Les réductions annoncées dans le budget de 2025 et issues de l'examen exhaustif des dépenses ont confirmé la nécessité pour Statistique Canada de rationaliser ses opérations tout en continuant à produire les données de confiance dont dépendent les Canadiennes et Canadiens. Les mesures prises à l'échelle du gouvernement visent à réduire les dépenses consacrées aux opérations, tout en protégeant les programmes prioritaires et en investissant dans les domaines qui contribuent au bien-être économique et social du Canada.
En réponse, Statistique Canada a entamé en janvier 2026 un processus de réaménagement des effectifs et apporté des ajustements ciblés à ses programmes afin d'assurer la viabilité à long terme du système national de statistique du Canada. Ses programmes les plus critiques, comme ceux du Recensement de la population, de l'Indice des prix à la consommation, du produit intérieur brut et des statistiques du commerce et de l'emploi se poursuivront sans interruption. Les indicateurs essentiels que produisent ces programmes demeureront prioritaires et seront toujours accessibles aux gouvernements, aux entreprises et aux communautés partout au pays.
La plupart des changements concernent la manière dont les données sont recueillies et produites, et non la disponibilité des données. Pour réduire le double emploi et concentrer les ressources là où elles ont le plus d'incidence, certaines enquêtes et certains programmes statistiques seront interrompus si les données peuvent être obtenues au moyen d'autres méthodes ou auprès d'autres sources. En accroissant son utilisation de données administratives, de la modélisation, de l'automatisation et de l'intelligence artificielles, et en ajustent la fréquence de diffusion ou le niveau de détail des données lorsque c'est approprié de le faire, Statistique Canada continuera à produire des données de confiance tout en maintenant la qualité, l'intégrité et la continuité des indicateurs nationaux clés du Canada.
Tout au long ce cette période de changement, Statistique Canada maintien son engagement à l'égard de l'intendance responsable des ressources publiques et de la réalisation de son mandat en vertu de la Loi sur la statistique. Que Statistique Canada recueille des données administratives, des données d'enquête ou des données provenant d'autres sources, une chose demeure certaine : l'organisme poursuit ses activités conformément aux instruments et cadres régissant son fonctionnement, y compris ceux encadrant l'utilisation de l'automatisation et de l'intelligence artificielle, et l'engagement qu'il a pris de protéger les renseignements personnels ainsi que la confidentialité des données demeure inébranlable. À titre d'organisme national de statistique du pays, Statistique Canada continuera à produire des données fiables, objectives et de grande qualité pour appuyer la prise de décision éclairée et contribuer à renforcer la confiance du public dans les statistiques officielles.
Réduction du double emploi et concentration des ressources
Statistique Canada a identifié plusieurs programmes qui seront ajustés pour aider à répondre aux exigences de réduction des dépenses requises par l'examen exhaustif des dépenses.
Ces décisions ont été prises à l'issue d'un examen rigoureux mené à l'échelle de l'organisme qui a permis de déterminer ce sur quoi les Canadiennes et Canadiens comptent le plus et les domaines où des changements pourraient être apportés avec un minimum d'incidence. Ces ajustements visent à assurer la stabilité et la viabilité de l'organisme, tout en continuant à fournir des données de grande qualité et des renseignements fiables à la population canadienne, même avec un financement réduit.
La portée, la fréquence et/ou le niveau de détail d'éléments de certains programmes statistiques seront réduits. Les changements décrits ci-dessous, notamment, auront lieu.
Activités ajustées :
Centre des statistiques sur le genre, la diversité et l'inclusion — Le nombre de publications analytiques axées sur des populations désagrégées sera réduit. Suivant cette réduction, le Centre se concentrera en premier lieu sur la production de rapports en vertu du Cadre des résultats relatif aux genres.
Produit intérieur brut par industrie — Le nombre d'industries incluses sera réduit, les programmes du PIB national mensuel et du PIB provincial/territorial annuel ayant rationalisé et harmonisé leurs classifications des industries. La nouvelle structure comprend maintenant 174 industries aux deux échelons, réduisant le nombre d'industries de 22 à l'échelon national et de 52 à l'échelon provincial/territorial. Certaines industries de la fabrication et de la construction de plus petite taille ont été combinées, alors que le niveau de détail a été accru pour d'autres industries lorsque jugé utile d'un point de vue analytique ou statistique.
Programme d'intégration des données sociales — L'utilisation d'enquêtes par panel en ligne auprès de répondants recrutés d'avance sera réduite.
Programme de démographie — Certains éléments du Programme d'analyse sur les familles ont été réduits, y compris les totalisations personnalisées relatives aux mariages et aux divorces. Cependant, le tableau de bord interactif sur la fécondité continuera d'être mis à jour annuellement, tout comme les indicateurs de la fécondité, lesquels sont utilisés dans le cadre d'autres programmes de Statistique Canada, y compris pour les projections démographiques.
Programme de l'agriculture — La fréquence des statistiques sur la volaille et les œufs ainsi que des statistiques sur les livraisons des principales céréales sera réduite pour passer de mensuelle à trimestrielle. De plus, la production pour le cycle de janvier de l'Enquête sur le bétail semestrielle s'appuiera désormais sur la modélisation, et les données de l'Enquête sur la superficie et le rendement des pommes de terre semestrielle seront recueillies dans le cadre de la Série de rapports sur les grandes cultures.
Programme de l'Enquête sociale générale — L'Enquête sociale générale est en cours de transformation afin de répondre plus efficacement aux besoins en statistiques sociales de la population canadienne. Les indicateurs de la qualité de vie, auparavant recueillis dans le cadre de l'Enquête sociale canadienne, seront recueillis annuellement dans le cadre de l'Enquête sociale générale. De plus, l'enquête s'éloignera de sa conception thématique distincte (p. ex. Enquête sur l'emploi du temps, Enquête sur les transitions familiales) pour passer à un outil unique et rationalisé de collecte, avec des questionnaires de longueur limitée.
Programme de la statistique de l'environnement — La portée du programme du Recensement de l'environnement sera réduite. L'accent sera maintenu sur les produits de données et les résultats relatifs aux principaux écosystèmes (p. ex. terres, forêts, zones océaniques et côtières, zones agricoles, zones urbaines, étendues d'eau douce, milieux humides), mais les activités de rayonnement et de gouvernance ainsi que la fréquence des mises à jour feront l'objet de réductions. De plus, les activités de recherche et développement seront échelonnées sur de plus longues périodes.
Programme de la statistique de la santé — La portée des travaux d'enquête liés à la santé sexuelle et reproductive sera réduite. L'Enquête canadienne sur la santé gynécologique procédera comme prévu, mais l'Enquête auprès des fournisseurs de services d'avortement n'aura pas lieu.
Programme de la statistique des transports — Le niveau de détail de certains programmes du transport terrestre sera réduit, y compris, par exemple, les statistiques de l'exploitation ferroviaire et les données sur la longueur du réseau ferroviaire et la consommation de carburant diesel. La diffusion des Statistiques relatives aux mouvements des aéronefs sera désormais trimestrielle au lieu de mensuelle.
Programme de la statistique du travail — Le niveau de détail et la fréquence de certains indicateurs du marché du travail seront réduits, tout comme le nombre de produits liés à l'assurance-emploi. Plus précisément, les activités de collecte et de diffusion des Indicateurs socioéconomiques et du marché du travail (ISMT) sont suspendues pour l'exercice 2026-2027. Le supplément des ISMT constituait une enquête trimestrielle à participation volontaire, menée auprès des répondants de l'Enquête sur la population active. Par suite de cette suspension, la production des indicateurs annuels du marché de l'emploi pour les personnes ayant une incapacité et n'ayant pas d'incapacité sera aussi mise en pause. Des données sur les personnes ayant une incapacité, y compris des renseignements relatifs à leurs résultats sur le marché du travail, continueront d'être produites dans le cadre de l'Enquête canadienne sur l'incapacité.
Programme de la statistique sociale et juridique — La portée de certains éléments d'enquête du programme sera réduite, y compris l'Enquête sur la diversité au sein des conseils d'administration d'organismes sans but lucratif.
Programme des comptes macroéconomiques — Certains éléments liés aux taux d'utilisation de la capacité industrielle et aux intermédiaires financiers non bancaires seront éliminés, et la fréquence et le niveau de détail d'autres éléments seront réduits.
Programme des dépenses des ménages — Le programme sera modernisé pour mieux cadrer avec les besoins en données prioritaires, et la fréquence de diffusion sera annuelle au lieu de trimestrielle.
Activités abolies et en voie d'achèvement :
Compte des flux physiques des matières plastiques, une composante de l'Initiative zéro déchet de plastique
Diffusion annuelle sur l'immatriculation de véhicules
Données régionales sur les grandes cultures
Enquête annuelle sur les centrales d'énergie électrique
Enquête biennale sur l'eau dans l'agriculture
Enquête biennale sur l'eau dans les industries
Enquête biennale sur les usines de traitement de l'eau potable
Enquête canadienne sur la situation des entreprises
Enquête mensuelle sur l'aviation civile
Enquête sociale canadienne
Enquête sur les ménages et l'environnement
Enquête trimestrielle sur l'aviation civile
Estimations modélisées des principales grandes cultures, juillet
Laine : utilisation et valeur à la ferme
Mouvements d'aéronefs hebdomadaires
PIB par région métropolitaine de recensement
Programme d'intégration des données sociales – Programme d'élaboration de données sociales longitudinales
Programme sur l'accès aux soins de santé et l'expérience de soins
La science qui sous-tend nos enquêtes : ce que nous faisons pour assurer la qualité et réduire le fardeau
Chaque enquête est importante, et chaque réponse contribue à brosser un tableau plus complet du Canada.
Si vous ou votre entreprise êtes sélectionnés pour participer à une enquête de Statistique Canada, c’est parce que vous représentez d’autres personnes ayant une expérience similaire. Votre participation permet de garantir que la voix de tout le monde est entendue, et pas seulement celle des personnes qui parlent le plus fort ou qui sont les plus visibles.
Statistique Canada utilise des méthodes scientifiques pour sélectionner les participantes et participants de façon équitable et impartiale. Chaque personne ou entreprise sélectionnée joue un rôle important pour garantir que les résultats représentent fidèlement l’ensemble de la population. Une fois l’échantillon sélectionné, nous n’ajoutons, n’échangeons ou ne supprimons aucune personne ou entreprise, ce qui assure l’impartialité et la représentativité des résultats.
Votre temps a de l’importance
Nous savons que votre temps est précieux. C’est pourquoi nous utilisons l’échantillonnage, une méthode scientifique qui permet d’obtenir des renseignements sur l’ensemble d’une population en sondant un groupe plus restreint et représentatif. Nous utilisons également, dans la mesure du possible, les renseignements existants provenant de programmes gouvernementaux ou d’autres sources publiques fiables, afin de réduire le nombre de personnes à sonder. Cette approche permet de :
réduire la longueur et la fréquence des enquêtes;
réduire le temps et les efforts requis pour les participantes et participants;
produire des résultats exacts et équilibrés, représentatifs de l’ensemble du Canada.
Dans de rares cas, comme celui du Recensement de la population, nous devons joindre tout le monde. Mais pour la plupart des enquêtes, nous ne sollicitons que le nombre de personnes ou d’entreprises nécessaire pour assurer la qualité des résultats.
La science qui sous-tend les chiffres
Derrière chaque enquête se cache une équipe de spécialistes qui utilisent des méthodes fondées sur des décennies de théorie et de recherche statistiques. Ces méthodes garantissent que :
les données sont recueillies de manière efficace et équitable;
les résultats sont exacts et impartiaux;
chaque personne au Canada a une chance équitable d’être représentée.
À mesure que les technologies et nouveaux outils d’analyse évoluent, nous perfectionnons nos processus afin de réduire le fardeau des participantes et des participants, tout en maintenant les normes de qualité les plus élevées. Tous nos travaux sont guidés par un cadre de qualité axé sur la pertinence, l’exactitude, l’actualité, la cohérence, l’accessibilité et l’intelligibilité.
Vos renseignements personnels sont toujours protégés
Chaque enquête est assujettie à des règles strictes visant à protéger vos renseignements personnels. Vos réponses sont confidentielles et utilisées uniquement à des fins statistiques. Avant de lancer une enquête, nous prenons soin de déterminer les données qui sont absolument nécessaires, afin de nous assurer que les avantages pour la population canadienne justifient le temps à investir et les considérations liées à la vie privée.
Nous utilisons des mesures de protection des renseignements personnels et des contrôles de divulgation rigoureux, ainsi que des systèmes sécurisés et des méthodes éprouvées, afin qu’aucune personne ou entreprise ne puisse être identifiée dans les statistiques que nous publions.
L’importance de votre participation
Les renseignements que vous fournissez servent à produire les statistiques qui appuient les programmes, les politiques et les services partout au Canada, qu’il s’agisse des écoles, des hôpitaux, de l’emploi ou du logement. Bien que cela ne soit pas toujours évident, un grand nombre de décisions importantes qui ont une incidence sur la vie quotidienne et le bien-être à long terme des Canadiennes et des Canadiens sont fondées sur les renseignements produits par Statistique Canada.
Grâce à votre participation, les décisions prises par les gouvernements, les entreprises et les collectivités sont fondées sur des renseignements exacts, complets et représentatifs. Nous recueillons des données pour nous aider à mieux comprendre notre pays, y compris sa population, ses ressources, son économie, son environnement, sa société et sa culture.
Si vous ou votre entreprise êtes sélectionnés pour participer à une enquête de Statistique Canada, merci d’y prendre part. Votre contribution aide à produire des données fiables qui reflètent l’expérience de toutes les Canadiennes et tous les Canadiens.
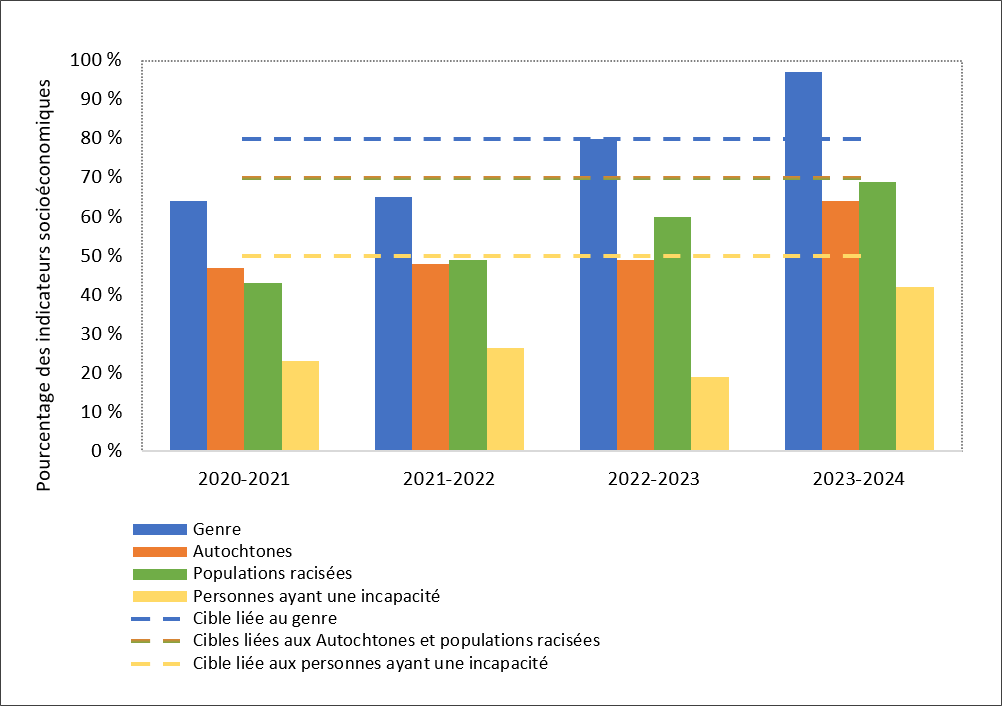
Depuis son lancement en 2021, le Plan d'action sur les données désagrégées (PADD) a pour objectif de fournir les bonnes données, au bon moment et aux bonnes personnes afin que les politiques, les programmes et les services rendent compte des réalités vécues par tous les Canadiens et toutes les Canadiennes. En améliorant la façon dont les données sont recueillies, analysées et partagées, le PADD permet aux administrations publiques, aux entreprises et aux collectivités de bâtir une société plus inclusive et plus équitable.
