. Les participants reçoivent-ils les résultats des études menées? Statistique Canada n’a aucune responsabilité de produire une déclaration obligatoire des résultats, comme de déclarer des maladies génétiques. Cependant, les participants peuvent obtenir une copie de leurs résultats sur demande. Les demandes peuvent être faites en composant le 1-888-253-1087 ou en envoyant un courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca.Q14. Comment protégez-vous les renseignements personnels et la confidentialité des participants?
Tous les renseignements dans la Biobanque de Statistique Canada sont protégés par la Loi sur la statistique. Les échantillons de gouttes de sang séché, de sang, d’urine, de salive et d’ADN sont traités comme toutes les autres données recueillies par Statistique Canada. Lorsque les échantillons sont recueillis, les tubes d’entreposage passent à travers un processus complet et rigide d’étiquetage. Seuls les employés autorisés de Statistique Canada peuvent avoir accès à ces échantillons et aux renseignements des participants. En vertu de la Loi sur la statistique, les échantillons et les données de la Biobanque de Statistique Canada demeureront toujours protégés et confidentiels. Par exemple, jamais Statistique Canada :
ne procédera à l’entreposage ou à l’analyse d’échantillons de participants si ceux-ci n’y ont pas consenti dans le formulaire de consentement;
ne transmettra de renseignements sur les échantillons des répondants à un organisme d’exécution de la loi;
ne transmettra de renseignements ou de résultats de tests des répondants à des compagnies d’assurance ou des employeurs;
ne permettra que des renseignements ou des données relatives à des participants soient utilisés dans le cadre d’une action en justice ou de toute autre poursuite judiciaire.
Jenneke Le Moullec, Cheffe, Programme d'élaboration de données sociales longitudinales Charles Uwitwongeye, Gestionnaire d'enquête, Centre de l'intégration et du développement des données sociales James Falconer, Chef, Avenir du recensement Sonia Bataebo, Analyste-conseil, Centre de l'intégration et du développement des données sociales
Résumé
Le présent rapport contient un résumé des conclusions du projet de recherche par la participation citoyenne délibérative menée par Statistique Canada entre octobre et décembre 2022. Il s'agissait d'une étude qualitative explorant l'acceptabilité sociale entourant l'utilisation de données administratives couplées, au niveau de la personneNote de bas de page 1, dans le cadre de programmes statistiques. Au total, 45 participants ont été recrutés et chacun a participé à 10 séances données en anglais ou en français. Au cours de ces séances, les participants ont appris à propos du sujet, ont débattu puis ont délibéré avant de voter sur une série d'énoncés définitifs. Ce rapport résume les constatations en ce qui concerne les thèmes globaux, les citations représentatives formulées par les participants durant la séance, et les résultats de courts sondages menés auprès des participants.
Même si l'objectif global était de comprendre les circonstances dans lesquelles le public canadien trouverait acceptable d'utiliser des données administratives sociales couplées (au niveau de la personne), et de comprendre les principes directeurs régissant l'utilisation de ces données à des fins statistiques, nous avons compris que cette question de recherche devait être posée et explorée dans le contexte plus large du mandat de Statistique Canada, de la protection des renseignements personnels et de la confidentialité, de l'incidence des données et de la sensibilisation du public.
L'étude vise à nous éclairer sur les raisons pour lesquelles les personnes ont des opinions particulières sur l'utilisation des données à des fins statistiques. Guidés par le processus de conception par la recherche délibérative, les points de vue éclairés des 45 participants ont donné lieu à une série de 14 énoncés globaux finaux. Sans être exécutoires, ces énoncés sont plutôt un artéfact du processus de recherche qui ne doit pas être pris hors contexte.
Méthodologie
Cette étude qualitative s'appuyait sur un cadre de recherche à participation citoyenne délibérative. La recherche délibérative est une technique qualitative de plus en plus utilisée dans les sciences sociales et se distingue d'autres formes de recherche qualitative de deux façons : 1) les participants reçoivent des renseignements pertinents sur lesquels ils fondent leurs opinions, ce qui leur permet de fournir des commentaires significatifs; 2) une série d'énoncés définitifs sont formulés par les participants et font l'objet d'un vote selon la prémisse que, comme dans la vie sociale et politique réelle, malgré leurs différences sur le plan des valeurs, des opinions et des champs d'intérêt, les membres de la société doivent s'efforcer d'adopter des règles et des pratiques communes que tous peuvent accepter.
Les étapes du projet de recherche étaient les suivantes :
Étape 1 : Recrutement des participants Étape 2 : Présentations et partage de l'information Étape 3 : Séance de remue-méninges Étape 4 : Délibérations sur des sujets cernés Étape 5 : Examen des énoncés Étape 6 : Vote final sur les énoncés Étape 7 : Clôture et évaluation
Lors du recrutement des participants, l'accent a été mis sur la diversité plutôt que sur une stricte représentativité. Étant donné que les résultats de la recherche délibérative ne sont pas destinés à être généralisés à l'ensemble de la population, le recrutement de participants a plutôt misé sur la diversité des opinions et des points de vue selon l'âge, le genre, la région, l'identité racisée et l'identité autochtone. Deux séances de délibération simultanées ont été menées en anglais et en français dans le cadre de 10 séances hebdomadaires, tenues au cours des mois d'octobre à décembre 2022. Les contraintes des séances délibératives ont rendu impossible la tenue de séances bilingues avec interprétation simultanée, de sorte que le format retenu était celui de séances séparées et simultanées dans chaque langue, le modérateur faisant ensuite la synthèse des énoncés délibératifs formulés par chaque groupe.
Formulation des énoncés délibératifs
Une technique couramment utilisée en recherche délibérative consiste à explorer le sujet, à écouter les principes sous-jacents qui ressortent des discussions et à demander aux participants de formuler des énoncés sous la direction du modérateur. Les énoncés directeurs ne se limitent pas à essayer de combler les lacunes dans ce que fait actuellement Statistique Canada. C'est-à-dire que, même si certains énoncés évoquent un idéal, d'autres pointent vers des activités déjà en cours à Statistique Canada.