À la base, le PADD a été conçu pour améliorer la qualité et la disponibilité des statistiques pour quatre groupes de population visés par l'équité en matière d'emploi, à savoir les femmes, les Autochtones (Premières Nations, Métis et Inuit), les populations racisées (divers sous-groupes) et les personnes ayant une incapacité (divers sous-groupes).
Sachant que l'identité comporte de multiples facettes et que le contexte importe beaucoup, dans la mesure du possible, les données sont ventilées par genre, origine ethnoculturelle, âge, orientation sexuelle et région géographique. Statistique Canada s'efforce également de désagréger les données au-delà des indicateurs d'identité, selon le taux d'activité ou la taille de l'entreprise, par exemple.
Le Rapport sur les réalisations liées aux données désagrégées de 2024-2025 met en lumière des renseignements clés tirés des analyses de données désagrégées et la façon dont ces renseignements orientent les décisions en matière de politiques et de programmes. Bien que le présent rapport porte sur l'exercice 2024-2025, les progrès qu'il souligne s'appuient sur les efforts fondamentaux amorcés en 2021.
Le rapport est organisé en sections thématiques : L'inclusion économique grâce aux données, Les conditions sociales, Pleins feux sur l'équité en santé et Renforcement de la capacité pour l'équité. Une autre section, Répercussions sur l'ensemble du gouvernement, décrit la façon dont d'autres ministères et organismes gouvernementaux tirent parti des données désagrégées pour orienter l'élaboration des politiques et des programmes et éclairer la prise de décisions.
L'inclusion économique grâce aux données
Les renseignements tirés de l'Enquête canadienne sur la situation des entreprises (ECSE) et de l'Enquête sur la population active (EPA) ont le potentiel d'éclairer la prise de décisions, notamment dans les secteurs du travail, de l'emploi et des entreprises. En voici quelques faits saillants.
Selon les données du supplément de l'EPA, en août 2023, les travailleurs philippins et noirs étaient plus susceptibles d'occuper plusieurs emplois.
Plus précisément, 8,4 % des travailleurs philippins occupaient plusieurs emplois, comparativement à 5,3 % des travailleurs non racisés et non autochtones. De même, un pourcentage plus élevé de travailleurs noirs (7,4 %) que de travailleurs non racisés et non autochtones occupaient plusieurs emplois en 2023. Les travailleurs noirs étaient surreprésentés dans le secteur des soins de santé et de l'assistance sociale (20,7 %), et les employés noirs (33,0 %) étaient plus susceptibles de figurer dans le quartile le plus bas de l'échelle de rémunération hebdomadaire que leurs homologues non racisés (23,3 %).
Depuis 2022, les données du programme de suppléments de l'EPA ont permis à Statistique Canada de publier annuellement des indicateurs du marché du travail pour les personnes ayant une incapacité et les personnes sans incapacité. Ces données viennent compléter le portrait détaillé fourni par l'Enquête canadienne sur l'incapacité (ECI), une enquête menée tous les cinq ans et qui constitue la source officielle de données sur le taux d'incapacité au sein de la population canadienne.
Selon ces enquêtes, en 2024, la moitié (50,4 %) des personnes ayant une incapacité faisaient partie de la population active, comparativement à 7 personnes sans incapacité sur 10 (70,2 %). Bien que les hommes aient tendance à avoir un taux d'activité plus élevé que l'ensemble des femmes, l'écart entre le taux d'activité des hommes et celui des femmes est plus faible ou inexistant chez les personnes ayant une incapacité, notamment parce que le fait d'avoir une incapacité a une incidence plus importante sur le taux d'activité des hommes.
En juin 2024, les petites entreprises au Canada ont joué un rôle important dans l'emploi des Canadiens. Cependant, selon les données recueillies dans le cadre de l'ECSE entre avril et mai 2024, les petites entreprises étaient moins susceptibles d'embaucher à court terme. En fait, 5,0 % des entreprises comptant de 1 à 19 employés s'attendaient à ce que le nombre de postes vacants augmente au cours des trois prochains mois, comparativement à 11,6 % des entreprises de 20 à 99 employés et à 9,8 % des entreprises de 100 employés ou plus.
Selon les données sur la représentation des femmes et des hommes dans divers rôles en milieu de travail, recueillies dans le cadre de l'ECSE entre janvier et mars 2025, les femmes occupaient 36,6 % des postes de cadres supérieurs, tandis que les hommes occupaient 63,4 % de ces postes. Dans tous les autres postes de cadres, les femmes représentaient 46,4 % de la main-d'œuvre, comparativement à 53,6 % chez les hommes. Pour les postes de non-cadres, les femmes représentaient 43,8 % de la main-d'œuvre, tandis que les hommes représentaient 56,2 %. Ces données reflètent la répartition selon le genre entre les différents niveaux d'emploi, soulignant les disparités continues dans les rôles de haute direction.
La plupart des personnes occupées ayant une incapacité se heurtent à des obstacles en milieu de travail.
Selon les données recueillies dans le cadre de la Série d'enquêtes sur l'accessibilité de 2024, qui portait sur les expériences en matière d'accessibilité et d'emploi, 69 % des personnes occupées âgées de 15 à 64 ans et ayant une incapacité ou un problème de santé de longue durée ont été confrontées à des obstacles liés à l'accessibilité en milieu de travail. Le type d'obstacle le plus fréquemment signalé par ces personnes était les difficultés liées à la déclaration de l'incapacité (50 %), suivies de près des obstacles liés à l'environnement physique, 49 % des membres de ce groupe de population ayant déclaré avoir rencontré de tels obstacles en milieu de travail.
Parmi les autres réalisations dans le domaine du travail et de l'emploi, mentionnons l'élaboration de questions sur l'incidence de l'intelligence artificielle (IA) sur l'économie canadienne, qui révèlent la façon dont certains groupes de travailleurs, comme les personnes qui vivent en milieu urbain, les femmes, les personnes à revenu élevé et les personnes très scolarisées, sont plus susceptibles que d'autres groupes d'occuper des emplois qui pourraient être très exposés à la transformation de l'emploi liée à l'IA (consultez l'article intitulé Exposition à l'intelligence artificielle dans les emplois au Canada : estimations expérimentales pour en apprendre davantage).
Les conditions sociales
Statistique Canada recueille des données sur des indicateurs sociaux au moyen d'une multitude d'enquêtes et d'outils. En voici quelques faits saillants.
Selon les données déclarées par la police, le taux de victimes d'homicide est plus élevé chez les Autochtones que chez les non‑Autochtones, et près du tiers des victimes d'homicide sont des personnes racisées.
Malgré la baisse globale du nombre d'homicides, la police a fait état de 225 victimes d'homicide autochtones en 2024, soit 29 de plus qu'en 2023. En 2024, le taux d'homicides chez les Autochtones (10,84 homicides pour 100 000 Autochtones) était environ huit fois plus élevé que celui enregistré au sein de la population non autochtone (1,35 homicide pour 100 000 non-Autochtones).
Depuis 2014, première année pour laquelle des renseignements complets sur l'identité autochtone des victimes d'homicide ont été déclarés, les Autochtones sont surreprésentés parmi les victimes d'homicide. Par exemples, la plus grande part de l'augmentation du nombre de femmes victimes d'homicide s'observe principalement chez les femmes autochtones, et le nombre de femmes autochtones victimes d'homicide s'est accru de 21 en 2024 par rapport à l'année précédente.
Selon les données déclarées par la police, 226 victimes d'homicide étaient des personnes racisées (personnes faisant partie d'une minorité visible définie par la Loi sur l'équité en matière d'emploi) en 2024, ce qui représente 29 % des victimes d'homicide cette année-là. Cette proportion est semblable à celle enregistrée en 2023.
Selon les données recueillies dans le cadre de la Série d'enquêtes sur les gens et leurs communautés, le fait d'avoir des liens sociaux atténue les préjudices associés à la discrimination. En 2023-2024, 45 % de tous les Canadiens racisés ont déclaré avoir été victimes de discrimination au cours des cinq années précédentes. La discrimination est associée à des répercussions négatives sur la santé mentale et physique, à des niveaux inférieurs de satisfaction à l'égard de la vie et à un optimisme moindre quant à l'avenir. Toutefois, ces effets sont moins prononcés lorsque les victimes d'actes discriminatoires ont des réseaux de soutien personnels solides.
Parmi les Canadiens racisés ayant déclaré avoir été victimes de discrimination au cours des cinq années précédentes, le tiers (33 %) ont indiqué avoir un niveau élevé de satisfaction à l'égard de la vie (note de 8 ou plus sur une échelle de 10 points). Cette proportion passait à 47 % chez les victimes ayant des liens solides avec les membres de leur famille et à 49 % chez celles ayant des liens solides avec leurs amis.
Les dons de bienfaisance témoignent de la solidarité citoyenne à l'égard de différentes causes et jouent un rôle essentiel dans le soutien des initiatives sociales menées par les organisations à but non lucratif. Selon l'Enquête sur le don, le bénévolat et la participation de 2023, le taux de bénévolat global et le nombre d'heures consacrées au bénévolat ont diminué de 2018 à 2023. Le taux de bénévolat global, qui comprend le bénévolat encadré et le bénévolat informel, a diminué de 8 % durant cette période. Près de 3 personnes sur 4 (73 %) avaient fait du bénévolat en 2023, comparativement à un peu moins de 4 personnes sur 5 (79 %) en 2018.
Parallèlement, le nombre total d'heures de bénévolat encadré et informel effectuées par la population canadienne est passé de 5,0 milliards d'heures en 2018 à 4,1 milliards d'heures en 2023, ce qui représente un recul de 18 %. En moyenne, les personnes ayant fait du bénévolat y ont consacré 173 heures en 2023, une baisse de 33 heures par rapport à 2018. Les femmes, les jeunes adultes âgés de 25 à 34 ans et les personnes ayant un niveau de scolarité inférieur au diplôme d'études secondaires ont affiché les reculs les plus prononcés du taux de bénévolat encadré.
Selon les données de l'Enquête sur l'emploi du temps de 2022, les parents qui faisaient du télétravail passaient plus de temps par jour à s'occuper de leurs enfants, à les superviser ou à être avec eux. Plus précisément, ces données indiquent qu'en 2022, les parents qui télétravaillaient ont consacré en moyenne 71 minutes de plus par jour à ces activités que les parents qui ne télétravaillaient pas. L'écart entre les personnes qui faisaient du télétravail et celles qui n'en faisaient pas était plus marqué chez les pères, qui passaient respectivement 272 minutes et 201 minutes avec leurs enfants par jour. Toutefois, dans l'ensemble, les mères consacraient toujours en moyenne 52 minutes de plus par jour aux soins des enfants que les pères, peu importe la situation de télétravail.
Ces résultats indiquent que le télétravail est associé à une participation plus élevée des parents aux soins des enfants et au temps passé avec leurs enfants, en particulier chez les pères. Les mères ont continué de consacrer plus de temps aux soins des enfants, ce qui démontre que les écarts entre les genres qui avaient été relevés précédemment persistent.
Au Canada, plus de 70 langues autochtones distinctes sont parlées par les membres des Premières Nations, les Métis et les Inuit.
Les peuples autochtones ont toujours insisté sur l'importance de la langue comme principal outil pour partager leur culture, leur vision du monde et leurs valeurs, ainsi que pour les transmettre aux générations futures. En 2021, environ 1 Autochtone sur 8 (237 420 personnes) a déclaré que l'acquisition d'une langue autochtone jouait un rôle clé dans la continuité culturelle. En 2022, les deux tiers (67 %) des parents d'enfants autochtones âgés de 1 à 5 ans ont déclaré qu'il était très important ou plutôt important que leurs jeunes enfants connaissent une langue autochtone.
Selon les données recueillies dans le cadre de l'Enquête sur la santé dans les collectivités canadiennes entre 2019 et 2021, environ 800 000 personnes au Canada âgées de 25 à 64 ans ont déclaré être 2ELGBTQ+. Au sein de cette population, un peu plus de 1 parent sur 10 vivait avec au moins un enfant âgé de moins de 12 ans, et les femmes étaient plus nombreuses que les hommes à être parents.
L'accès à ces renseignements, qui peuvent servir à orienter les services de garde d'enfants et les programmes connexes, est rendue possible grâce aux efforts continus de Statistique Canada visant à améliorer les données sur les populations 2ELGBTQ+. Le Canada a été un chef de file mondial dans ce domaine, devenant le premier pays, en 2021, à recueillir des données du recensement sur les personnes transgenres et non binaires. En 2026, les données sur l'orientation sexuelle seront également recueillies dans le cadre du recensement, en vue de fournir de plus amples renseignements pour appuyer la prise de décisions fondée sur des données probantes.
En 2022, 30 % des femmes âgées de 15 ans et plus avaient une incapacité, comparativement à 24 % des hommes.
Les données de l'Enquête canadienne sur l'incapacité indiquent qu'en 2022, les femmes étaient plus susceptibles que les hommes d'avoir une incapacité liée à la douleur ou à la santé mentale, les jeunes femmes (15 à 24 ans) étant deux fois plus susceptibles que les jeunes hommes d'avoir une incapacité liée à la santé mentale. Le revenu médian des femmes ayant une incapacité était inférieur de 11 % à celui des hommes ayant une incapacité (37 010 $ et 41 580 $, respectivement). Ces renseignements peuvent être utiles pour orienter l'élaboration de programmes d'emploi et faire progresser les stratégies d'inclusion en milieu de travail.
Pleins feux sur l'équité en santé
L'Enquête sur la santé dans les collectivités canadiennes (ESCC) constitue la principale source de données autodéclarées sur la santé de la population au Canada. Elle sert à recueillir de l'information sur les indicateurs sociaux comme la santé générale et la santé mentale autoévaluées, le niveau de stress quotidien et la satisfaction à l'égard de la vie. Ces indicateurs aident à évaluer la santé et le bien-être de la population, en plus de fournir un aperçu de la façon dont les perceptions des gens à l'égard de leur santé peuvent refléter leurs conditions socioéconomiques, leur qualité de vie et leur niveau d'inclusion sociale.
Les indicateurs sont examinés sous l'angle de la santé parce que les déterminants sociaux de la santé, dont le revenu, le niveau de scolarité et les expériences de discrimination, peuvent révéler des renseignements précieux sur les populations qui sont plus susceptibles de faire l'objet de racisme ou d'exclusion sociale, ou d'avoir des difficultés financières. L'ESCC est particulièrement utile pour comprendre les expériences de groupes de population particuliers, y compris les communautés racisées. Les données recueillies au moyen de l'ESCC peuvent fournir des renseignements supplémentaires sur la santé de la population diversifiée du Canada. En voici quelques faits saillants.
En 2023, un peu plus de la moitié de la population adulte ayant déclaré appartenir à une communauté racisée a évalué sa santé comme étant généralement très bonne ou excellente (55,2 %). Cette année-là, les Latino-Américains (61,2 %) et les Philippins (58,7 %) affichaient les proportions les plus élevées de personnes ayant déclaré que leur santé était généralement très bonne ou excellente. Les données de l'ESCC ont également révélé des différences plus marquées dans la perception de la santé selon l'âge parmi les groupes racisés qu'au sein de la population canadienne non autochtone et non racisée en 2023.
Par exemple, 67,3 % des Sud-Asiatiques âgés de 18 à 34 ans ont indiqué que leur santé était généralement très bonne ou excellente. Cette proportion passait à 49,8 % chez les personnes de 50 à 64 ans et à 21,2 % chez celles de 65 ans et plus. À titre de comparaison, la proportion de l'ensemble de la population adulte au Canada ayant déclaré une très bonne ou une excellente santé était de 62,1 % chez les personnes de 18 à 34 ans, de 49,3 % chez celles de 50 à 64 ans et de 40,5 % chez celles âgées de 65 ans et plus.
Les données recueillies par Statistique Canada démontrent une incidence élevée de la COVID-19 chez les Autochtones. Plus précisément, le taux de mortalité attribuable à la COVID-19 normalisé selon l'âge était plus de cinq fois plus élevé chez les femmes des Premières Nations (74,3 décès pour 100 000 habitants) que chez les femmes non autochtones (14,0 décès pour 100 000 habitants), et plus de deux fois plus élevé chez les femmes métisses (29,4 décès pour 100 000 habitants) que chez les femmes non autochtones.
Afin d'aider à combler les lacunes en matière de données pour l'examen et à mettre à jour les lignes directrices sur le dépistage du cancer du sein, Statistique Canada a fourni aux experts de la santé des données clés sur l'incidence du cancer du sein, le stade, le sous-type et le taux de mortalité selon la race et l'ethnicité.
Selon les résultats, l'incidence selon l'âge était plus élevé chez les femmes philippines et les femmes d'ethnicités multiples âgées de 40 à 49 ans, ainsi que chez les femmes arabes âgées de 50 à 59 ans, que chez les femmes blanches. Par ailleurs, les taux de mortalité selon l'âge étaient également plus élevés chez les femmes noires âgées de 40 à 49 ans et chez les femmes des Premières Nations et les femmes métisses âgées de 60 à 69 ans que chez les femmes blanches. Le cancer du sein a été diagnostiqué moins souvent au stade I chez les femmes philippines, les femmes noires, les femmes sud-asiatiques et les femmes des Premières Nations que chez les femmes blanches et les femmes chinoises.
Les données de la Série d'enquêtes auprès des membres des Premières Nations, des Métis et des Inuit, publiées en novembre 2024, mettent en lumière l'accès aux soins de santé et les expériences des Autochtones âgés de 15 ans et plus. Plus précisément, ces données indiquent que, parmi les membres des Premières Nations vivant hors réserve et les Inuit ayant subi un traitement injuste, du racisme ou de la discrimination de la part d'un professionnel de la santé, la salle d'urgence d'un hôpital (50 % chez les membres des Premières Nations vivant hors réserve et 34 % chez les Inuit) était le lieu le plus souvent mentionné comme endroit où ils avaient subi ce traitement. De plus, 36 % des Métis ont déclaré avoir vécu des expériences semblables dans ce contexte. Chez les Métis, l'endroit le plus fréquemment mentionné était le cabinet du médecin (46 %).
Statistique Canada a collaboré avec le Conseil national autochtone de la sécurité-incendie (CNASI) à la préparation d'un rapport sur les risques d'incendie chez les populations autochtones à l'aide de la Base canadienne de données des coroners et des médecins légistes couplée aux recensements de la population de 2006 et de 2016 et à l'Enquête nationale auprès des ménages de 2011. Ce travail a été effectué afin de mieux comprendre les facteurs qui contribuent à des taux de mortalité plus élevés liés aux incendies chez les populations autochtones.
Ce rapport a mis en évidence les facteurs de risque qui exposent les populations autochtones à un risque plus élevé de décès liés à un incendie, dans le but de prévenir ces types de décès dans l'avenir. En reconnaissance de ce travail de collaboration, le CNASI a remis le Prix national du leadership autochtone en prévention des incendies a été présenté à Statistique Canada, avec une plume d'aigle. La plume d'aigle, un symbole utilisé pour souligner le parcours ou les réalisations du récipiendaire, a une signification profonde dans la culture autochtone.
Renforcement de la capacité pour l'équité
Statistique Canada a joué un rôle de chef de file dans l'élaboration des normes relatives au genre de la personne et au sexe à la naissance de la personne, normes qui ont été approuvées par le gouvernement du Canada en 2023-2024. L'organisme a également élaboré des produits d'accompagnement, dont des guides de référence, afin de veiller à l'adoption de ces normes par tous les ministères fédéraux.
Statistique Canada a élaboré trois cours sur l'analyse des données désagrégées qui seront hébergés sur la plateforme de l'École de la fonction publique du Canada (EFPC). Ces cours aideront les décideurs à élaborer des politiques publiques plus ciblées et efficaces en cernant les besoins particuliers des différents groupes démographiques et les défis auxquels ces groupes sont confrontés. Le premier cours, intitulé « Élaborer des politiques efficaces grâce aux données désagrégées », a été lancé en novembre 2024. Le deuxième cours, intitulé « Élaborer des politiques efficaces grâce aux données désagrégées : Étude de cas sur l'entrepreneuriat des communautés noires », a été lancé à l'automne 2025, tandis que le troisième, intitulé « Étude de cas sur les inégalités en santé », sera lancé à l'hiver 2026.
Statistique Canada a continué de présenter son atelier interne sur l'analyse des données désagrégées et a élaboré un nouveau cours, intitulé « Sprint analytique », pour former les analystes à la rédaction de contenu évocateur fondé sur des données désagrégées. L'organisme a également continué d'intégrer une perspective de données désagrégées à tous ses cours analytiques dans le but de renforcer la désagrégation responsable des données en tant que principe clé pour générer des renseignements utiles. L'organisme a d'ailleurs offert des cours supplémentaires à l'intention de fonctionnaires externes, y compris une formation intensive pour les cadres responsables des politiques offerte aux cadres fédéraux, provinciaux, territoriaux et municipaux, qui met l'accent sur le renforcement de la capacité en matière d'analyse responsable des données désagrégées.
Répercussions sur l'ensemble du gouvernement
Au cours des dernières années, Statistique Canada a considérablement amélioré l'environnement des données en augmentant la disponibilité des données désagrégées. Ces progrès, stimulés par des initiatives comme le Plan d'action sur les données désagrégées (PADD) et un changement de culture plus vaste au sein de l'organisme, ont entraîné des répercussions considérables à l'échelle du gouvernement du Canada.
L'un des principaux exemples de la façon dont les données désagrégées sont mises à profit dans l'ensemble des politiques et programmes du gouvernement fédéral réside dans l'application de l'Analyse comparative entre les sexes Plus (ACS Plus), y compris les données du Carrefour de statistiques sur le genre, la diversité et l'inclusion de Statistique Canada, afin de mieux comprendre la manière dont les facteurs identitaires, sociaux et structurels qui se recoupent façonnent les résultats en matière de santé. Cette approche appuie la prise de décisions fondée sur des données probantes et contribue à faire progresser l'équité, en veillant à ce que les politiques et les programmes publics tiennent compte de diverses expériences vécues. L'application du Cadre des résultats relatifs aux genres (CRRG) démontre l'engagement du gouvernement fédéral à promouvoir l'égalité des genres grâce à des investissements importants dans des programmes, des politiques et des initiatives clés.
Alors que l'ensemble des ministères et organismes fédéraux mettent en œuvre certaines des initiatives, comme celle du CRRG, un grand nombre d'entre eux tirent également parti des données désagrégées et des renseignements qui peuvent être tirés d'analyses de données désagrégées pour orienter leur propre prestation de programmes et l'élaboration de politiques.
Emploi et Développement social Canada
Emploi et Développement social Canada (EDSC) intègre l'ACS Plus et l'analyse détaillée dans son continuum de politiques et de services. Dans le cadre de cette approche, EDSC utilise régulièrement des données désagrégées pour orienter l'élaboration de politiques et de programmes et approfondir la compréhension des besoins et des expériences des clients, ainsi que des répercussions des programmes et des services.
EDSC utilise des données désagrégées pour éclairer le Plan d'action pour l'inclusion des personnes en situation de handicap et la mise en œuvre continue de la Loi canadienne sur l'accessibilité (LCA). En plus de collaborer avec Statistique Canada à la collecte de données désagrégées sur l'accessibilité afin d'aider à cerner et à éliminer les obstacles, EDSC tire parti des principales données désagrégées de l'Enquête canadienne sur l'incapacité pour générer des renseignements de base sur les obstacles à l'accessibilité liés aux sept domaines prioritaires de la LCA, y compris des connaissances sur les obstacles en lien avec le type et la sévérité de l'incapacité. L'inclusion du module sur les obstacles, qui explore les expériences liées à des types précis d'obstacles à l'accessibilité, dans l'ECI 2022 et dans les cycles suivants de l'enquête aidera EDSC à mesurer les progrès réalisés pour éliminer les obstacles à l'accessibilité au fil du temps.
EDSC a aussi tiré parti des données administratives désagrégées sur la Prestation canadienne d'urgence (PCU) et des données provenant d'enquêtes nationales clés, comme les recensements de 2016 et de 2021, l'Enquête sur la population active, l'Enquête canadienne sur le revenu et la Base de données longitudinales sur l'immigration pour évaluer l'incidence de la PCU. Ces données ont permis de réaliser des analyses nuancées sur l'utilisation des prestations et la dynamique du marché du travail dans divers groupes de population (comme la durée de la PCU selon la profession et l'industrie, les tendances de l'offre de main-d'œuvre, la possibilité de travailler à distance), et sur les expériences des groupes vulnérables. En outre, ces données ont été utilisées pour cerner les lacunes en matière de services parmi les populations sous-représentées et pour apporter des changements ciblés aux politiques afin d'améliorer l'accessibilité et l'équité pour ce qui est des programmes.
Les données désagrégées du Recensement de la population de 2021 ont également joué un rôle clé dans le soutien au Groupe de travail sur l'examen de la Loi sur l'équité en matière d'emploi d'EDSC. En effet, EDSC s'est appuyé sur la diffusion de Statistique Canada portant sur la langue de travail pour intégrer des indicateurs liés à l'équité dans son rapport final. Ces indicateurs comprenaient des ventilations détaillées du niveau de scolarité, du revenu, du statut d'immigrant, de l'identité autochtone, du genre et de l'appartenance à une minorité visible.
De plus, des données désagrégées ont permis à EDSC d'examiner les répercussions de la COVID-19 et de l'inflation sur l'abordabilité du logement au Canada. L'utilisation de sources de données, y compris l'Enquête sur la population active (2019 à 2023), le Recensement de 2021 et l'Enquête canadienne sur le logement (2018, 2021 et 2022), entre autres, a permis de démontrer que la population canadienne à faible revenu était la plus touchée, et qu'elle était confrontée à des pertes de revenus plus importants, à des niveaux d'endettement plus élevés et à des coûts de logement plus élevés. Ces constatations ont permis de cerner les principales répercussions sur le plan des politiques, y compris la nécessité d'augmenter les salaires grâce au développement du capital humain et d'accroître la main-d'œuvre dans les métiers spécialisés pour répondre aux besoins en matière de construction de logements.
Immigration, Réfugiés et Citoyenneté Canada
Immigration Réfugiés et Citoyenneté Canada (IRCC) utilise régulièrement des données désagrégées pour orienter l'élaboration de ses politiques et de ses programmes, ainsi que pour mieux comprendre les enjeux liés à ses programmes. Par exemple, en 2025, IRCC a entrepris un projet de recherche pour examiner les résultats économiques des réfugiés qui sont arrivés au Canada entre 2011 et 2021. IRCC a utilisé diverses sources pour ce produit, y compris des tableaux de données du Recensement de 2021 qui ont été ventilés spécifiquement au niveau des divers sous-volets du Programme de réinstallation (réfugiés parrainés par le gouvernement et réfugiés parrainés par le secteur privé) ainsi que selon la période d'immigration. Les variables examinées comprenaient, entre autres, le plus haut niveau de scolarité atteint, le mode d'occupation du logement (propriétaire ou non), l'obtention de la citoyenneté.
Les données désagrégées ont été utilisées pour évaluer l'ajout ou le retrait de professions prioritaires pour la sélection des immigrants. Des renseignements ont ainsi été fournis au sujet des répercussions sur les régions, les salaires, l'emploi et le genre aux fins d'une ACS Plus complète pour la sélection par catégorie. IRCC juxtapose également les données de Statistique Canada avec ses propres données sur les visiteurs internationaux pour adapter les décisions stratégiques en matière de visas qui maximisent les avantages économiques, notamment en attirant les meilleurs talents, tout en réduisant les risques de migration irrégulière, les menaces à la sécurité et les pressions exercées sur les programmes publics.
Patrimoine canadien
Patrimoine canadien (PCH) a également tiré parti des données du PADD pour appuyer des initiatives clés, y compris la Stratégie canadienne de lutte contre le racisme et le Plan d'action canadien de lutte contre la haine. La collaboration entre Statistique Canada et PCH a d'ailleurs permis d'appuyer le Bureau de la représentante spéciale du Canada chargée de la lutte contre l'islamophobie, ce qui a mené à la publication d'une infographie sur la population musulmane au Canada en décembre 2024 et continue d'éclairer les rapports du Canada aux Nations Unies sur les instruments internationaux relatifs aux droits de la personne.
PCH s'appuie particulièrement sur les données désagrégées du recensement, de l'Enquête sociale générale et de la Série d'enquêtes sur les gens et leurs communautés pour mesurer les répercussions de ses programmes et politiques. À cet égard, des thèmes comme le sentiment d'appartenance, les valeurs communes, la fierté relativement à la culture et aux arts canadiens, la satisfaction à l'égard de la vie ainsi que les expériences de racisme et de discrimination sont essentiels.
PCH utilise aussi des données désagrégées pour appuyer les demandes budgétaires, la planification, la gouvernance de haut niveau et une multitude de décisions en matière de politiques et de programmes. Les variables d'identité rendues disponibles par Statistique Canada, y compris le genre, l'ethnicité et l'âge, fournissent à PCH les données essentielles dont le ministère a besoin pour examiner l'inclusion, la diversité, l'équité et l'accessibilité.
Relations Couronne-Autochtones et Affaires du Nord Canada
Relations Couronne-Autochtones et Affaires du Nord Canada (RCAANC) utilise des données désagrégées pour mieux comprendre les enjeux qui touchent les peuples autochtones selon la distinction et la région. Par exemple, RCAANC se sert des valeurs de l'Indice de bien-être des communautés, qui sont établies à partir des données désagrégées du recensement, pour produire des rapports sur les conditions socioéconomiques et le bien-être des communautés autochtones à l'étendue du Canada.
Dans le cadre de la mise en œuvre de sa stratégie de données, RCAANC prend des mesures pour intégrer les données désagrégées à ses processus courants d'élaboration de politiques et de programmes, au-delà de la présentation des résultats. Ces efforts sont largement appuyés par la disponibilité accrue des données désagrégées de Statistique Canada depuis 2021. En effet, des données de plus en plus détaillées ont permis à RCAANC de mieux comprendre les disparités socioéconomiques et en matière de santé auxquelles sont confrontées les communautés des Premières Nations, métisses et inuites par rapport aux autres Canadiens et Canadiennes.
Les efforts déployés à ce jour ont permis d'appuyer des approches plus ciblées dans des domaines comme le logement, le développement économique autochtone et les programmes sociaux dans les collectivités nordiques et éloignées. Ces renseignements peuvent aider à éclairer la prise de décisions, à favoriser des résultats plus équitables et à cerner les lacunes en matière de données qui doivent être comblées au moyen de partenariats plus solides et d'une gouvernance des données avec les peuples autochtones.
Agence de la santé publique du Canada
L'Agence de la santé publique du Canada (ASPC) tire parti des données désagrégées pour cibler ses efforts en matière de promotion, de programmes et de politiques, comme le Plan d'action national pour la prévention du suicide et le Fonds pour la santé des Canadiens et des communautés.
Les données servent également à éclairer les articles de recherche examinés par des pairs pour la production de rapports sur des sujets comme la mortalité liée à l'hépatite B et C, la mortalité liée au VIH, les estimations démographiques des utilisateurs de drogues par injection au Canada et les estimations démographiques des hommes ayant des relations sexuelles avec d'autres hommes. En outre, les données servent à mener ou à compléter des activités de surveillance de la santé publique portant notamment sur les commotions cérébrales, les chutes et d'autres blessures, la santé mentale, l'activité physique, le comportement sédentaire, le sommeil et l'obésité.
De plus, l'ASPC utilise des données désagrégées pour appuyer la mobilisation intersectorielle. Les études de la Chambre des communes sur la santé des communautés LGBTQIA2Note de bas de page 1, les mémoires au Cabinet sur la littératie alimentaire, l'Initiative sur la santé mentale des communautés noires, ainsi que la mobilisation de l'ASPC à l'égard de la Stratégie canadienne de lutte contre le racisme 2.0 et du Plan d'action fédéral 2ELGBTQI+ témoignent de ces efforts.
L'ASPC utilise également des données désagrégées pour enrichir et mettre à jour des outils comme le tableau de bord État de santé des personnes au Canada et l'outil Données des inégalités en santé. Le tableau de bord donne un aperçu de la santé de nos populations, tout en illustrant le large éventail de facteurs sanitaires, socioéconomiques et environnementaux qui interagissent pour assurer la bonne santé et le bien-être des Canadiens et Canadiennes. L'outil Données des inégalités en santé tire parti de multiples ensembles de données et variables aux fins d'analyses, ce qui permet à l'ASPC de fournir aux principaux intervenants des données détaillées propres à la population qui quantifient l'ampleur des inégalités en santé au Canada, y compris des ventilations à l'échelle des provinces et des territoires. Cela appuie la prise de décisions et la planification stratégique au sein de l'ASPC et par ses partenaires externes en fournissant des renseignements accessibles au public et téléchargeables.