Écouter : Les chercheurs ont écouté les échanges au cours de la séance de remue-méninges et des discussions délibératives.
Résumer : Les principes sous-jacents dégagés lors de la séance de remue-méninges et des discussions ont été résumés en un total de neuf énoncés bilingues.
Proposer des énoncés : Les neuf énoncés ont été communiqués aux participants avant la discussion.
Discuter : Les neuf énoncés ont été évalués, un à la fois, par les participants lors de séances de groupe. Les participants ont suggéré d'apporter des modifications au libellé des énoncés (en anglais et en français) et aux motifs des questions, ont soulevé des omissions et proposé d'autres énoncés.
Mettre la dernière main : Les commentaires sur les neuf énoncés ont été intégrés aux versions bilingues définitives. Le nombre d'énoncés est passé de 9 à 14.
Voter : Les participants ont voté sur la mesure dans laquelle ils étaient d'accord ou en désaccord avec les 14 énoncés. Les participants ont eu l'occasion de discuter et de faire la critique des énoncés définitifs, mais aucun autre changement n'a été apporté.
Énoncés définitifs et vote
Le tableau 1 montre un degré élevé de consensus, autour des énoncés délibératifs définitifs, au sein des groupes.
Tableau 1 : Mesure dans laquelle les participants étaient d'accord avec les énoncés définitifs
Énoncés
Anglais (N = 24)
Français (N = 21)
FA
A
N
D
FD
FA
A
N
D
FD
En tant qu'organisme national de statistique, Statistique Canada joue un rôle essentiel en fournissant des renseignements de qualité pour éclairer la prise de décisions au Canada.
71 %
25 %
4 %
0 %
0 %
62 %
33 %
5 %
0 %
0 %
Statistique Canada est une importante source de renseignements crédibles et de grande qualité.
79 %
21 %
0 %
0 %
0 %
71 %
29 %
0 %
0 %
0 %
Pour s'acquitter de son rôle, Statistique Canada doit conserver un grand volume de données administratives et d'enquête couplables et de nature délicate.
33 %
58 %
4 %
4 %
0 %
57 %
38 %
5 %
0 %
0 %
Les méthodes suivantes sont toutes appropriées pour aider Statistique Canada à s'acquitter de son rôle : 1) la collecte de renseignements au moyen d'enquêtes; 2) la collecte de données administratives auprès d'organismes du secteur public et privé; et 3) le couplage de données d'enquête et de données administratives.
38 %
54 %
4 %
4 %
0 %
38 %
57 %
5 %
0 %
0 %
Compte tenu de son rôle qui est de fournir des renseignements de qualité pour éclairer la prise de décisions, Statistique Canada doit respecter des normes très élevées en matière de qualité des données.
88 %
13 %
0 %
0 %
0 %
90 %
10 %
0 %
0 %
0 %
Pour améliorer le bien-être au Canada, les données de Statistique Canada devraient être utilisées efficacement par les décideurs.
75 %
25 %
0 %
0 %
0 %
67 %
24 %
10 %
0 %
0 %
Les données de Statistique Canada devraient avoir une incidence sur l'amélioration du bien-être au Canada, mais, malheureusement, cette incidence n'est pas toujours visible.
50 %
38 %
8 %
4 %
0 %
48 %
33 %
19 %
0 %
0 %
Le public doit savoir où, pourquoi, quand et comment les données sont utilisées pour avoir une incidence mesurable et positive.
42 %
46 %
13 %
0 %
0 %
67 %
29 %
5 %
0 %
0 %
Afin d'assurer le soutien continu du public et d'améliorer sa réputation, Statistique Canada devrait faire connaître son impartialité de façon proactive.
54 %
29 %
17 %
0 %
0 %
67 %
33 %
5 %
0 %
0 %
Il est important que Statistique Canada produise des données qui mettent en évidence les expériences de groupes de population particuliers, notamment ceux qui sont désavantagés.
63 %
21 %
17 %
0 %
0 %
38 %
48 %
10 %
5 %
0 %
Statistique Canada devrait activement communiquer au public de l'information sur les diffusions de données et les publications analytiques au moyen de diverses stratégies et plateformes.
58 %
38 %
0 %
4 %
0 %
57 %
38 %
5 %
0 %
0 %
Compte tenu de la quantité de données que conserve Statistique Canada, l'organisme doit respecter des normes très élevées en matière de protection de la vie privée.
88 %
13 %
0 %
0 %
0 %
100 %
0 %
0 %
0 %
0 %
Il est important que les données de Statistique Canada soient protégées contre toute utilisation qui n'est pas dans l'intérêt du public. Cela comprend les menaces d'utilisations abusives 1) au sein de Statistique Canada; 2) dans le reste du gouvernement; et 3) à l'extérieur du gouvernement, maintenant et à l'avenir.
71 %
29 %
0 %
0 %
0 %
81 %
19 %
0 %
0 %
0 %
Statistique Canada doit avoir en place des mesures et des imputabilités rigoureuses pour 1) la collecte et le couplage des données; 2) la protection des données; 3) la divulgation des données; 4) la conservation et la destruction des données; et 5) la gestion des atteintes à la vie privée. Les mesures pourraient devoir évoluer au fil du temps. Les mesures devraient également être communiquées activement et efficacement aux particuliers, aux agents du Parlement et au Parlement lui-même.