Ensemble, ces initiatives soulignent un changement transformateur dans la façon dont les données sont utilisées dans l'ensemble du gouvernement fédéral. L'importance croissante accordée aux données désagrégées renforce non seulement le caractère inclusif des politiques et des programmes, mais aussi un engagement à prendre des décisions fondées sur des données probantes qui répondent mieux aux divers besoins de la population canadienne.
À mesure que le Canada continue d'évoluer, les données qui éclairent les décisions qui le concernent doivent elles aussi évoluer. Au cours des dernières années, le PADD a jeté des bases solides pour l'élaboration de politiques inclusives, adaptées et équitables. Une collaboration et une innovation soutenues seront essentielles dans l'avenir pour approfondir notre compréhension des diverses expériences vécues et faire en sorte que tous les Canadiens et toutes les Canadiennes soient pris en compte, entendus et servis.
La Loi sur l’accès à l’information établit le principe selon lequel le public a le droit d’avoir accès à l’information relevant des institutions gouvernementales fédérales et stipule que les exceptions à ce droit devraient être précises et limitées.
Le Rapport annuel sur l’application de la Loi sur l’accès à l’information est préparé et soumis conformément à l’article 94(1) de Loi et couvre la période allant du 1er avril 2024 au 31 mars 2025. Le rapport est déposé au Parlement.
Mandat de Statistique Canada
Le mandat de Statistique Canada découle principalement de la Loi sur la statistique. En vertu de cette loi, l’organisme a la responsabilité de recueillir, de compiler, d’analyser et de publier de l’information statistique sur les conditions économiques, sociales et générales du pays et de sa population. La Loi exige également que Statistique Canada coordonne le système statistique national, en particulier pour éviter le double emploi dans la collecte des renseignements par le gouvernement. À cette fin, le statisticien en chef peut conclure des ententes de collecte conjointe ou de partage de données avec les organismes statistiques provinciaux et territoriaux, ainsi qu’avec les ministères fédéraux, provinciaux et territoriaux en application des dispositions de la Loi.
Administration de la Loi sur l’accès à l’information
Aux termes de l’article 24 de la Loi sur l’accès à l’information, qui est une disposition impérative, l’information recueillie en vertu de la Loi sur la statistique et protégée par l’article 17 de cette loi ne peut être communiquée à qui que ce soit essayant de l’obtenir en vertu de la Loi sur l’accès à l’information. Grâce à cette exception, Statistique Canada peut continuer à garantir aux répondants de façon claire et absolue que les dispositions relatives à la confidentialité de la Loi sur la statistique sont préservées par la Loi sur l’accès à l’information.
Filiales non opérationnelles
Statistique Canada n’avait pas de filiales non opérationnelles durant la période du 1er avril 2024 au 31 mars 2025.
Structure organisationnelle
Le directeur ou la directrice du Bureau de gestion de la protection de la vie privée et de coordination de l’information veille à l’application de la Loi sur l’accès à l’information et de la Loi sur la protection des renseignements personnels au sein de Statistique Canada.
Statistique Canada travaille également avec les Canadiens et les Canadiennes pour contribuer à informer la population des procédures existantes d’accès à l’information du gouvernement, en expliquant par exemple les différences entre les demandes d’ensembles de données, de tableaux de données et de tableaux de données personnalisées et les demandes d’accès à l’information pour les enregistrements et dossiers existants sous le contrôle de l’établissement institutionnel. Un processus de recouvrement des coûts existe déjà et est accessible au public. Ces demandes de données sont traitées plus précisément par le programme InfoStats de Statistique Canada.
Le Bureau de l’accès à l’information et de la protection des renseignements personnels (AIPRP) compte sur un effectif de 2,13 années-personnes. Un gestionnaire de l’AIPRP, un analyste principal ou une analyste principale de l’AIPRP et un ou une analyste subalterne de l’AIPRP ont travaillé à temps plein au traitement des demandes. Aucun consultant n’a été embauché durant la période de déclaration, et aucune entente de service en vertu de l’article 96 de la Loi sur l’accès à l’information à laquelle Statistique Canada aurait pu participer n’était en place au cours de la période de déclaration.
Le bureau du statisticien en chef et les bureaux des statisticiens en chef adjoints et des statisticiennes en chef adjointes sont responsables de la mise en oeuvre de la publication proactive. Les renseignements sont téléversés sur le site Web du Gouvernement ouvert dans les délais prévus par la loi. De plus amples renseignements sur la publication proactive se trouvent dans la section du présent rapport intitulée « Publication proactive en vertu de la partie 2 de la Loi sur l’accès à l’information ».
Ordonnance de délégation
L’ordonnance de délégation définit la délégation de l’exercice des pouvoirs et des fonctions du ou de la ministre en sa qualité de responsable d’une institution fédérale, conformément à l’article 95(1) de la Loi sur l’accès à l’information. Les pouvoirs figurant sur la liste détaillée actuelle en vertu de la Loi sur l’accès à l’information ont été officiellement délégués par le ministre de l’Innovation, des Sciences et du Développement économique en date de mai 2021 (annexe A), prévoyant une pleine délégation des pouvoirs au directeur ou à la directrice et au directeur adjoint ou à la directrice adjointe du Bureau de gestion de la protection de la vie privée et de coordination de l’information.
Exécution de la partie 1 de la Loi sur l’accès à l’information
Rapport statistique
Le rapport statistique fournit des données agrégées sur l’application de la Loi sur l’accès à l’information. Ces renseignements sont rendus publics chaque année et sont inclus dans le rapport annuel.
Demandes d’accès à l’information
Décisions rendues au regard des demandes traitées au cours de la période visée
Décisions rendues au regard des demandes
Nombre de demandes
Communication totale
19
Communication partielle
12
Aucune communication
3
Aucun document n’existe
19
Demande abandonnée
2
Demande transférée
0
Total
55
Au cours de la période visée, soit du 1er avril 2024 au 31 mars 2025, Statistique Canada a reçu 63 nouvelles demandes d’accès à l’information. Cette année, aucune demande n’a été reportée de la période de déclaration précédente. Durant la période de référence, 55 demandes ont été traitées et 8 dossiers ont été reportés à la période de référence suivante. Durant la période de référence, 85.45 % des demandes ont été traitées à temps.
Le public, les médias et les entreprises (secteur privé) ont constitué les principaux groupes de clients, ayant représenté 55 des 63 demandes reçues au cours de la période de référence.
Pour les demandes traitées, tous les dossiers ont été communiqués totalement ou partiellement pour 31 demandes, les renseignements ont été entièrement protégés ou exclus pour 3 demandes, aucun dossier n’existait pour 19 demandes, 2 demandes ont été abandonnées par les demandeurs et aucune demande n’a été transférée à une autre institution fédérale.
Pour répondre aux demandes officielles d’accès à l’information, il a fallu examiner 7 387 pages et 6 341 de ces pages ont été diffusées. Au total, 31 demandeurs ont reçu de l’information par voie électronique.
Le tableau ci-dessous illustre la plus récente tendance pour les cinq dernières années en ce qui concerne le traitement des demandes d’accès à l’information reçues par l’organisme.
Tendance pour les cinq dernières années en ce qui concerne le traitement des demandes d'accès à l'information reçues par l'organisme
Exercice financier
Demandes reçues
Demandes traitées
Nombre de pages traitées
Nombre de pages communiquées
2024-2025
63
55
7 387
6 341
2023-2024
58
61
12 358
5 782
2022-2023
50
85
82 894
37 021
2021-2022
79
97
25 550
4 849
2020-2021
98
84
5 888
4 480
Types de documents demandés
La teneur des demandes couvrait la gamme complète des questions qui relèvent du rôle de Statistique Canada et concernaient les types de renseignements suivants :
Divers renseignements statistiques;
Les dépenses consignées;
Les contrats de services professionnels;
Les notes d’information du statisticien en chef.
Autres demandes
Du 1er avril 2024 au 31 mars 2025, Statistique Canada a aussi reçu 31 demandes de consultation soumises par d’autres ministères et organismes gouvernementaux en vertu de la Loi sur l’accès à l’information. L’organisme a dû examiner 1 092 pages d’information; 12 consultations ont été traitées dans un délai de 1 à 15 jours, 8 consultations ont été traitées dans un délai de 16 à 30 jours et 4 consultations ont été traitées dans un délai de 31 à 60 jours.
Des résumés des demandes traitées en vertu de la Loi sur l’accès à l’information sont publiés sur le « Portail du gouvernement ouvert ». Les demandes visant l’obtention d’une copie des demandes traitées ainsi que les demandes qui n’ont pas été traitées en vertu de la Loi sont classées comme des demandes non officielles. Au cours de l’exercice, Statistique Canada a reçu 126 demandes non officielles et a traité 42 demandes au cours de la période de référence. De plus, 83 demandes ont été reportées au prochain exercice. L’écart important est principalement attribuable à une pénurie de personnel expérimenté au sein de la sous-section chargée de l’AIPRP.
Le Bureau de l’AIPRP a agi comme ressource pour les fonctionnaires de Statistique Canada en leur offrant conseils et orientation sur les dispositions de la Loi. Le Bureau a été consulté relativement à la divulgation et à la collecte de données touchant une vaste gamme de sujets, dont :
Les publications proactives qui devront être affichées sur le portail du gouvernement ouvert;
La divulgation proactive sur les voyages et l’accueil;
Les évaluations fondées sur le Cadre de responsabilisation de gestion;
La sécurité des renseignements;
L’examen des vérifications à afficher sur Internet;
L’examen des questions et des réponses parlementaires;
La mise à jour des sites Internet et intranet du Bureau de l’AIPRP;
L’examen et la mise à jour des pratiques et des procédures opérationnelles en matière d’AIPRP;
Le soutien offert pour sensibiliser autrui à la gestion de l’information.
Tendances concernant les dispositions prises à l’égard des demandes traitées
Les décisions rendues concernant les 55 demandes traitées en 2024-2025 sont les suivantes :
19 communications totales (34,5 %);
12 communications partielles (21,8 %);
3 exemptions/exclusions intégrales (5,5 %);
2 demandes ont été abandonnées par les demandeurs (3,6 %);
19 demandes visant de l’information qui n’existait pas (34,5 %);
Aucune demande n’a été transférée à un autre ministère (0 %).
dispositions prises à l'égard des demandes traitées
Demandes d’accès à l’information (exercice financier)
2024-2025
Demandes reçues
63
Demandes traitées
55
Demandes traitées (en pourcentage)
87 %
Délais de traitement et prorogations
Des 63 demandes reçues et traitées au cours de l’exercice 2024-2025, 47 ont été fermées dans les délais prescrits par la Loi, ce qui représente un taux de conformité de 75 %. Le Bureau de l’AIPRP a eu de la difficulté à examiner et traiter les nouvelles demandes reçues dans les délais prescrits par la Loi en raison du manque de personnel expérimenté et qualifié. Au total, 8 demandes ont été retardées en raison de complexités imprévues et d’une expérience insuffisante de la part du gestionnaire intérimaire et de l’analyste subalterne, ce qui n’a pas permis de présenter les demandes de prorogation en temps utile. Au nombre des facteurs ayant contribué à la capacité de Statistique Canada de répondre aux demandes en temps opportun au cours de la dernière année figurent les séances de formation, de sensibilisation et d’information qu’elle offre à l’ensemble des chefs et membres du personnel de l’organisme.
Le taux de conformité pour les demandes traitées est le suivant :
14 dans un délai de 1 à 15 jours (25 %);
25 dans un délai de 16 à 30 jours (45 %);
11 dans un délai de 31 à 60 jours (20 %);
5 dans un délai de 61 à 120 jours (9 %).
Sur les 63 demandes traitées, 8 ont fait l’objet d’une prorogation du délai parce que la demande entravait le fonctionnement de l’organisme ou à cause de la nécessité de consulter d’autres institutions fédérales et tierces parties.
Formation et sensibilisation
En 2024-2025, le Bureau de l’AIPRP a poursuivi la formation officielle pour tout le personnel de l’organisme. Elle comprenait une formation à l’intention des cadres supérieurs, des gestionnaires et des membres du personnel sur les processus et les procédures en matière d’AIPRP pour faciliter la récupération et l’approbation des dossiers. Le Bureau de l’AIPRP a également fourni des conseils et une expertise aux cadres supérieurs sur leurs responsabilités en vertu de la Loi et les délégations de pouvoirs afférentes pour assurer des procédures adéquates de gestion des dossiers et de récupération et approbation des documents. La formation de cette année visait à assurer que tous les bureaux des statisticiens en chef adjoints et des statisticiennes en chef adjointes se voient rappeler leur rôle d’agents et agentes de liaison chargés de veiller à ce que les demandes soient correctement acheminées aux secteurs de programme appropriés, y compris leurs propres équipes fonctionnelles.
La sensibilisation à l’égard de la gestion de l’information a aussi été au coeur de ces discussions aux tables de la haute direction, se concentrant principalement sur les pratiques exemplaires et les différences entre l’information éphémère et l’information ayant une valeur opérationnelle. Nous avons offert des séances de formation ciblées sur la protection des renseignements de nature délicate dans GCdocs, en mettant l’accent sur les contrôles d’accès, les types de renseignements et les classifications de sécurité. L’objectif était de fournir aux gestionnaires de programme des lignes directrices plus claires sur la classification des renseignements et d’assurer le traitement approprié des renseignements de nature délicate. Nous avons rappelé au personnel de ne pas conserver de renseignements qui pourraient être embarrassants s’ils étaient communiqués en vertu d’une demande d’AIPRP. Une formation individuelle informelle ainsi qu’une formation officielle de groupe ont été offertes pour renforcer les obligations en vertu de la Loi et clarifier les politiques et les directives de Statistique Canada en matière de gestion de l’information.
Le Bureau de l’AIPRP a créé un document d’information fournissant un aperçu du processus d’AIPRP pour les demandes d’accès à l’information et de protection de la vie privée. La formation sur l’AIPRP offerte par l’École de la fonction publique du Canada continue d’être recommandée à l’ensemble du personnel de Statistique Canada.
Politiques, directives et procédures
Le Bureau de l’AIPRP dispose de divers outils pour permettre aux personnes-ressources de bien connaître leurs rôles et leurs responsabilités relativement à la coordination des demandes d’AIPRP. Ces outils comprennent une liste de vérification décrivant le protocole approprié pour fournir au Bureau de l’AIPRP des documents pertinents pour les demandes d’accès à l’information, ainsi que les coordonnées d’une personne-ressource appropriée de l’équipe de l’AIPRP pour obtenir des éclaircissements et des directives tout au long du processus.
L’Avis de mise en oeuvre de l’accès à l’information et de la protection des renseignements personnels 2024-01, entré en vigueur le 13 novembre 2024, fournit des conseils aux institutions fédérales sur le traitement des demandes qui pourraient compromettre la sécurité ou la vie privée des fonctionnaires. L’Avis répond aux préoccupations, en particulier celles soulevées par les groupes en quête d’équité, concernant l’utilisation potentiellement abusive des demandes d’AIPRP pour cibler des personnes en fonction de leur identité personnelle plutôt que de leur conduite professionnelle. L’Avis met l’accent sur l’équilibre entre la transparence et la nécessité de protéger les fonctionnaires contre les menaces à leur bien-être physique et psychologique.
En raison de l’augmentation du nombre « d’avis d’intention de diffusion » au lieu de consultations officielles, le Bureau de l’accès à l’information a rationalisé son processus de consultation interne, notamment en révisant le libellé et en raccourcissant les délais pour tenir compte de la sensibilité réduite et des échéances plus courtes pour ce type de consultation.
Au cours de la période de déclaration, des mises à jour des procédures administratives ont été effectuées pour faciliter la récupération des documents de ressources humaines pour l’AIPRP. Étant donné que les demandes de documents de ressources humaines sont généralement moins complexes et plus récurrentes, les nouvelles procédures administratives ont accéléré l’accès à ces documents, améliorant ainsi l’efficacité du processus de récupération et les taux de réponse pour les demandeurs.
Initiatives et projets visant à améliorer l’accès à l’information
Au cours de la période de déclaration, le Bureau de l’AIPRP a réaffirmé son engagement avec des partenaires clés, dont le Secrétariat du Conseil du Trésor du Canada (SCT), Services partagés Canada (SPC), Services publics et Approvisionnement Canada (SPAC), Statistique Canada (secteur 9) et OPEXUS, en vue de faire avancer les discussions sur la modernisation des plateformes technologiques soutenant les opérations d’AIPRP. Cet effort de collaboration vise à améliorer l’efficacité, l’accessibilité et la capacité de réponse du processus d’AIPRP afin de mieux répondre aux besoins des demandeurs.
Résumé des principaux enjeux et des mesures prises à la suite des plaintes
Au cours de la période de déclaration, aucune nouvelle plainte n’a été déposée contre Statistique Canada auprès du Commissariat à l’information du Canada (CIC). Toutefois, le CIC a rouvert une plainte précédente selon laquelle la personne plaignante s’est vu refuser sans justification l’accès aux documents demandés en vertu de la Loi sur l’accès à l’information en raison de recours inapproprié à des exemptions et du défaut de répondre dans les délais prescrits. Une (1) plainte relative à un exercice antérieur a été abandonnée en raison de l’absence de réponse de la personne plaignante. Six (6) plaintes sont en cours concernant le défaut d’effectuer une recherche raisonnable, le recours inapproprié à des exemptions et le défaut de répondre dans les délais prescrits par la Loi.
Publication proactive en vertu de la partie 2 de la Loi sur l’accès à l’information
Le bureau du statisticien en chef et les bureaux des statisticiens en chef adjoints et des statisticiennes en chef adjointes sont responsables de la mise en oeuvre de la publication proactive. Les renseignements sont téléversés sur le site Web du Gouvernement ouvert dans les délais prévus par la loi.
Le Bureau de l’AIPRP travaille en collaboration avec des représentants de l’organisme pour répondre aux exigences législatives en matière de publication proactive des renseignements, conformément à la partie 2 de la Loi sur l’accès à l’information. Les articles 82 à 88 de la partie 2 de la Loi stipulent que les entités gouvernementales qui appuient un ou une sous-ministre sont tenues de publier de manière proactive les dépenses afférentes aux déplacements, les frais d’accueil, les rapports déposés au Parlement, la reclassification des postes, les contrats, les subventions et contributions, les documents d’information et les rapports sur les dépenses. À Statistique Canada, cette responsabilité incombe à la Direction des finances, de la planification et de l’approvisionnement, au Bureau du statisticien en chef et au Bureau de l’AIPRP.
Direction des finances, de la planification et de l’approvisionnement
Direction des finances, de la planification et de l'approvisionnement
Exigence législative
Article
Délai de publication
Taux de conformité
Publication proactive (lien Web)
Frais de déplacement
82
Dans les 30 jours suivant la fin du mois au cours duquel les frais ont été remboursés
La Direction des finances, de la planification et de l’approvisionnement (DFPA) encadre la publication proactive des frais de voyages et d’accueil, des contrats d’une valeur de plus de 10 000 $ et des subventions et contributions d’une valeur de plus de 25 000 $ pour l’organisme. Trois groupes de la DFPA se partagent ces responsabilités : la Division de l’approvisionnement, des systèmes financiers et des contrôles internes, qui est responsable des contrats d’une valeur de plus de 10 000 $; l’Équipe d’assurance de la qualité de la Division des opérations financières, qui est responsable des frais de voyage et d’accueil; et l’Équipe des états financiers de la Division des opérations financières, qui est responsable des subventions et contributions d’une valeur de plus de 25 000 $.
Des procédures internes sont mises en place pour veiller à l’exactitude et à l’exhaustivité des renseignements publiés. Ces procédures sont consignées par les équipes responsables, et sont révisées et recadrées régulièrement au besoin. En dernier lieu, les renseignements sont approuvés selon le protocole suivant, avant d’être divulgués dans les délais prévus :
Contrats d’une valeur de plus de 10 000 $ :
Le Comité d’examen des contrats, qui est l’organe de gouvernance de l’approvisionnement et qui se compose de plusieurs directeurs généraux et directrices générales de l’organisme, approuve la publication des contrats.
Frais de voyage et d’accueil :
Le bureau de chaque statisticien en chef adjoint et statisticienne en chef adjointe confirme l’exactitude des publications proactives pour chaque mois concerné, avant l’approbation finale de la liste complète des publications par le dirigeant principal ou la dirigeante principale des finances (DPF).
Subventions et contributions d’une valeur de plus de 25 000 $ :
Les conseillers et conseillères en gestion financière confirment l’existence de subventions et de contributions.
Le DPF examine et approuve le rapport final de publication proactive.
En cas d’absence de réponse, la plus haute instance à laquelle il revient d’approuver le rapport de publication proactive est le directeur ou la directrice de la Division des opérations financières de la DFPA.
Le personnel est invité à consulter les diverses lignes directrices du Conseil du Trésor concernant les rapports : le Guide de publication proactive des frais de voyage et d’accueil pour ce qui concerne les frais de déplacement et d’accueil, les Lignes directrices sur la divulgation des octrois de subventions et de contributions pour ce qui concerne les subventions et les contributions d’une valeur de plus de 25 000 $ et le Guide de la publication proactive des marchés pour ce qui concerne les contrats d’une valeur de plus de 10 000 $.
Le personnel reçoit aussi une formation sur le Registre du gouvernement ouvert et se voit accorder l’accès à celui-ci pour être en mesure de publier les renseignements requis selon le calendrier de publication. En outre, les pratiques exemplaires sont régulièrement abordées au cours des réunions d’équipe.
La Direction veille à ce que les publications proactives soient accessibles sur le site Web public, et chaque chef d’équipe valide les publications une fois qu’elles sont publiées en ligne pour s’assurer qu’elles sont une transcription exacte des renseignements fournis.
Au cours de la période de déclaration 2024-2025, la DFPA a satisfait aux exigences de publication à un taux de conformité de 100 %.
Direction des stratégies et de la gestion intégrées : Division de la conception organisationnelle et du ressourcement
Direction des stratégies et de la gestion intégrées : Division de la conception organisationnelle et du ressourcement
L’Équipe de classification du Bureau de la conception organisationnelle et du ressourcement est chargée de veiller à ce que l’exigence de publication pour la reclassification des postes soit respectée et publiée à temps. La Sous-section de l’administration – Classification accélérée est responsable de la publication trimestrielle des renseignements sur le site du gouvernement ouvert.
Au cours de la période de référence 2024-2025, l’Équipe de classification a satisfait aux exigences de publication à un taux de conformité de 100 %.
Bureau du statisticien en chef
Bureau du statisticien en chef
Exigences législatives
Article
Délai de publication
Taux de conformité
Publication proactive (lien Web)
Trousses d’information à l’intention des nouveaux ou futurs administrateurs généraux et administratrices générales ou des personnes occupant un poste de niveau équivalent
88(a)
Dans les 120 jours suivant la nomination
S.O.
S.O. pendant la période de déclaration
Titres et numéros de référence des notes préparées à l’intention d’un administrateur général ou d’une administratrice générale ou d’une personne occupant un poste de niveau équivalent et reçues au bureau de cet administrateur ou de cette personne
88(b)
Dans les 30 jours suivant la fin du mois de réception
Trousses d’information à l’intention d’un administrateur général ou d’une administratrice générale ou d’une personne occupant un poste de niveau équivalent pour les comparutions devant un comité parlementaire
Bureau du statisticien en chef - Note de bas de tableau 1
Le statisticien en chef actuel n’a comparu devant aucun comité parlementaire au cours de la période de déclaration. Toutefois, le statisticien en chef précédent a comparu devant un comité du Sénat en février 2024 et le dossier a été communiqué au cours de la période de déclaration, à savoir en juin 2024.
Le Bureau du statisticien en chef (BSC) assure la publication des titres et des numéros de référence des mémoires préparés pour le statisticien en chef et une trousse d’information préparée pour la comparution du statisticien en chef devant un comité parlementaire, ainsi que pour le nouveau ou le futur statisticien en chef.
Au cours de l’exercice 2024-2025, aucune trousse d’information n’a été préparée pour le nouveau statisticien en chef.
Au cours de l’exercice 2024-2025, le BSC a atteint un niveau de conformité de 100 % pour ce qui est des exigences de publication proactive concernant les titres et les numéros de référence des notes préparées à l’intention du statisticien en chef, ainsi que des documents d’information liés aux comparutions devant les comités parlementaires.
Tout au long de la période de déclaration, le BSC a collaboré avec tous les secteurs de Statistique Canada pour examiner et publier les renseignements pertinents conformément aux exigences législatives.
Coûts
Le coût total de fonctionnement du programme d’accès à l’information pour la période de déclaration 2024-2025 s’est chiffré à 170 073,00 $.
Contrôle de la conformité
À Statistique Canada, le Bureau de l’AIPRP traite les demandes et en fait le suivi en les enregistrant dans un système complet appelé Privasoft – Access Pro Case Management. Un accusé de réception de la demande et des frais de 5,00 $ est envoyé au client et un formulaire de recherche est transmis au secteur de programme concerné (bureau de première responsabilité [BPR]). Si le BPR ou le Bureau de l’AIPRP doivent obtenir des précisions sur la demande, seul le Bureau de l’AIPRP communique avec le client, à moins que le client n’ait donné son consentement au préalable. Les noms des clients restent toujours confidentiels.
Le formulaire de recherche fourni au BPR a été créé par le Bureau de l’AIPRP à Statistique Canada dans l’esprit de la Politique sur l’accès à l’information et de la Directive concernant l’administration de la Loi sur l’accès à l’information du Secrétariat du Conseil du Trésor du Canada. Sur le formulaire figurent le texte de la demande, le nom et le numéro de téléphone de l’agent ou l’agente de l’AIPRP et la date à laquelle les documents doivent être fournis (normalement un délai de 5 à 10 jours). Le formulaire comprend une liste de vérification, que les BPR remplissent pour confirmer qu’ils ont effectué une recherche approfondie ainsi qu’un calendrier de recommandations pour déterminer les renseignements sensibles et la nature particulière du préjudice qui pourrait être causé par la diffusion. Les personnes qui fournissent les documents doivent signaler tous ceux qui pourraient être de nature délicate (p. ex., questions juridiques, renseignements confidentiels du Cabinet, renseignements personnels, renseignements sur des entreprises, conseils au ou à la ministre), qui pourraient nécessiter des consultations ou qui pourraient susciter l’intérêt des médias. Le directeur général ou la directrice générale (ou la personne déléguée compétente) du secteur de programme doit signer le formulaire.
Le Bureau de l’AIPRP aide les secteurs de programme avec les procédures administratives liées à la récupération des dossiers. Une fois les documents reçus du BPR, le Bureau de l’AIPRP s’assure qu’un formulaire de récupération est dûment rempli par le directeur ou la directrice du programme. On rappelle au BPR et aux directeurs et directrices de programme l’importance de répondre aux demandes d’AIPRP de manière opportune et exhaustive. Un rapport hebdomadaire est présenté à la haute direction dans un tableau de bord, à des fins d’information, et afin de faire le suivi des nouvelles demandes, des demandes fermées et des demandes en cours et de régler tout problème émergent.
Annexe A : Ordonnance de délégation
Arrêté sur la délégation en vertu des Lois sur l'accès à l'information et la protection des renseignements personnels
En vertu de l'article 73 de la Loi sur l'accès à l'information et de l'article 73 de la Loi sur la protection des renseignements personnels, le Ministre de l'Innovation, des Sciences et de l'Industrie délègue aux titulaires des postes mentionnés à l'annexe ci-après, ainsi qu'aux personnes occupant à titre intérimaire les-dits postes, les attributions dont il est, en qualité de responsable de Statistique Canada, investi par les articles des Lois mentionnées en regard de chaque poste. Le présent décret de délégation remplace et annule tout décret antérieur.