75 %
21 %
0 %
4 %
0 %
81 %
14 %
5 %
0 %
0 %
Légende : FA = Fortement d'accord; A = D'accord; N = Ni d'accord ni en désaccord; D = En désaccord; FT = Fortement en désaccord
Résultats
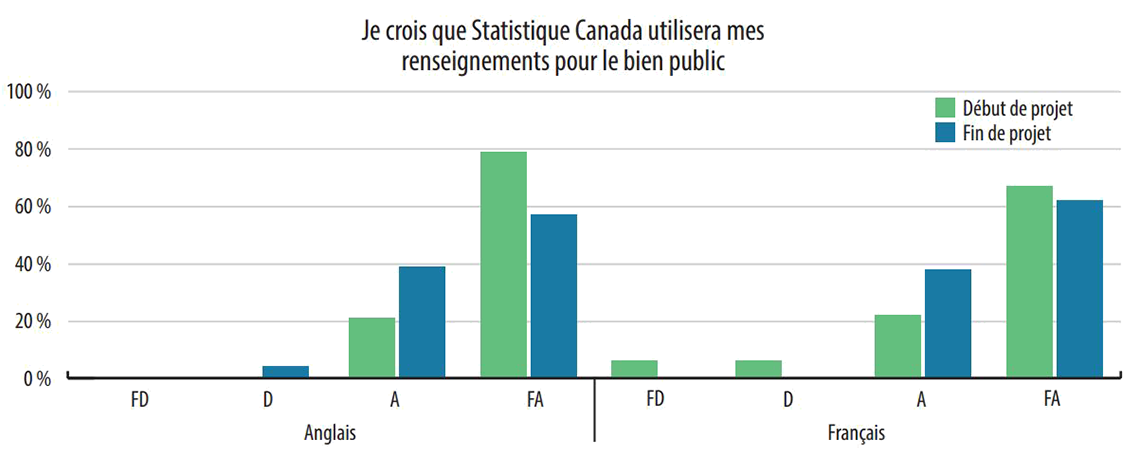
Quatre grands thèmes ont été dégagés : 1) l'utilisation de données administratives couplées; 2) la protection des renseignements personnels et la confidentialité; 3) l'incidence des données sociales; et 4) la sensibilisation du public.
Thème 1 : Utilisation de données Administratives couplées
L'utilisation de données administratives était acceptée, mais selon le volume et le type de données.
La grande majorité des participants étaient d'accord avec l'utilisation de données administratives couplées dans le cadre de programmes statistiques, et bon nombre d'entre eux s'attendaient à une telle utilisation. Quand on leur a expliqué quand, pourquoi et comment Statistique Canada utilise les données administratives couplées dans les programmes statistiques, de nombreux participants savaient déjà que les données étaient utilisées de la façon décrite, s'y attendaient, n'étaient pas surpris de l'apprendre ou n'ont pas exprimé de préoccupations. Quelques participants n'étaient pas enthousiastes à l'égard des données conservées par Statistique Canada, mais considéraient que ces fonds étaient nécessaires et que l'approche actuelle était meilleure que d'autres solutions. Les fonctions d'un organisme national de statistique au Canada étaient considérées comme impératives, même parmi les participants qui préféraient que leurs données ne soient pas incluses.
« … Je n'ai pas vraiment de problème en ce qui concerne l'utilisation des données administratives. Je pense qu'avec l'anonymat de tout cela et la façon dont les données sont recueillies et en sachant qu'elles sont conservées dans un endroit vraiment sûr sans risque de violation de données, ce n'est pas vraiment une grande préoccupation pour moi. »
Homme, 31 à 40 ans, Atlantique
« … Je comprends quelles sont les préoccupations : les données sont recueillies et elles sont reliées au gouvernement. Mais les membres du groupe semblent s'entendre pour dire qu'il est important de recueillir toutes ces données. Comment serait-il possible de recueillir ces données sans qu'elles soient liées au gouvernement? Quelle est l'autre option? »
Homme, 71 ans ou plus, Prairies
Les participants comprenaient généralement le rôle que joue Statistique Canada dans la communication de renseignements statistiques provenant d'enquêtes et de données administratives et l'appuyaient, y compris les participants ayant soulevé des préoccupations quant aux fonds de données administratives et d'enquête de Statistique Canada. Certains participants s'inquiétaient de la qualité des données administratives et de leur adéquation aux besoins des programmes statistiques. Les participants ont reconnu le degré variable de contrôle qu'exerce Statistique Canada sur différentes sources de données, le plus strict étant exercé sur les enquêtes, et le moins strict sur les données administratives recueillies par d'autres organismes. Certains participants se sont dits préoccupés par la qualité des données administratives, sur lesquelles ils s'attendaient à ce que Statistique Canada ait le moins de contrôle.
« … J'ignore pourquoi, mais je crains qu'il y ait plus d'erreurs dans les données provenant d'entreprises du secteur privé. Je crains qu'il y ait des erreurs dans la transmission des données à Statistique Canada. C'est l'impression que j'ai. »
Femme, 31 à 40 ans, Ontario
Quand ils ont envisagé les différents types de données administratives que conserve Statistique Canada, certains participants ont fait des distinctions quant à la provenance des données transmises à l'organisme. On a expliqué aux participants que Statistique Canada reçoit des données administratives de différents types d'organismes en vertu de la Loi sur la statistique, y compris d'organismes publics et privés. Les participants ont compris que le partage de ces données avait fait l'objet d'un examen approfondi et d'un processus de justification, et que cela a été rendu public sur le site Web de Statistique Canada. Bien que les participants aient accepté et appuyé cette idée, quelques-uns ont continué de faire des distinctions quant à la provenance des données.
La possibilité de biais dans les données administratives était un point important pour les participants, et ils ont fait remarquer que les biais inhérents pourraient découler des données recueillies par les systèmes administratifs. Ces biais comprenaient, par exemple, ceux qui découlent des perspectives occidentales traditionnelles, lesquels peuvent ne pas rendre fidèlement compte de la diversité au Canada.
La plupart des participants étaient d'accord avec la réception, l'utilisation et le stockage d'identificateurs personnels comme le prénom et le nom de famille. Les participants ont compris que des identificateurs personnels comme le prénom et le nom de famille étaient parfois requis pour le couplage d'enregistrements et qu'ils étaient donc parfois inclus dans les fichiers de données administratives d'autres organisations. On leur a expliqué que ces identificateurs sont utilisés et entreposés séparément des fichiers analytiques, et qu'ils ne sont divulgués d'aucune façon. Bien que quelques participants aient exprimé des réserves quant au volume et au type de données conservées par Statistique Canada, celles-ci ne portaient pas expressément sur la réception d'identificateurs personnels ni sur la nature des activités de couplage menées par Statistique Canada.