Annexe
Poste
Loi sur l'acces à l'information et règlements
Loi sur la protection des renseignements personnels et règlements
Statisticien en chef du Canada
Autorité absolue
Autorité absolue
Chef de cabinet, Bureau du Statisticien en chef
Autorité absolue
Autorité absolue
Directeur(trice), Bureau de gestion de la protection de la vie privée et de coordination de l'information
Autorité absolue
Autorité absolue
Directeur(trice) Adjoint(e) Bureau de gestion de la protection de la vie privée et de coordination de l'information
Autorité absolue
Autorité absolue
Gestionnaire principal(e) de projet, Accés à l'information et la protection des renseignements personnels
La version originale a été signée par
L'honorable Françoeis-Philippe Champagne
Ministre de l'innovation, des sciences et de l'industrie
Daté, en la ville d'Ottawa
Le 18 mai 2021
Annexe B : Rapport statistique sur la Loi sur l’accès à l’information
Nom de l'institution: Statistique Canada
Période d'établissement de rapport : 2024-04-01 à 2025-03-31
Section 1 – Demandes en vertu de la Loi sur l'accès à l'information
1.1 Nombre de demandes
Nombre de demandes
Nombre de demandes
Reçues pendant la période d'établissement de rapport
63
En suspens à la fin de la période d'établissement de rapport précédente
0
En suspens à la fin de la période d'établissement de rapport précédente
0
En suspens pour plus d'une période d'établissement de rapport
0
Total
63
Fermées pendant la période d'établissement de rapport
55
Reportées à la prochaine période d'établissement de rapport
8
Reportées à la prochaine période d'établissement de rapport dans les délais prévus par la Loi
5
Reportées à la prochaine période d'établissement de rapport au-delà des délais prévus par la Loi
3
1.2 Source des demandes
Source des demandes
Source
Nombre de demandes
Médias
18
Secteur universitaire
4
Secteur commercial (secteur privé)
11
Organisation
4
Public
26
Refus de s'identifier
0
Total
63
1.3 Mode des demandes
Mode des demandes
Mode
Nombre des demandes
En ligne
55
Courriel
6
Poste
2
En personne
0
Téléphone
0
Télécopieur
0
Total
63
Section 2 – Demandes informelles
2.1 Nombre de demandes informelles
Nombre de demandes informelles
Nombre de demandes
Reçues pendant la période d'établissement de rapport
126
En suspens à la fin de la période d'établissement de rapport précédente
0
En suspens à la fin de la période d'établissement de rapport précédente
0
En suspens pour plus d'une période d'établissement de rapport
0
Total
126
Fermées pendant la période d'établissement de rapport
43
Reportées à la prochaine période d'établissement de rapport
83
2.2 Mode des demandes informelles
Mode des demandes informelles
Mode
Nombre des demandes
En ligne
124
Courriel
2
Poste
0
En personne
0
Téléphone
0
Télécopieur
0
Total
126
2.3 Délai de traitement pour les demandes informelles
Délai de traitement pour les demandes informelles
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
3
0
2
0
22
16
0
43
2.4 Pages communiquées informellement
Pages communiquées informellement
Moins de 100 pages communiquées
De 100 à 500 pages communiquées
De 501 à 1 000 pages communiquées
De 1 001 à 5 000 pages communiquées
Plus de 5 000 pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages recommuniquées
Nombre de demandes
Pages communiquées
1
3
1
105
0
0
1
2221
0
0
2.5 Pages recommuniquées informellement
Pages recommuniquées informellement
Moins de 100 pages recommuniquées
De 100 à 500 pages recommuniquées
De 501 à 1 000 pages recommuniquées
De 1 001 à 5 000 pages recommuniquées
Plus de 5 000 pages recommuniquées
Nombre de demandes
Pages recommuniquées
Nombre de demandes
Pages recommuniquées
Nombre de demandes
Pages recommuniquées
Nombre de demandes
Pages recommuniquées
Nombre de demandes
Pages recommuniquées
21
453
11
2498
2
1261
5
7501
1
5165
Section 3 – Demandes à la Commissaire à l'information pour ne pas donner suite à la demande
Demandes à la Commissaire à l'information pour ne pas donner suite à la demande
Nombre de demandes
En suspens depuis la période d'établissement de rapports précédente
0
Envoyées pendant la période d'établissement de rapports
0
Total
0
Approuvées par la Commissaire à l'information pendant la période d'établissement de rapports
0
Refusées par la Commissaire à l'information au cours de la période d'établissement de rapports
0
Retirées pendant la période d'établissement de rapports
0
Reportées à la prochaine période d'établissement de rapports
0
Section 4 – Demandes fermées pendant la période d'établissement de rapports
4.1 Disposition et délai de traitement
Disposition et délai de traitement
Disposition des demandes
Délai de traitement
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
Communication totale
0
12
6
1
0
0
0
19
Communication partielle
0
5
3
4
0
0
0
12
Exception totale
0
1
1
0
0
0
0
2
Exclusion totale
0
0
1
0
0
0
0
1
Aucun document n'existe
14
5
0
0
0
0
0
19
Demande transférée
0
0
0
0
0
0
0
0
Demande abandonnée
2
0
0
0
0
0
0
2
Ni confirmée ni infirmée
0
0
0
0
0
0
0
0
Refus d'agir avec l'approbation de la Commissaire à l'information
4.5.1 Pages pertinentes traitées et communiquées en formats papier, document électronique et ensemble de données
Pages pertinentes traitées et communiquées en formats papier, document électronique et ensemble de données
Nombre de pages traitées
Nombre de pages communiquées
Nombre de demandes
7387
6341
36
4.5.2 Pages pertinentes traitées et communiquées en fonction de l’ampleur des demandes en formats papier, document électronique et ensemble de données par disposition des demandes
Pages pertinentes traitées et communiquées en fonction de l’ampleur des demandes en formats papier, document électronique et ensemble de données par disposition des demandes
Disposition
Moins de 100 pages traitées
100 à 500 pages traitées
501 à 1 000 pages traitées
1 001 à 5 000 pages traitées
Plus de 5 000 pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Communication totale
18
210
0
0
0
0
1
4410
0
0
Communication partielle
5
99
6
1877
1
627
0
0
0
0
Exception totale
1
18
1
135
0
0
0
0
0
0
Exclusion totale
1
11
0
0
0
0
0
0
0
0
Demande abandonnée
2
0
0
0
0
0
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
0
0
0
0
0
0
Refus d'agir avec l'approbation de la Commissaire à l'information
0
0
0
0
0
0
0
0
0
0
Total
27
338
7
2012
1
627
1
4410
0
0
4.5.3 Minutes pertinentes traitées et communiquées en format audio
Minutes pertinentes traitées et communiquées en format audio
Nombre de minutes traitées
Nombre de minutes communiquées
Nombre de demandes
0
0
0
4.5.4 Minutes pertinentes traitées en fonction de l'ampleur des demandes en format audio par disposition des demandes
Minutes pertinentes traitées en fonction de l'ampleur des demandes en format audio par disposition des demandes
Disposition
Moins de 60 minutes traitées
60-120 minutes traitées
Plus de 120 minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Communication totale
0
0
0
0
0
0
Communication partielle
0
0
0
0
0
0
Exception totale
0
0
0
0
0
0
Exclusion totale
0
0
0
0
0
0
Demande abandonnée
0
0
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
0
0
Refus d'agir avec l'approbation de la Commissaire à l'information
0
0
0
0
0
0
Total
0
0
0
0
0
0
4.5.5 Minutes pertinentes traitées et communiquées en format vidéo
Minutes pertinentes traitées et communiquées en format vidéo
Nombre de minutes traitées
Nombre de minutes communiquées
Nombre de demandes
0
0
0
4.5.6 Minutes pertinentes traitées en fonction de l'ampleur des demandes en format vidéo par disposition des demandes
Minutes pertinentes traitées en fonction de l'ampleur des demandes en format vidéo par disposition des demandes
Disposition
Moins de 60 minutes traitées
60-120 minutes traitées
Plus de 120 minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Communication totale
0
0
0
0
0
0
Communication partielle
0
0
0
0
0
0
Exception totale
0
0
0
0
0
0
Exclusion totale
0
0
0
0
0
0
Demande abandonnée
0
0
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
0
0
Refus d'agir avec l'approbation de la Commissaire à l'information
0
0
0
0
0
0
Total
0
0
0
0
0
0
4.5.7 Autres complexités
Autres complexités
Disposition
Consultation requise
Avis juridique
Autres
Total
Communication totale
3
0
0
3
Communication partielle
6
1
0
7
Exception totale
0
1
0
1
Exclusion totale
0
1
0
1
Demande abandonnée
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
Refus d'agir avec l'approbation de la Commissaire à l'information
0
0
0
0
Total
9
3
0
12
4.6 Demandes fermées
4.6.1 Nombre de demandes fermées dans les délais prévus par la Loi
Nombre de demandes fermées dans les délais prévus par la Loi
Nombre de demandes fermées dans les délais prévus par la Loi
47
Pourcentage des demandes fermées dans les délais prévus par la Loi (%)
85.45454545
4.7 Présomptions de refus
4.7.1 Motifs du non-respect des délais prévus par la Loi
Motifs du non-respect des délais prévus par la Loi
Nombre de demandes fermées au-delà des délais prévus par la Loi
Motif principal
Entrave au fonctionnement / Charge de travail
Consultation externe
Consultation interne
Autre
8
0
0
0
8
4.7.2 Demandes fermées au-dela des délais prévus par la Loi (y compris toute prorogation prise)
Demandes fermées au-dela des délais prévus par la Loi
Nombre de jours de retard au-delà des délais prévus par la Loi
Nombre de demandes fermées au-delà des délais prévus par la Loi où aucune prorogation n'a été prise
Nombre de demandes fermées au-delà des délais prévus par la Loi où une prorogation a été prise
Total
1 à 15 jours
4
2
6
16 à 30 jours
1
0
1
31 à 60 jours
1
0
1
61 à 120 jours
0
0
0
121 à 180 jours
0
0
0
181 à 365 jours
0
0
0
Plus de 365 jours
0
0
0
Total
6
2
8
4.8 Demandes de traduction
Demandes de traduction
Demandes de traduction
Acceptées
Refusées
Total
De l'anglais au français
0
0
0
Du français à l'anglais
0
0
0
Total
0
0
0
Section 5 – Prorogations
5.1 Motifs des prorogations et disposition des demandes
Motifs des prorogations et disposition des demandes
Disposition des demandes où le délai a été prorogé
9(1)(a) Entrave au fonctionnement
9(1)(b) Consultation
9(1)(c) Avis à un tiers
Article 69
Autres
Communication totale
1
0
3
0
Communication partielle
0
0
5
1
Exception totale
0
0
1
0
Exclusion totale
0
0
1
0
Demande abandonnée
0
0
0
0
Aucun document n'existe
0
0
0
0
Refus d'agir avec l'approbation de la Commissaire à l'information
0
0
0
0
Total
1
0
10
1
5.2 Durée des prorogations
Durée des prorogations
Durée des prorogations
9(1)(a) Entrave au fonctionnement
9(1)(b) Consultation
9(1)(c) Avis à un tiers
Article 69
Other
30 jours ou moins
1
0
7
0
31 à 60 jours
0
0
1
0
61 à 120 jours
0
0
2
1
121 à 180 jours
0
0
0
0
181 à 365 jours
0
0
0
0
Plus de 365 jours
0
0
0
0
Total
1
0
10
1
Section 6 – Frais
Frais
Type de frais
Frais perçus
Frais dispensés
Frais remboursés
Nombre de demandes
Montant
Nombre de demandes
Montant
Nombre de demandes
Montant
Présentation
53
265,00 $
0
0,00 $
2
10,00 $
Autres frais
0
0,00 $
0
0,00 $
0
0,00 $
Total
53
265,00 $
0
0,00 $
2
10,00 $
Section 7 – Demandes de consultation reçues d'autres institutions et organisations
7.1 Demandes de consultation reçues d’autres institutions du gouvernement du Canada et autres organisations
Demandes de consultation reçues d’autres institutions du gouvernement du Canada et autres organisations
Consultations
Autres institutions du gouvernement du Canada
Nombre de pages à traiter
Autres organisations
Nombre de pages à traiter
Reçues pendant la période d'établissement de rapport
29
893
1
3
En suspens à la fin de la période d'établissement de rapport précédente
1
196
0
0
Total
30
1089
1
3
Fermées pendant la période d'établissement de rapport
24
792
1
3
Reportées à l'intérieur des délais négociés à la prochaine période d'établissement de rapport
1
196
0
0
Reportées au-delà des délais négociés à la prochaine période d'établissement de rapport
5
101
0
0
7.2 Recommandation et délai de traitement pour les demandes de consultation reçues d’autres institutions du gouvernement du Canada
Recommandation et délai de traitement pour les demandes de consultation reçues d’autres institutions du gouvernement du Canada
Recommandation
Nombre de jours requis pour traiter les demandes de consultation
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
Communiquer en entier
11
7
3
0
0
0
0
21
Communiquer en partie
1
0
1
0
0
0
0
2
Exempter en entier
0
0
0
0
0
0
0
0
Exclure en entier
0
1
0
0
0
0
0
1
Consulter une autre institution
0
0
0
0
0
0
0
0
Autre
0
0
0
0
0
0
0
0
Total
12
8
4
0
0
0
0
24
7.3 Recommandation et délai de traitement pour les demandes de consultation reçues d’autres organisations à l'extérieur du gouvernement du Canada
Recommandation et délai de traitement pour les demandes de consultation reçues d’autres organisations à l'extérieur du gouvernement du Canada
Recommandation
Nombre de jours requis pour traiter les demandes de consultation
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
Communiquer en entier
1
0
0
0
0
0
0
1
Communiquer en partie
0
0
0
0
0
0
0
0
Exempter en entier
0
0
0
0
0
0
0
0
Exclure en entier
0
0
0
0
0
0
0
0
Consulter une autre institution
0
0
0
0
0
0
0
0
Autre
0
0
0
0
0
0
0
0
Total
1
0
0
0
0
0
0
1
Section 8 – Délais de traitement des demandes de consultation sur les renseignements confidentiels du Cabinet
8.1 Demandes auprès des services juridiques
Demandes auprès des services juridiques
Nombre de jours
Moins de 100 pages traitées
De 100 à 500 pages traitées
De 501 à 1 000 pages traitées
De 1 001 à 5 000 pages traitées
Plus de 5 000 pages traitées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
1 à 15
0
0
0
0
0
0
0
0
0
0
16 à 30
0
0
0
0
0
0
0
0
0
0
31 à 60
2
18
1
135
0
0
0
0
0
0
61 à 120
0
0
0
0
0
0
0
0
0
0
121 à 180
0
0
0
0
0
0
0
0
0
0
181 à 365
0
0
0
0
0
0
0
0
0
0
Plus de 365
0
0
0
0
0
0
0
0
0
0
Total
2
18
1
135
0
0
0
0
0
0
8.2 Demandes auprès du Bureau du Conseil privé
Demandes auprès du Bureau du Conseil privé
Nombre de jours
Moins de 100 pages traitées
De 100 à 500 pages traitées
De 501 à 1 000 pages traitées
De 1 001 à 5 000 pages traitées
Plus de 5 000 pages traitées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
1 à 15
0
0
0
0
0
0
0
0
0
0
16 à 30
0
0
0
0
0
0
0
0
0
0
31 à 60
0
0
0
0
0
0
0
0
0
0
61 à 120
0
0
0
0
0
0
0
0
0
0
121 à 180
0
0
0
0
0
0
0
0
0
0
181 à 365
0
0
0
0
0
0
0
0
0
0
Plus de 365
0
0
0
0
0
0
0
0
0
0
Total
0
0
0
0
0
0
0
0
0
0
Section 9 – Enquêtes et compte rendus de conclusion
9.1 Enquêtes
Enquêtes
Article 32 Avis d'enquête
Article 30(5) Cessation de l'enquête
Article 35 Présenter des observations
0
0
0
9.2 Enquêtes et rapports des conclusions
Enquêtes et rapports des conclusions
Article 37(1) Comptes rendus initiaux
Article 37(2) Comptes rendus finaux
Reçus
Contenant des recommandations émis par la Commissaire à l'information
Contenant une intention d'émettre une ordonnance par la Commissaire à l'information
Reçus
Contenant des recommandations émis par la Commissaire à l'information
Contenant des ordonnances émis par la Commissaire à l’information
0
0
0
0
0
0
Section 10 – Recours judiciaire
10.1 Recours judiciaires sur les plaintes
Recours judiciaires sur les plaintes
Article 41
Plaignant (1)
Institution (2)
Tier (3)
Commissaire à la protection de la vie privée (4)
Total
0
0
0
0
0
10.2 Recours judiciaires sur les plaintes de tiers en vertu de l'alinéa 28(1)b)
Recours judiciaires sur les plaintes de tiers en vertu de l'alinéa 28(1)b)
Article 44 - en vertu de l'alinéa 28(1)b)
0
Section 11 – Ressources liées à la Loi sur l'accès à l'information
La Loi sur la protection des renseignements personnels permet aux citoyens canadiens et aux personnes vivant au Canada d’avoir accès aux renseignements personnels qui les concernent et qui sont détenus par des institutions fédérales. La Loi les protège également contre la divulgation non autorisée de ces renseignements personnels et impose des mesures de contrôle rigoureuses sur la collecte, l’utilisation, l’entreposage, la divulgation et l’élimination de tout renseignement personnel par le gouvernement.
Le Rapport annuel sur l’administration de la Loi sur la protection des renseignements personnels est préparé et soumis conformément à l’article 72 de la Loi et couvre la période allant du 1er avril 2024 au 31 mars 2025. Le rapport est déposé au Parlement.
Mandat de Statistique Canada
Le mandat de Statistique Canada consiste à produire des données qui aident les Canadiens à mieux comprendre la population, les ressources, l’économie, l’environnement, la société et la culture de leur pays. L’organisme est tenu de s’acquitter de cette tâche pour le Canada ainsi que pour chacune des provinces et chacun des territoires. L’organisme doit aussi effectuer le Recensement de la population et le Recensement de l’agriculture tous les cinq ans, afin de brosser un portrait détaillé de la société canadienne.
Filiales non opérationnelles
Statistique Canada n’avait pas de filiales non opérationnelles durant la période de déclaration.
Administration de la Loi sur la protection des renseignements personnels
En vertu de la Loi sur la protection des renseignements personnels, les institutions fédérales ne peuvent recueillir des renseignements personnels que lorsqu’ils se rapportent directement à leurs programmes ou à leurs activités. Pour Statistique Canada, ce pouvoir est conféré par la Loi sur la statistique, qui prescrit la collecte de renseignements personnels à des fins statistiques. Les deux lois imposent des obligations strictes afin de protéger ces renseignements, ce qui inclut les protéger contre la divulgation non autorisée.
À Statistique Canada, le directeur du Bureau de gestion de la protection de la vie privée et de coordination de l’information exerce les fonctions de coordonnateur de l’accès à l’information et de la protection des renseignements personnels (AIPRP) ainsi que de dirigeant principal de la protection des renseignements personnels. Ce rôle consiste à superviser l’administration de la Loi sur l’accès à l’information et de la Loi sur la protection des renseignements personnels, à garantir le respect des exigences législatives et la protection des renseignements personnels dans l’ensemble de l’organisme.
Structure organisationnelle de Statistique Canada
Statistique Canada est assujetti à la Loi sur la statistique, qui donne à l’organisme mandat de recueillir, compiler, analyser et publier des renseignements statistiques sur les conditions économiques, sociales et générales du Canada. La Loi charge également l’organisme de coordonner le système statistique national afin de minimiser les chevauchements au sein du gouvernement. Pour remplir ce rôle, le statisticien en chef peut conclure des ententes de partage de données avec des partenaires fédéraux, provinciaux et territoriaux.
La Loi sur la statistique prévoit expressément que Statistique Canada effectue un recensement de la population et un recensement de l’agriculture tous les cinq ans, comme cela a été fait en 2021. La Loi habilite également l’organisme à recueillir des renseignements au moyen d’enquêtes auprès des ménages et des entreprises. Le statisticien en chef détermine si une enquête est obligatoire ou volontaire. Bien que le Recensement de la population et l’Enquête sur la population active soient obligatoires en raison de leur importance nationale, la plupart des autres enquêtes auprès des ménages sont volontaires. Les enquêtes auprès des entreprises et le Recensement de l’agriculture sont généralement obligatoires, avec des sanctions juridiques en cas de non-conformité.
En plus des données d’enquête, Statistique Canada est autorisé à accéder aux dossiers administratifs, comme les données fiscales, les déclarations douanières et les statistiques de l’état civil, qui sont essentiels pour réduire le fardeau de réponse et améliorer la qualité des données. L’organisme est reconnu à l’échelle internationale pour son leadership dans l’utilisation des données administratives afin de minimiser les exigences en matière de déclaration.
Afin de maintenir la vie privée et la confiance du public, Statistique Canada a mis en oeuvre un Cadre de nécessité et de proportionnalité. Ce cadre garantit que la collecte de données est justifiée, proportionnée à sa sensibilité et transparente. Il comprend des évaluations rigoureuses de la nécessité, de l’éthique et du risque, et exige des évaluations des répercussions sur la vie privée et des communications publiques tout au long du processus d’acquisition de données.
L’organisme suit également une approche responsable de protection de la vie privée, renforçant son engagement à protéger les renseignements personnels tout en fournissant aux Canadiens les données dont ils ont besoin pour prendre des décisions éclairées dans un monde en évolution rapide.
Le Bureau de l’accès à l’information et de la protection des renseignements personnels (AIPRP) de Statistique Canada est composé d’un gestionnaire de l’AIPRP, d’un analyste de l’AIPRP et d’un analyste subalterne, en vertu d’une affectation de 2,13 ETP. L’arriéré ayant été éliminé avant le début de l’exercice et la charge de travail s’étant stabilisée, aucun nouvel employé n’a été embauché et aucun consultant n’a été engagé pendant la période de déclaration.
Enfin, Statistique Canada n’a signé aucune entente en vertu de l’article 73.1 de la Loi sur la protection des renseignements personnels au pendant la période de déclaration.
Ordonnance de délégation de pouvoir
Conformément à l’article 73 de la Loi sur la protection des renseignements personnels, les pouvoirs et les responsabilités du ministre à titre de chef de l’institution ont été officiellement délégués. Depuis le 18 mai 2021, le ministre de l’Innovation, des Sciences et du Développement économique (ISDE) a délégué les pleins pouvoirs prévus par la Loi au directeur et au directeur adjoint du Bureau de la gestion de la vie privée et de la coordination de l’information, comme indiqué dans l’ordonnance de délégation (annexe A).
Rendement de 2024-2025
Rapport statistique
En 2024-2025, Statistique Canada a reçu 40 nouvelles demandes de renseignements personnels et en a reporté une de l’année précédente. De ce nombre, 34 ont été terminés et 7 seront toujours actives au début de la prochaine période de déclaration.
Demandes de protection de la vie privée
Décisions rendues au regard des demandes traitées
Décisions rendues au regard de demande
Nombre de demandes
Communication totale
8
Communication partielle
17
Aucune communication (exemption)
0
N’existe pas
3
Demande abandonnée
4
Ni confirmée ni infirmée
2
Total
34
Des renseignements ont été complètement divulgués dans 8 cas et partiellement divulgués dans 17 cas, et des mesures correctives ont été prises pour protéger les renseignements personnels de tiers. Aucune demande n’a été exemptée ou exclue. Dans 3 cas, les renseignements demandés n’existaient pas et 4 demandes ont été abandonnées en raison du retrait du demandeur ou de l’absence de réponse.
Le public demeure la principale source de demandes de renseignements personnels à Statistique Canada. De plus, l’organisme reçoit des demandes d’employés fédéraux actuels et anciens relativement à des questions personnelles ou de dotation. Un nombre important de demandes sont également traitées dans le cadre du programme des recherches aux fins des pensions, qui permet aux particuliers d’accéder à leurs propres dossiers du recensement ou des Registres nationaux de 1940. Ces dossiers appuient les demandes de pensions, de citoyenneté, de passeports et d’autres services lorsque la documentation standard n’est pas disponible. Les représentants autorisés peuvent également demander des renseignements pour le compte de mineurs, d’adultes à charge ou de personnes décédées à des fins d’administration de la succession, comme le permet le règlement.
Aucune demande d’accès à des questionnaires individuels du Recensement de la population de 2021 n’a été reçue en 2024-2025.
Au total, plus de 3 648 pages ont été examinées, dont 2 533 ont été diffusées. Vingt-trois demandeurs ont reçu leurs renseignements par voie électronique, tandis que deux ont opté pour le format papier.
Le tableau ci-dessous illustre la plus récente tendance pour les cinq dernières années en ce qui concerne le traitement des demandes de renseignements personnels reçues par l’organisme.
Traitement des demandes de renseignements personnels selon l'exercice financier
Exercice financier
Demandes reçues
Demandes traitées
Nombre de pages traitées
Nombre de pages communiquées
2024-2025
40
34
3 648
2 533
2023-2024
52
54
20 817
7 669
2022-2023
48
178
34 685
10 451
2021-2022
161
65
1 744
1 416
2020-2021
86
138
4 076
2 983
Autres demandes
Au cours de la période visée, Statistique Canada n’a reçu aucune demande de consultation soumise par d’autres ministères et organismes gouvernementaux en vertu de la Loi sur la protection des renseignements personnels.
Décisions rendues au regard des demandes traitées
Les résultats des 34 demandes traitées en 2024-2025 étaient les suivants :
Huit (8) demandes ont fait l’objet d’une divulgation complète (23,5 %)
17 demandes ont fait l’objet d’une divulgation partielle (50 %)
Aucune demande n’a été exemptée ou exclue (0 %)
Pour trois (3) demandes, les dossiers n’existaient pas (8,8 %)
Quatre (4) demandes ont été abandonnées par les demandeurs (11,8 %)
Deux (2) demandes n’ont été ni confirmées ni non confirmées (5,9 %)
Décisions rendues au regard des demandes traitées
Demandes de confidentialité (exercice)
2024-25
Demandes reçues
40
Demandes traitées
34
Pourcentages de demandes traitées
85 %
Demandes traitées à temps
27
Pourcentage de demandes traitées à temps
79.41 %
Délais de traitement et prorogations
Sur les 34 demandes reçues et traitées durant l’exercice de 2024-2025, 27 demandes ont été traitées dans les délais prescrits par la Loi sur la protection des renseignements personnels et une (1) demande a été reportée au prochain exercice. Plusieurs facteurs ont contribué au respect des délais, y compris la tenue de séances de formation avec des cadres supérieurs et des agents de liaison, ainsi que la réduction de l’arriéré des demandes, qui a permis aux analystes de se concentrer sur les nouvelles demandes reçues au cours de cette période. Des prolongations ont été accordées pour 3 demandes.
En 2024-2025, 34 demandes ont été traitées dans les délais suivants :
Sept (7) ont été traitées dans un délai de 1 à 15 jours (20,6 %)
17 ont été traitées dans un délai de 16 à 30 jours (50 %)
Neuf (9) ont été traitées dans un délai de 31 à 60 jours (26,5 %)
Une (1) a été traitée dans un délai de 61 à 120 jours (2,9 %)
Plaintes et enquêtes
Aucune nouvelle plainte n’a été déposée contre Statistique Canada auprès du Commissariat à la protection de la vie privée (CPVP). Deux (2) plaintes qui ont été déposées en 2023 demeurent non résolues et ont été reportées au prochain exercice.
Le rapport statistique fournit des données agrégées sur l’application de la Loi sur la protection des renseignements personnels. Ces renseignements sont rendus publics chaque année et sont inclus dans le rapport annuel (annexe B).
Intégrer la protection des renseignements personnels aux opérations
La Loi sur la protection des renseignements personnels joue un rôle fondamental en guidant l’approche de Statistique Canada en matière de gestion des renseignements personnels. Son influence va au-delà du traitement des demandes d’accès, façonnant la façon dont l’organisme recueille, utilise et protège les données en réponse aux attentes croissantes du public en matière de transparence et de responsabilisation.
Statistique Canada jouit d’une réputation bien établie en matière de protection de la vie privée des Canadiens et continue de mettre en oeuvre une gamme d’initiatives pour répondre aux préoccupations changeantes. Les directives internes sont conformes aux principes fondamentaux de la Loi sur la protection des renseignements personnels et sont intégrées dans les opérations quotidiennes :
La directive d’information des répondants aux enquêtes assure que les personnes sont clairement informées de l’objet de la collecte de données, de l’autorité juridique en vertu de laquelle elle est effectuée, des protections en matière de confidentialité prévues par la Loi sur la statistique, et de tout accord d’échange de données applicable.
La directive sur le couplage de microdonnées régit l’intégration responsable des données à caractère personnel provenant de sources multiples, en équilibrant la nécessité d’une analyse statistique de haute qualité avec de solides garanties en matière de confidentialité.
Ces directives renforcent la conformité de l’organisme à la Loi sur la protection des renseignements personnels et reflètent son engagement continu à l’égard de l’intendance responsable des renseignements personnels.
Afin d’appuyer davantage la prise de décisions soucieuses de la protection des renseignements personnels, Statistique Canada applique un cadre de nécessité et de proportionnalité, en s’assurant que toute collecte de renseignements personnels à des fins statistiques est manifestement justifiée et proportionnée à son utilisation prévue.
À mesure que les méthodes de collecte de données évoluent, la protection de la vie privée demeure au coeur des activités de l’organisme. Le Centre de confiance sert de plateforme publique qui démontre comment Statistique Canada répond aux besoins des Canadiens en matière de renseignements tout en protégeant leurs données.
Le mandat de l’organisme, qui consiste à fournir des renseignements de haute qualité sur la population, l’économie, l’environnement et la société du Canada, exige la collecte de renseignements personnels, soit directement au moyen d’enquêtes, soit indirectement à partir de sources administratives. Avec cette autorité vient la responsabilité de maintenir la confidentialité de ces renseignements, comme l’exigent la loi et les principes.
Afin de maintenir la confiance du public, Statistique Canada adapte continuellement ses pratiques aux réalités émergentes et perfectionne les mécanismes pour prévenir l’utilisation abusive de données personnelles. Cela comprend un engagement à l’égard d’une protection responsable de la vie privée — une approche proactive qui va au-delà de la conformité en intégrant les considérations de protection de la vie privée dans tous les aspects du travail de l’organisme et en adoptant des mesures de protection novatrices.
Pour appuyer ces efforts, la haute direction continue de mettre en oeuvre et de maintenir un Programme de gestion de la protection des renseignements personnels (PGPRP) officiel. Le PGPRP s’assure que l’organisme demeure bien équipé pour gérer les renseignements personnels de façon responsable, tout en respectant la transparence, la responsabilisation et le respect des lois et des instruments de politique sur la protection de la vie privée applicables.
Description - Cadre de gestion des renseignements personnels
Cadre de gestion des renseignements personnels de Statistique Canada
Surveillance et examen
Évaluer et réviser des contrôles du programme sont nécessaires
Contrôles du programme
Répertoire de données personnelles
Accès facile pour les Canadiens à leurs renseignements personnels
Directives, politiques et procédures
Rationalisation de la gouvernance aux fins d'harmonisation avec les principes de protection responsable de la vie privée
Évaluations des risques et autres outils de soutien
Modernisation de la boîte à outils pour la protection de la vie privée et simplification des EFVP
Formation, éducation et sensibilisation
Éducation des Canadiens sur la protection de la vie privée dans le contexte statistique
Protocoles en cas d'incident et d'atteinte à la protection de la vie privée
Trousse d'autoassistance et ressources simplifiées pour le personnel et surveillance active
Gestion des clients, des associés et des fournisseurs de données
Modèle logique d'intervention précoce et éléments déclencheurs en cas d'atteinte à la protection de la vie privée
Communications externes
Portail modernisé sur la protection de la vie privée
Engagement organisationnel
Appui des cadres
Dirigeant principal de la protection des renseignements personnels
Bureau de gestion de la protection de la vie privée (experts)
Production de rapports
Coûts
En 2024-2025, le Bureau de l’AIPRP a dépensé environ 36 726 $ en salaires et 532 $ en frais administratifs pour l’application de la Loi sur la protection des renseignements personnels.
Formation et sensibilisation
En 2024-2025, le Bureau de l’accès à l’information et de la protection des renseignements personnels (AIPRP) a offert des séances individuelles informelles pour aider les employés à comprendre leurs obligations en vertu de la Loi sur la protection des renseignements personnels et des politiques internes connexes.
Au cours de la période de déclaration, il n’a pas été nécessaire de dispenser une formation supplémentaire aux agents de liaison. Avec un roulement minimal, les liaisons ont entretenu des relations étroites et des communications ouvertes avec le Bureau de l’AIPRP.
Le Bureau de la gestion de la protection de la vie privée et de la coordination de l’information (BGPVPCI) offre également une formation sur des sujets liés à la Loi sur la statistique, à la Loi sur la protection des renseignements personnels et aux politiques qui les accompagnent.
Les cours comprennent :
Évaluation des facteurs relatifs à la vie privée
Protection des renseignements personnels et confidentialité
Ils mettent l’accent sur l’utilisation appropriée des renseignements personnels concernant les employés, les clients et le public.
En outre, tous les employés doivent suivre une formation obligatoire en matière de confidentialité en ligne, y compris un cours d’introduction pour les nouveaux employés.
Au cours de la période visée par le rapport, la COCOVINU a organisé la Semaine de sensibilisation à la protection de la vie privée 2025, du 28 avril au 2 mai, pour présenter les services de l’équipe de gestion de la protection de la vie privée. Le dirigeant principal de la protection des renseignements personnels a animé une discussion entre un groupe d’experts sur l’amélioration de la protection de la vie privée au sein du gouvernement. L’événement a suscité une forte mobilisation et des réactions positives. Des rencontres bilatérales régulières entre Statistique Canada et le Commissariat à la protection de la vie privée (CPVP) continuent d’appuyer le dialogue sur les programmes et les pratiques en matière de protection de la vie privée.
Politiques, directives et procédures
Outils et soutiens internes
Le Bureau de l’AIPRP dispose d’une série d’outils internes pour aider les personnes-ressources du secteur à s’acquitter de leurs responsabilités en ce qui a trait aux demandes de renseignements personnels. Ces outils comprennent :
Une liste de vérification concise décrivant les étapes de préparation de documents pertinents;
Soutien continu d’un conseiller désigné de l’AIPRP tout au long du processus de demande.
Ces ressources assurent l’uniformité et l’exactitude du traitement des demandes de renseignements personnels à l’échelle de l’organisme.
Harmonisation avec les politiques pangouvernementales
Le Bureau de l’AIPRP assure la conformité aux politiques et directives du gouvernement du Canada publiées par le Secrétariat du Conseil du Trésor du Canada (SCT) concernant la protection des renseignements personnels. Tous les renseignements personnels et confidentiels sont protégés en vertu de la Loi sur la protection des renseignements personnels et de la Loi sur la statistique et ne sont divulgués que conformément aux dispositions de ces lois.
Cadre de gouvernance de protection de la vie privée
Statistique Canada a élaboré et publié un Cadre de protection de la vie privée exhaustif qui décrit l’étendue complète des contrôles de la vie privée intégrés à ses activités. Ce cadre consolide les pratiques, les procédures et les mécanismes de gouvernance approuvés liés à la protection des renseignements personnels.
À Statistique Canada, le directeur du Bureau de gestion de la protection de la vie privée et de coordination de l’information a été officiellement désigné dirigeant principal de la protection des renseignements personnels (DPPRP) pour Statistique Canada par le statisticien en chef. Le DPPRP assure un leadership stratégique pour les enjeux liés à la protection de la vie privée, veille à ce que la protection de la vie privée soit intégrée aux décisions opérationnelles et supervise la mise en oeuvre des politiques administratives et des pratiques exemplaires visant à protéger les renseignements personnels.
Garantir la vie privée et la sécurité des fonctionnaires
L’Avis de mise en oeuvre sur l’accès à l’information et la protection des renseignements personnels 2024-01, entré en vigueur le 13 novembre 2024, vise à aider les bureaux de l’accès à l’information et de la protection des renseignements personnels (AIPRP) à gérer et à traiter les demandes d’accès à l’information (AI) et de renseignements personnels qui peuvent présenter des risques pour la sécurité et le bien-être des fonctionnaires. Plus précisément, il traite des situations où la nature de la demande soulève des préoccupations non pas en raison des fonctions professionnelles de l’individu, mais en raison de son identité ou de ses caractéristiques personnelles.
Ces demandes peuvent porter sur des renseignements qui empiètent sur la vie privée d’employés ou d’agents du gouvernement. L’avis fournit également des orientations sur les circonstances dans lesquelles la reconnaissance ou la divulgation des renseignements demandés pourrait vraisemblablement menacer la vie, l’intégrité physique ou la santé et la sécurité psychologiques d’un fonctionnaire.