Les participants ont reconnu que le couplage d'enregistrements pouvait produire beaucoup de renseignements sur une personne. Cependant, ils n'ont pas exprimé la nécessité de définir une limite précise pour les activités de couplage. Ils considéraient le couplage d'enregistrements comme une technique statistique et, tout en reconnaissant le processus comme envahissant, ils n'ont pas expressément suggéré de limites à son utilisation, pourvu qu'il soit utilisé dans les programmes statistiques. Bien que la plupart des participants acceptaient que Statistique Canada utilise des données administratives couplées, quelques-uns ont indiqué être mal à l'aise. Si on leur en donnait l'option, certains préféreraient répondre directement aux enquêtes, tandis que d'autres préféreraient que leurs données administratives soient utilisées.
« … Dans l'une des présentations, il a été mentionné que les données administratives réduisaient le fardeau de réponse, et je crois que c'est une bonne chose. Je n'aime pas répondre à de longues enquêtes, alors si Statistique Canada peut recueillir les renseignements d'une autre façon, je n'ai aucune objection. »
Femme, 31 à 40 ans, Québec
« … Je préfère remplir le questionnaire en fait. »
Homme, 51 à 60 ans, Atlantique
Thème 2 : vie privée et confidentialité
Les participants s'attendent à ce que Statistique Canada respecte des normes rigoureuses en matière de responsabilisation, mais font confiance à l'organisme pour protéger la confidentialité de leurs renseignements personnels.
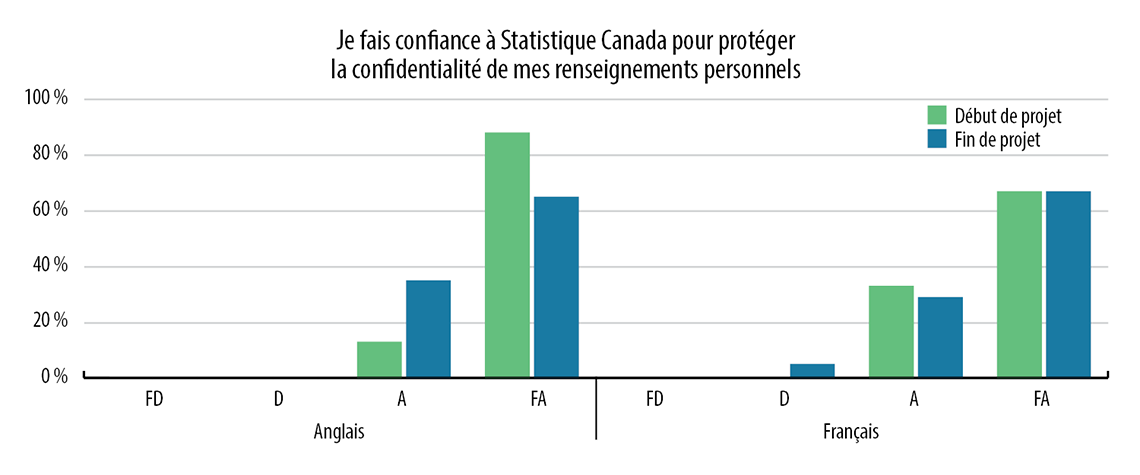
Au début de l'étude, dans le cadre du sondage de début de projet, on a demandé aux participants s'ils faisaient confiance à Statistique Canada pour protéger la confidentialité de leurs renseignements personnels, y compris contre le vol et les cyberattaques. Comme le montrent le tableau 2 et le tableau 3, au début de l'étude, la confiance des participants à cet égard était élevée.
Tout au long de l'étude, les participants ont appris à mieux connaître les types de données administratives conservées par Statistique Canada et le volume et la nature de ces données, y compris les données sur des sujets de nature délicate et les identificateurs personnels. Ils ont également été informés des risques associés aux cyberattaques et aux atteintes à la sécurité des données, ce qui a entraîné une légère baisse dans les réponses positives aux questions sur la confiance lors du sondage de fin de projet. Sachant cela, les participants faisaient encore confiance à Statistique Canada pour protéger leurs renseignements personnels. Voir le tableau 2 et le tableau 3 ci-dessous.
Tableau 2 : Réponses aux sondages de début et de fin de projet : « Je fais confiance à Statistique Canada pour protéger la confidentialité de mes renseignements personnels. »
« Je fais confiance à Statistique Canada pour protéger la confidentialité de mes renseignements personnels. »
Anglais
Français
FD
D
A
FA
FD
D
A
FA
Début de projet
0 %
0 %
13 %
88 %
0 %
0 %
33 %
67 %
Fin de projet
0 %
0 %
35 %
65 %
0 %
5 %
29 %
67 %
Légende : FD = Fortement en désaccord; D = Plutôt en désaccord; A = Plutôt d'accord; FA = Fortement d'accord
Tableau 3 : Réponses aux sondages de début et de fin de projet : « Je fais confiance à Statistique Canada pour protéger mes renseignements personnels contre le vol ou les cyberattaques. »
« Je fais confiance à Statistique Canada pour protéger mes renseignements personnels contre le vol ou les cyberattaques. »
Anglais
Français
FD
D
A
FA
FD
D
A
FA
Début de projet
4 %
0 %
25 %
71 %
0 %
0 %
50 %
50 %
Fin de projet
0 %
0 %
43 %
57 %
0 %
10 %
62 %
29 %
Légende : FD = Fortement en désaccord; D = Plutôt en désaccord; A = Plutôt d'accord; FA = Fortement d'accord
En ce qui concerne la gestion de la protection des renseignements personnels, les participants s'attendaient à ce que Statistique Canada soit tenu de respecter des normes égales ou supérieures à celles des autres organismes. Alors qu'ils étaient tous d'avis qu'il était de la plus haute importance pour Statistique Canada de protéger la vie privée, ils ne s'entendaient pas sur la question de savoir si l'organisme devrait être assujetti à la même norme, ou à une norme plus élevée que d'autres organisations.
« … Je m'attends à ce que Statistique Canada respecte la même norme que tout organisme public à qui on a accordé la garde de données personnelles. Je ne pense pas que Statistique Canada devrait être tenu de respecter une norme plus élevée en particulier en raison du volume, du type ou de l'ampleur des données que l'organisme conserve, mais il ne devrait certainement pas être tenu à une norme inférieure. »
Homme, 31 à 40 ans, Atlantique
Les participants voulaient savoir quelles mesures et cadres étaient en place pour protéger leurs données. On les a informés du large éventail de mesures utilisées par Statistique Canada pour protéger les données, y compris les obligations et pouvoirs législatifs et les responsabilités du personnel, et on leur a expliqué certains détails techniques, comme l'anonymisation des données. De manière générale, les participants souhaitaient comprendre ces mesures, n'ont pas exprimé de préoccupation particulière, et semblaient satisfaits.
Même s'ils étaient à l'aise avec les mesures de protection de la vie privée, certains participants étaient inquiets de l'utilisation potentiellement abusive de données personnelles, aujourd'hui et dans le futur. Ils ont exprimé différents niveaux de préoccupations au sujet de l'utilisation potentiellement abusive des données personnelles. Bien que la plupart des participants n'aient pas contesté le fait que l'utilisation abusive des données était théoriquement possible, ils étaient nombreux à ne pas s'attarder au risque d'utilisation abusive. Ceux qui ont exprimé des préoccupations ont donné différentes raisons. Certains ont mentionné le risque d'une utilisation partisane des données, tandis que d'autres étaient inquiets de personnes malveillantes ou du vol d'identité. Les participants ont reconnu la possibilité d'une violation de données, le tort que cela pourrait causer aux personnes, et l'importance d'une gestion adéquate des atteintes.
« … Je suis préoccupée par le lien avec le gouvernement, même si vous avez mentionné que Statistique Canada travaille indépendamment de lui. Oui, ça me dérange. N'importe quel gouvernement, que ce soit le gouvernement actuel, l'ancien ou le prochain. Comment vont-ils utiliser nos données? Comment vont-ils manipuler nos données et en tirer avantage? C'est la question qui me préoccupe. Ma plus grande préoccupation est le lien entre Statistique Canada et le gouvernement et le fait qu'ils envahissent notre vie privée. »
Femme, 41 à 50 ans, Ontario
« … Une violation de données est grave si l'on tient compte du fait que les données administratives comprennent tout, de notre numéro d'assurance sociale à celui de notre assurance-maladie, en passant par notre adresse, notre nom, les renseignements sur nos bébés, tout. Ils ont accès à tous nos renseignements, et nous leur en donnons encore plus lorsqu'ils le demandent. »
Femme, 61 à 70 ans, Prairies
Compte tenu de la nature envahissante du couplage des données, de la collecte obligatoire de certains renseignements d'enquête et de certains renseignements administratifs, et de l'impossibilité pour certaines personnes de refuser le couplage de leurs données ou de donner un consentement éclairé, Statistique Canada devrait s'efforcer de comprendre les points de vue de la population concernant son importante obligation de protéger la confidentialité des renseignements personnels des particuliers.
Thème 3 : Incidence des données sociales
Même s'ils s'attendent à ce que Statistique Canada utilise leurs données pour le bien commun, les participants aimeraient obtenir davantage de preuves que leurs données ont une incidence positive dans un contexte réel.
Au-delà de la façon dont les données sont recueillies et conservées, les participants voulaient en savoir davantage sur les raisons pour lesquelles les données sont utilisées et sur les répercussions sociales de cette utilisation. Le contrat social entourant l'utilisation des renseignements personnels par Statistique Canada repose sur l'utilisation responsable des données dans l'intérêt public. C'est-à-dire d'améliorer la vie des personnes qui vivent au Canada. Toutefois, en plus de faire confiance à Statistique Canada pour assurer la sécurité de ses données, les participants veulent avoir la certitude que la façon dont Statistique Canada utilise leurs données améliorera la vie des Canadiennes et Canadiens.
« … Je conviens que toute donnée recueillie devrait être utilisée aux fins auxquelles [Statistique Canada] souhaite s'en servir. Mais, plus que jamais auparavant, j'ai quand même des préoccupations quant à la façon dont elles sont entreposées et utilisées. »
Femme, 41 à 50 ans, Ontario
Au début de l'étude, dans le cadre du sondage de début de projet, on a demandé aux participants s'ils croyaient que Statistique Canada utilisait leurs données dans l'intérêt public. Comme on le voit dans le tableau 4, la plupart des participants étaient fortement d'accord que c'était le cas.
Pendant l'étude, les participants ont été invités à prendre considération les types de renseignements sociaux que Statistique Canada pourrait produire, y compris, par exemple, sur la qualité de l'eau dans les collectivités autochtones, la maltraitance des enfants, les conditions de logement, et le lien entre l'exposition environnementale et les résultats en matière de santé. Devant ces considérations, en raison des priorités multiples et concurrentes, les participants trouvaient de plus en plus difficile de définir « utilisation des données dans l'intérêt public ».
À la fin de l'étude, comme le montrent les réponses au sondage de fin de projet présentées dans le tableau 4, les participants étaient d'avis que Statistique Canada utilisait leurs renseignements dans l'intérêt public. Cependant, moins de participants étaient fortement d'accord. Ce changement s'explique par le fait que pendant l'étude, les participants ont envisagé de plus près le concept d'intérêt public.
Tableau 4 : Réponses aux sondages de début et de fin de projet : « Je crois que Statistique Canada utilisera mes renseignements pour le bien public. »
« Je crois que Statistique Canada utilisera mes renseignements pour le bien public. »
Anglais
Français
FD
D
A
FA
FD
D
A
FA
Début de l'étude
0 %
0 %
21 %
79 %
6 %
6 %
22 %
67 %
Fin de l'étude
0 %
4 %
39 %
57 %
0 %
0 %
38 %
62 %
Légende : FD = Fortement en désaccord; D = Plutôt en désaccord; A = Plutôt d'accord; FA = Fortement d'accord
Les participants voulaient savoir comment les priorités en matière de recherche étaient établies à Statistique Canada, y compris le rôle du reste du gouvernement dans l'établissement de ces priorités et comment le financement était attribué. Lorsque les participants ont discuté de la façon dont leurs données étaient utilisées, ils tenaient beaucoup à comprendre le contexte global de la façon dont les priorités de recherche étaient établies.
Certains participants ont souligné l'importance de l'incidence des données sociales sur les groupes minoritaires et les personnes en quête d'équité. Les sujets liés aux données sur les Autochtones ont fait l'objet de discussions tout au long des séances. Ces discussions ont été éclairées par des présentations données par le Centre de la statistique et des partenariats autochtones de Statistique Canada et d'un spécialiste en données sur les Autochtones de l'extérieur de Statistique Canada. Certains participants ont soulevé l'invisibilité apparente des répercussions qu'ont eues les études sur les questions concernant les Autochtones. Certains participants ont également mentionné l'incidence considérable des données sociales sur les groupes minoritaires et les groupes en quête d'équité, comme les groupes de minorités linguistiques, de personnes ayant un handicap et de personnes de diverses identités de genre.
Sur le plan de la protection des renseignements personnels, les participants se sont généralement moins attardés aux types de données qui sont recueillies, couplées et analysées, à condition que des mesures de protection soient en place. Au lieu, ils voulaient savoir si les « bonnes » données sont étudiées et si ces études mènent à des changements. Invités à donner leurs impressions quant aux types de données conservées par Statistique Canada et aux activités de couplage qui ont été menées, les participants ont systématiquement ramené la discussion à la question de recherche à laquelle leurs données serviraient à répondre, et aussi aux possibles répercussions que le projet de recherche pourrait avoir.
« … J'ai eu le temps cette semaine de jeter un coup d'œil sur le site Web de Statistique Canada et j'ai surtout consulté des données sur les Autochtones. Les premières statistiques sur les Autochtones concernaient les tendances dans les homicides au Canada. Venaient ensuite des statistiques le revenu et l'emploi à temps plein des femmes autochtones. Ensuite, il y avait des statistiques sur les conditions de logement des Premières Nations et des Inuit, et les refuges pour les victimes autochtones de violence. À mon avis, ces statistiques sont assez négatives. Alors je me pose la question suivante : pourquoi recueillons-nous ces données si rien ne change, si rien ne se passe? »
Femme, 61 à 70 ans, Prairies
Les participants avaient des opinions différentes sur la mesure dans laquelle Statistique Canada devrait influencer la politique gouvernementale. Ils étaient divisés quant au rôle que Statistique Canada devrait jouer dans l'établissement des priorités de recherche et quant à l'influence que les résultats de la recherche devraient avoir sur les décisions du gouvernement en matière de politiques et de programmes. Par exemple, un participant a suggéré que Statistique Canada devrait jouer un rôle dans la détermination des enjeux sociaux importants, alors qu'un autre était d'avis que l'organisme devrait fonctionner de façon autonome par rapport au reste du gouvernement.
Selon les participants, Statistique Canada joue un rôle important dans la production de renseignements de qualité, tout particulièrement dans un environnement où il y a de la mésinformation et de la désinformation. Certains ont établi une distinction entre les renseignements statistiques fournis par Statistique Canada et ceux fournis par d'autres organismes privés et sans but lucratif. Statistique Canada était perçu comme ayant une meilleure réputation pour ce qui est de fournir des renseignements de grande qualité. Certains ont également mentionné que Statistique Canada joue un rôle important dans la lutte contre la désinformation.
« … Je suis vraiment très préoccupé par la mésinformation aujourd'hui et par la façon dont les gens obtiennent leurs renseignements. Statistique Canada a-t-il examiné comment il peut conserver une bonne réputation? »
Femme, 61 à 70 ans, Prairies
Thème 4 : Sensibilisation du public
Les participants veulent en savoir plus sur Statistique Canada : Quelles données conservons-nous? Comment recueillons-nous, entreposons-nous et analysons-nous ces données? Quelles constatations intéressantes avons-nous tirées de nos recherches?
Les participants ont souligné l'importance de sensibiliser le public en communiquant de façon active et transparente. La plupart d'entre eux étaient d'avis que Statistique Canada devrait être transparent et communiquer activement de l'information sur ses fonds de données et sur la façon dont il utilise les renseignements personnels.
Au début du processus de recherche, quelques participants ont soulevé les sujets du consentement actif et des énoncés obligatoires dans le contexte de l'utilisation des données administratives par Statistique Canada. Au cours des séances, les participants ont appris que Statistique Canada ne cherche généralement pas à obtenir le consentement pour utiliser les données administratives, et qu'il n'inclut pas de déclaration de divulgation obligatoire sur les données recueillies par un autre organisme et fournies à Statistique Canada.
« … Il est important que les renseignements demandés soient utilisés uniquement aux fins pour lesquelles ils sont demandés et qu'ils ne soient pas communiqués d'une autre façon, afin que je sache exactement quelles données je fournis, où elles vont et comment elles seront utilisées. »
Homme, 71 ans ou plus, Prairies
Après avoir appris cela, les participants n'ont pas suggéré de mettre en œuvre le consentement actif ou l'énoncé obligatoire. Ils ont plutôt insisté sur l'importance de la transparence et de la communication active de l'information sur les fonds de données et l'utilisation des renseignements personnels. En plus de rendre cette information disponible sur le site Web, de nombreux participants étaient d'avis que Statistique Canada devait tenter de communiquer activement cette information aux personnes vivant au Canada.
La plupart des participants étaient d'avis que Statistique Canada devrait être transparent et communiquer activement de l'information sur la façon dont leurs renseignements sont protégés, y compris de l'information sur les violations de données. Bien que dans l'ensemble, les participants aient convenu que l'information sur les violations de données devrait être communiquée activement, certains ont mentionné que cette communication ne devrait pas se limiter aux personnes directement touchées par une violation, mais être communiquée de façon plus générale, par exemple, par l'entremise des médias. De plus, avant d'être informés au sujet de la présente recherche, certains participants croyaient qu'ils découvriraient s'ils avaient été victimes d'une violation des données que par l'entremise des médias, et ignoraient que Statistique Canada communiquerait directement avec eux.
La plupart des participants étaient d'avis que Statistique Canada devrait être transparent et communiquer activement de l'information sur les produits analytiques et les projets de recherche. Ils ont pris connaissance des produits analytiques de Statistique Canada durant l'étude. Un grand nombre d'entre eux ont manifesté de l'intérêt pour ces produits et ont visité le site Web de Statistique Canada pour en apprendre davantage sur divers sujets. De plus, ils étaient nombreux à affirmer que les renseignements produits par Statistique Canada sont intéressants, pertinents et utiles pour la population canadienne, et qu'ils devraient être activement communiqués afin qu'ils puissent être bien utilisés. Certains participants ont suggéré des canaux de communication qui pourraient être efficaces pour Statistique Canada, y compris les médias traditionnels, les médias sociaux et d'autres plateformes comme les balados.
Limites
Des renseignements et des points de vue limités provenant de l'extérieur de Statistique Canada ont été communiqués aux participants. Les résultats du sondage d'évaluation donnent à penser que les participants croyaient que les renseignements fournis étaient impartiaux et complets, mais on considère toutefois que l'inclusion de différents renseignements peut avoir eu une incidence sur les résultats de l'étude.
Bien que la recherche ait porté sur des sujets liés aux groupes minoritaires et aux groupes en quête d'équité, il ne s'agissait pas de la principale question de recherche. Par conséquent, d'autres études devraient être menées pour tenir compte des circonstances uniques de différentes sous-populations, y compris les groupes autochtones fondés sur les distinctions.
Discussion
L'utilisation de données administratives couplées doit être envisagée dans le contexte plus large du mandat, des obligations et des pouvoirs législatifs de Statistique Canada. Les participants n'ont pas fait de distinction entre les principes directeurs sur l'utilisation des données administratives couplées et les activités globales de Statistique Canada.
Même si l'objectif de la recherche était d'écouter les délibérations sur l'utilisation des données administratives couplées dans les programmes statistiques, les discussions se sont à maintes reprises éloignées du sujet principal pour se concentrer sur le rôle plus large et les activités de l'organisme national de statistique.
Statistique Canada organise son cadre juridique, ses politiques et directives, sa gouvernance des données et ses processus opérationnels en fonction de la gestion de différentes classifications des données, comme les données d'enquête, les données administratives et les données identifiées et les données anonymisées. Toutefois, les participants n'ont pas nécessairement délimité différents types de données de cette façon et se sont plutôt concentrés sur le rôle de Statistique Canada, son mandat, la protection des renseignements personnels et la confidentialité, l'incidence des données et la sensibilisation du public.
En raison de cette perspective, les discussions sur les limites de l'acceptabilité sociale ne portaient pas spécifiquement sur les circonstances dans lesquelles le couplage de données administratives était acceptable. Cependant, les limites de l'acceptabilité sociale et les circonstances dans lesquelles le couplage est acceptable peuvent être déduites des autres constatations et thèmes clés, comme la confidentialité et la protection des renseignements personnels, l'utilisation des données pour le bien commun et la transparence.
Même après avoir été informés du volume, des types, de la nature et des objectifs des activités de couplage menées à Statistique Canada, qui comprenaient des renseignements sur l'Environnement de couplage de données sociales et l'utilisation des données administratives dans des programmes comme le Recensement de la population et les Cohortes santé et environnement du recensement du Canada, les participants n'ont pas circonscrit les discussions ou les énoncés délibératifs aux circonstances dans lesquelles le couplage des données était approprié.
Les participants ont été recrutés en fonction de différents profils démographiques et de différents antécédents et selon différents niveaux de confiance envers le gouvernement et les institutions publiques. Bien que l'objectif fondamental de la recherche ait été de comprendre les circonstances dans lesquelles les Canadiennes et Canadiens issus de la diversité jugent acceptable d'utiliser des données administratives couplées ainsi que les principes directeurs sur l'utilisation des données à des fins statistiques, il était attendu que les opinions des participants ne convergent pas toutes complètement et que certains points de vue minoritaires soient maintenus. La plupart des participants ont maintenu les énoncés délibératifs, générant des connaissances sur les principes directeurs. Cependant, il est essentiel de se rappeler que les énoncés et leur appui reposent sur des points de vue divergents qui mettent en évidence la diversité des points de vue au Canada.
Non seulement ce projet de recherche nous éclaire-t-il sur les circonstances dans lesquelles le public canadien trouverait socialement acceptable d'utiliser des données administratives couplées, au niveau de la personne, mais elle fait aussi ressortir que l'utilisation de données administratives doit être envisagée dans le contexte plus large du rôle et des activités d'un organisme national de statistique.
Conclusion
Statistique Canada jouit d'un niveau de bonne volonté extraordinairement élevé de la part du public, comme en témoigne le taux de réponse du Canada à son recensement national, le plus élevé au monde, la haute estime accordée à Statistique Canada au pays et à l'étranger, et la robustesse de ses données faisant qu'elles peuvent éclairer la recherche universitaire, les politiques publiques ainsi que le débat national sur les questions sociales, économiques et environnementales. Les Canadiennes et Canadiens ont à cœur la réputation de Statistique Canada, et ils sont prêts à donner de leur temps, à lui faire confiance, et à partager leurs renseignements personnels pour assurer la qualité des données qui nous donnent un portrait juste de la population du pays, dans toute sa diversité. Statistique Canada peut tirer parti de sa relation de confiance avec la population pour améliorer ses programmes statistiques, sans éroder la confiance du public, dans la mesure où nous pouvons maintenir et améliorer nos activités de renforcement de la confiance et démontrer que les données des Canadiennes et Canadiens sont utilisées dans l'intérêt public.
Nous avons appris que nos participants à la recherche ne ressentent pas nécessairement le besoin d'imposer des limites à l'utilisation de données administratives couplées pour les programmes statistiques. Tant que des données de grande qualité sont analysées dans un environnement protégé et que la nécessité et la proportionnalité des données peuvent être justifiées au public, les participants acceptent généralement que le couplage de microdonnées soit et doive être utilisé pour produire de nouvelles informations précieuses. Les résultats du projet montrent que Statistique Canada peut envisager d'être plus audacieux dans sa vision d'une infrastructure statistique intégrée, si les mesures correspondantes en matière de transparence et de responsabilisation sont clairement communiquées et démontrées au public.
Les questions et les observations des participants devraient susciter une introspection attentive sur la façon dont Statistique Canada devrait façonner son « identité » en tant qu'organisme par rapport au public et au gouvernement. Par exemple, Statistique Canada peut-il conserver la rigueur et la crédibilité scientifiques tout en répondant aux besoins en évolution de la société en matière de données? Notre obligation prend-elle fin avec la diffusion de renseignements fidèles et véridiques, ou Statistique Canada doit-il mener une bataille publique contre la désinformation? Ces questions prennent tout leur sens lorsque nous reconnaissons les écarts qui existent entre ce que les attentes du public envers Statistique Canada et ce que nous pouvons espérer accomplir. À mesure que Statistique Canada se définit en tant qu'organisme, nous devons poursuivre le dialogue avec la population canadienne.
Plusieurs recommandations ont été dégagées des séances du projet de RPCD qui, si elles sont adoptées, contribueront de façon significative à la relation de confiance de Statistique Canada avec le public canadien. Certaines de ces recommandations ont été explicitement suggérées par les participants, tandis que d'autres ont été proposées par l'équipe de projet en réponse aux besoins et aux désirs exprimés par les participants. Premièrement, les participants ont suggéré l'adoption de mesures permanentes au sujet de la confiance du public à l'égard de Statistique Canada et d'autres questions relatives aux données. Statistique Canada devrait tenir compte de la recherche longitudinale sur l'opinion publique pour se tenir au courant des perspectives de la population générale. Presque tous les participants au projet de RPCD seraient prêts à se joindre à un « comité consultatif de citoyens » que Statistique Canada pourrait utiliser pour des séances de remue-méninges et pour mettre à l'essai des questions sur l'opinion publique. Deuxièmement, les participants apprécient la communication ouverte et transparente sur la façon dont Statistique Canada utilise les données. Statistique Canada devrait envisager d'utiliser de façon proactive les canaux de communication externes dans les médias traditionnels et numériques, et optimiser l'utilisation du Centre de confiance pour la transparence, la responsabilisation et la communication ouverte. Troisièmement, les participants veulent voir l'incidence de leurs données sur la qualité de vie. Statistique Canada devrait concevoir un nouveau type d'outil d'évaluation qui, à notre connaissance, n'a pas encore été envisagé, soit une évaluation de l'incidence des données afin d'évaluer si et comment nos produits de données sont utilisés pour apporter des changements dans un contexte réel. Comme Statistique Canada continue d'accroître l'utilisation des données administratives dans les programmes statistiques, il pourrait y avoir de moins en moins d'interactions directes avec le public sur lesquelles bâtir la confiance. La mise en œuvre de ces recommandations ouvrirait de nouvelles voies d'interaction directe avec le public pour bâtir la confiance dont dépend la qualité de nos données.
L'une des grandes forces de cette méthode de recherche et de ce projet en particulier a été notre accès privilégié au point de vue de Canadiennes et Canadiens ordinaires. C'est une leçon d'humilité de constater que la plupart des gens au Canada ne pensent pas un seul instant à Statistique Canada dans leur vie quotidienne. Mais lorsqu'on les réunit dans un forum de discussion, qu'on les informe de ce que nous faisons et qu'on leur demande de se prononcer sur un sujet particulier, cela génère une mine de données qualitatives que nous pouvons utiliser pour rectifier l'orientation de l'organisme, de ses programmes statistiques et de ses communications publiques. Cette méthode de recherche devrait être adoptée comme étude récurrente pour examiner plus à fond les enjeux plus importants avec lesquels Statistique Canada devra composer dans les années à venir.
La population canadienne demande d'avoir des données plus détaillées pour éliminer les disparités entre les genres, lutter contre le racisme et surmonter d'autres obstacles systémiques.
Afin de fournir ces données détaillées, Statistique Canada continue d'explorer de nouvelles façons de tirer le meilleur des données recueillies, par exemple, en combinant les données du recensement et les données administratives détenues par d'autres organisations. On appelle ce processus le couplage de données. Le couplage de données permet d'accéder à des renseignements plus exacts et de mener des analyses approfondies. Il permet aussi de réduire le nombre d'enquêtes auxquelles la population canadienne est invitée à participer.
Les objectifs de la recherche délibérative
Entre octobre à décembre 2022, Statistique Canada a entrepris une recherche qualitative pour mieux comprendre le point de vue du public canadien sur l'utilisation des couplages de données. En tout, 45 participants de différents profils démographiques et de différents antécédents et selon différents niveaux de confiance envers le gouvernement et les institutions publiques. Après avoir pris connaissance du sujet, ensemble ils ont élaboré un ensemble de 14 énoncés de consensus fondamentaux tenant compte des positions du groupe.
La recherche délibérative est une technique qualitative de plus en plus utilisée dans les sciences sociales et se distingue d'autres formes de recherche qualitative de deux façons : 1) les participants reçoivent des renseignements pertinents sur lesquels ils fondent leurs opinions, ce qui leur permet de fournir des commentaires significatifs; 2) une série d'énoncés définitifs sont formulés par les participants et font l'objet d'un vote selon la prémisse que, comme dans la vie sociale et politique réelle, malgré leurs différences sur le plan des valeurs, des opinions et des champs d'intérêt, les membres de la société doivent s'efforcer d'adopter des règles et des pratiques communes que tous peuvent accepter.
Principal résultat
Les participants acceptent généralement que le couplage de données soit et doive être utilisé à Statistique Canada pour produire de nouveaux renseignements précieux, tant que des données de grande qualité sont analysées dans un environnement protégé. Les participants à la recherche ne ressentent pas nécessairement le besoin d'imposer des limites à l'utilisation de données administratives couplées pour les programmes statistiques.
Non seulement ce projet de recherche nous éclaire-t-il sur les circonstances dans lesquelles le public canadien trouverait socialement acceptable d'utiliser des données administratives couplées, au niveau de la personne, mais elle fait aussi ressortir que l'utilisation de données administratives doit être envisagée dans le contexte plus large du rôle et des activités d'un organisme national de statistique.




 (variation d'une période à l'autre)
(variation d'une période à l'autre) (variation d'une période à l'autre)
(variation d'une période à l'autre)