Initiatives et projets visant à améliorer la protection de la vie privée
The Bureau de l’AIPRP continue d’utiliser l’outil de déclaration en ligne de l’AIPRP pour recevoir les demandes présentées par voie électronique et y répondre. Au cours de cette période de déclaration, l’outil de déclaration en ligne a été mis à jour pour permettre l’envoi des dossiers de diffusion en toute sécurité aux demandeurs qui ont créé un profil. Cette méthode permet d’envoyer les documents de manière sécuritaire et de transmettre des dossiers plus volumineux que ceux qui peuvent normalement être envoyés par courrier électronique.
Pendant la période de déclaration, le Bureau de l’AIPRP a réamorcé la collaboration avec des partenaires clés — y compris le Secrétariat du Conseil du Trésor du Canada (SCT), Services partagés Canada (SPC), Services publics et Approvisionnement Canada (SPAC), Statistique Canada (secteur 9) et OPEXUS — afin de faire avancer les discussions sur la modernisation des plateformes technologiques qui appuient les opérations de l’AIPRP. Cet effort de collaboration vise à améliorer l’efficacité, l’accessibilité et la réactivité du processus d’AIPRP afin de mieux répondre aux besoins des demandeurs.
Résumé des enjeux clés et mesures prises en réponse aux plaintes
À la fin de la période de déclaration, aucune des deux plaintes ouvertes n’avait été réglée. Le Bureau de l’AIPRP continue de travailler en étroite collaboration avec le Commissariat à la protection de la vie privée (CPVP) pour régler les problèmes soulevés et demeure déterminé à régler ces deux enjeux en temps opportun et de manière transparente.
Atteintes à la vie privée
Le Protocole en cas d’atteinte portée aux renseignements et à la protection de la vie privée fournit une désignation claire des divers rôles et responsabilités en cas de violation. Il comporte l’exigence de remplir un modèle standard qui intègre les éléments proposés dans les directives du Secrétariat du Conseil du Trésor sur la manière de répondre à une atteinte à la vie privée. Ce modèle a été approuvé par la haute direction de l’organisme. Le rapport d’incident doit, à tout le moins, contenir les renseignements suivants :
une description de l’incident (qui, quoi, quand, où, pourquoi, comment);
les mesures déjà prises et les mesures prévues;
une description des risques et des incidences;
tout autre renseignement pouvant être utile pour retrouver les éléments d’information perdus, ou pour évaluer les conséquences de leur perte ou de l’atteinte à leur intégrité;
les recommandations pour atténuer ou éliminer le risque qu’un incident semblable se reproduise à l’avenir;
une mention indiquant si les personnes ou les organisations touchées par l’atteinte à la vie privée en ont été informées;
une indication selon laquelle les personnes, le CPVP et le Secrétariat du Conseil du Trésor seront avisés de l’incident et, dans le cas contraire, la raison pour laquelle ils n’ont pas été avisés.
Les pratiques exemplaires permettant de réduire ou d’éliminer la possibilité qu’un incident similaire se reproduise, qui auront été mises en lumière lors d’une enquête, devront être communiquées aux autres employés à des fins de prévention.
Les atteintes à la protection des renseignements personnels sont coordonnées par l’équipe de la gestion de la vie privée pour s’assurer que tous les programmes touchés puissent faire part de leurs commentaires.
Il y a eu, à Statistique Canada, sept (7) atteintes à la vie privée au cours de la période de déclaration; aucune n’était substantielle. Au total, 10 personnes ont été touchées par six (6) de ces atteintes. Bien qu’aucune divulgation non autorisée n’ait été confirmée pour le 7e incident lié à un système interne de gestion des cas qui traite des renseignements sur les RH, des pièces jointes de nature sensible soumises par 250 à 1000 employés au moyen du système auraient pu être consultées par des gestionnaires pour qui ces renseignements n’auraient pas dû être accessibles.
Évaluation des facteurs relatifs à la vie privée
La Directive sur les EFVP de Statistique Canada définit les rôles et les responsabilités des cadres supérieurs et des spécialistes de la protection de la vie privée en ce qui a trait à la collecte, à l’utilisation et à la diffusion de renseignements personnels. Cette directive s’applique à tous les programmes statistiques et non statistiques qui comportent des activités de collecte, d’utilisation ou de diffusion de renseignements personnels.
L’EFVP générique de Statistique Canada couvre tous les aspects des programmes statistiques de Statistique Canada qui recueillent, utilisent et divulgation des renseignements à l’appui du mandat confié par la Loi sur la statistique. L’EFVP générique s’appuie sur les dix principes afférents à la protection des renseignements personnels et comprend une évaluation de la menace et des risques pour divers modèles d’accès et de collecte.
Des suppléments à l’EFVP générique sont produits pour toutes les activités nouvelles ou substantiellement remaniées de collecte, d’utilisation ou de divulgation de renseignements personnels qui posent des risques particuliers ou accrus sur le plan de la protection de la vie privée, de la confidentialité ou de la sécurité. L’EFVP générique et ses suppléments sont publiés sur le site Web de Statistique Canada : Évaluation générique des facteurs relatifs à la vie privée.
Des évaluations particulières des facteurs relatifs à la vie privée sont également effectuées dans le cas de programmes et de services administratifs nouveaux ou remaniés qui comportent des activités de collecte, d’utilisation ou de divulgation de renseignements personnels qui ne sont pas abordées dans l’EFVP générique. Les résumés des évaluations des facteurs relatifs à la vie privée effectuées sont publiés sur le site Web de Statistique Canada : Évaluation des facteurs relatifs à la vie privée.
Au cours de la période visée par ce rapport, 14 évaluations de la protection de la vie privée (2 EFVP, 6 suppléments et 6 modifications ou ajouts) ont été approuvées et transmises au Commissariat à la protection de la vie privée et au Secrétariat du Conseil du Trésor. Voici de brèves descriptions de ces évaluations :
Sûreté et sécurité au Centre d’examen mobile du Centre des mesures directes de la santé — Système de caméras de sécurité
Une EFVP générique a été réalisée afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’ajout de caméras de sécurité au Centre d’examen mobile (CEM) du Centre des mesures directes de la santé (CMDS) de Statistique Canada, et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Les caméras de sécurité permettent de prévenir et de détecter les crimes, et contribuent à la sécurité publique, ainsi qu’à la collecte de preuve et à la réponse aux urgences. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes et aux mesures de protection supplémentaires qui ont été mises en place.
Application StatsCAN
Une EFVP générique a été réalisée afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés aux nouvelles fonctionnalités introduites sur l’application StatsCAN, et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. De nouvelles fonctionnalités qui utilisent certaines données utilisateur ont été mises en place, comme un formulaire de rétroaction, des mesures dans l’application et des notifications poussées. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête canadienne sur le logement
Un supplément à l’EFVP générique a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à la collecte de nouveaux renseignements dans l’Enquête canadienne sur le logement (ECL), et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire qui recueille des renseignements sociodémographiques de nature délicate sur les adultes et les mineurs, notamment au moyen de réponses par procuration pour d’autres membres du ménage, a été élargie pour inclure des questions sur l’âge, le sexe à la naissance, l’identité et l’expression du genre, l’orientation sexuelle, l’immigration et la citoyenneté, les origines ethniques et culturelles, la religion, les problèmes de santé de longue durée et les incapacités, et l’état matrimonial. Les renseignements tirés de l’enquête aident à comprendre et à traiter des enjeux comme l’accès à un logement abordable et à améliorer les conditions de logement. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête canadienne sur les conditions de travail
Un supplément à l’EFVP générique a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’Enquête canadienne sur les conditions de travail (ECCT), et, si c’était le cas, de formuler des recommandations visant à les résoudre ou les atténuer. Cette enquête volontaire recueille des renseignements sur les expériences vécues comme victimes de harcèlement, de violence et de discrimination dans les milieux de travail. Elle complète les données de l’Enquête sur la population active (EPA) et de ses suppléments afin d’offrir un tableau complet de la qualité de l’emploi au Canada et met en évidence les différences dans le marché du travail et les conditions de travail des sous-populations, comme les immigrants et les groupes racisés. Elle contribue à éclairer la recherche et les politiques liées à la qualité de l’emploi au Canada. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête sur les expériences parentales
Un supplément à l’EFVP générique a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’Enquête sur les expériences parentales (EEP), et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire recueille des renseignements potentiellement délicats auprès de répondants âgés de 15 ans et plus, comme les antécédents de grossesse et les pertes, les expériences difficiles pendant la grossesse et la naissance, la santé mentale, la consommation de substances et les expériences de violence familiale ou de mauvais traitements pendant l’enfance. Les résultats aident à éclairer des recommandations nationales sur les soins à la mère et au nouveau-né ainsi que des efforts visant à améliorer la santé mentale et le bien-être des parents et des familles à travers le Canada. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête sur la sécurité dans les espaces publics et privés
Un supplément à l’EFVP générique a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’Enquête sur la sécurité dans les espaces publics et privés (ESEPP), et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire recueille des renseignements délicats auprès de répondants âgés de 15 ans et plus. Elle décrit les mesures additionnelles mises en oeuvre pour aider les répondants pendant la collecte, et les protections entourant l’accès à l’information. L’enquête fournit des renseignements sur la prévalence et la nature du harcèlement, de la discrimination et de la victimisation avec violence dans les foyers canadiens, les milieux de travail, les écoles, les espaces publics et en ligne, et explore les différences dans ces expériences en fonction de l’âge, du sexe et du genre, de l’orientation sexuelle et d’autres facteurs sociodémographiques, ce qui éclairera les politiques, les lois, les programmes et les services de soutien visant à prévenir et à traiter la victimisation. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête sur les transitions familiales
Un supplément à l’EFVP générique a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’Enquête sur les transitions familiales (ETF), et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire comprend des questions sur la vie familiale et les trajectoires familiales des répondants, y compris des renseignements personnels concernant les dates des événements familiaux, l’identité de genre, l’orientation sexuelle, les ex-conjoints/ex-partenaires, les enfants et d’autres membres de la famille ou du ménage. Les données servent à mieux comprendre comment les besoins des familles canadiennes ont évolué au cours des dernières décennies et à évaluer la pertinence des programmes et des politiques liés aux familles. Cette évaluation n’a mis au jour aucun risque relatif à la vie privée qui ne puisse être géré au moyen des mesures de protection existantes.
Série d’enquêtes auprès des membres des Premières Nations, des Métis et des Inuit
Un supplément à l’EFVP générique a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à la Série d’enquêtes auprès des membres des Premières Nations, des Métis et des Inuit (SEPNMI), et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire comprend des questions délicates sur la discrimination en matière de soins de santé et l’accès aux services de santé, la confiance envers les institutions, les répercussions de la hausse des prix et le revenu. Les données servent à fournir des observations et à combler les lacunes dans les données sur l’accès aux soins de santé, la discrimination dans un milieu de soins de santé, le bien-être, l’incidence de la hausse des prix, la préparation aux urgences et l’accès à l’eau potable pour les membres des Premières Nations vivant hors réserve, les Métis et les Inuit. Cette évaluation n’a mis au jour aucun risque relatif à la vie privée qui ne puisse être géré au moyen des mesures de protection existantes.
Étude « Mobiliser l’innovation culturelle des personnes en situation de handicap »
Une modification l’Étude « Mobiliser l’innovation culturelle des personnes en situation de handicap » : Enquête sur l’emploi et l’accessibilité dans l’EFVP et la consultation sur la DEI au moyen de l’application Recollective a été menée afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’usage de Drupal pour effectuer l’enquête et le couplage additionnel de certaines données administratives des RH (dossiers personnels des employés) pour remplacer le besoin de poser une poignée de questions d’enquête, améliorant ainsi la qualité des données et réduisant le fardeau de réponse, et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Drupal est une interface de collecte directe sur le Web qui est actuellement utilisée par Statistique Canada et qui a été évaluée et autorisée par l’équipe de sécurité des TI de l’organisme à traiter des renseignements de niveau protégé B. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Sondage auprès des fonctionnaires fédéraux
Une modification a été apportée à l’EFVP du Sondage auprès des fonctionnaires fédéraux (SAFF) afin de déterminer s’il y a eu des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité en lien avec les changements proposés et les activités additionnelles, à savoir l’acquisition des données des SAFF de 2018, 2019 et 2020 auprès du Secrétariat du Conseil du Trésor du Canada (SCT) en vertu de la Loi sur la statistique; et la suppression du nombre cumulatif des répondants de l’outil de déclaration sur le taux de collecte utilisé pour le SAFF de 2022-2023 et pour les utilisations futures de l’outil, puis qu’il n’est plus jugé nécessaire, et si c’était le cas, de formuler des recommandations visant à les résoudre ou les atténuer. Cette évaluation n’a mis au jour aucun risque relatif à la vie privée qui ne puisse être géré au moyen des mesures de protection existantes.
Test du recensement de 2024
Un addenda au supplément à l’EFVP générique de Statistique Canada concernant le Test du recensement de 2024 a été réalisé pour déterminer s’il y avait des questions de confidentialité ou de sécurité liées à l’ajout d’une question sur l’orientation sexuelle qui est examinée pour le Recensement de 2026 et les préoccupations possibles des Canadiens au sujet du caractère inclusif de la collecte et, le cas échéant, pour formuler des recommandations en vue de leur résolution ou de leur atténuation. Les données viseraient à combler une lacune identifiée et à répondre aux besoins cernés des intervenants, à assurer la représentation de tous les Canadiens et à appuyer les programmes qui offrent à tous des chances égales de participer à la vie sociale, culturelle et économique du Canada. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête sur les services correctionnels canadiens
Un addenda à l’EFVP générique de Statistique Canada lié à l’Enquête sur les services correctionnels canadiens (ESCC) a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’ajout de renseignements personnels de nature délicate à l’enquête, et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire a permis d’ajouter des questions sur le sexe à la naissance et le genre, les identités multiples pour les groupes racisés, l’indicateur de l’itinérance et le numéro du Programme de placement et de surveillance dans le cadre d’un programme intensif de réadaptation. Les nouveaux éléments de données aident à combler les lacunes en matière de données et permettent une capacité d’analyse accrue qui éclairent et contribuent à l’élaboration de politiques et de programmes fondés sur des données probantes qui profiteront aux programmes des services correctionnels et aux partenaires de la justice, ainsi qu’au public canadien. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête canadienne sur les mesures de la santé
Un addenda à l’EFVP générique de Statistique Canada lié à l’Enquête canadienne sur les mesures de la santé (ECMS) a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à l’utilisation de clés USB dans des cliniques de santé temporaires et l’utilisation d’ordinateurs portables autonomes et de clés USB pour transférer des données entre des appareils non connectés et des appareils connectés aux serveurs du réseau privé sécurisé de Statistique Canada dans les cliniques de santé temporaires, et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Enquête canadienne sur la santé des enfants et des jeunes
Un addenda à l’EFVP générique de Statistique Canada lié à l’Enquête canadienne sur la santé des enfants et des jeunes (ECSEJ) a été réalisé afin de déterminer s’il y avait des enjeux touchant la protection de la vie privée, la confidentialité ou la sécurité associés à des changements dans le contenu, la méthodologie et la stratégie de communication avec les répondants pour l’enquête, et, le cas échéant, de formuler des recommandations quant à leur résolution ou leur atténuation. Cette enquête volontaire, qui comprendra maintenant une seule période de collecte plutôt que deux, est maintenant beaucoup plus courte puisque plusieurs modules ont été supprimés et de nouveaux modules ont été introduits. Le programme est également étendu aux territoires, ce qui permet une couverture démographique plus exhaustive. L’évaluation n’a relevé aucun risque d’entrave à la protection de la vie privée qui ne peut être géré au moyen des mesures de protection existantes.
Couplage de microdonnées
Comme le stipule la Directive sur le couplage de microdonnées de Statistique Canada, les couplages de différents enregistrements se rapportant à une même personne sont uniquement menés à des fins statistiques et seulement lorsque leur apport à l’intérêt public l’emporte clairement sur les risques d’atteinte à la vie privée des personnes visées. Un des principaux objectifs du couplage d’enregistrements est de produire des renseignements statistiques permettant de mieux comprendre la société canadienne, l’économie et l’environnement.
Toutes les propositions de couplage de microdonnées sont soumises à un processus d’examen décrit dans la directive. En plus de démontrer l’avantage pour le public, chaque proposition doit donner des détails sur les résultats. La diffusion publique de tout renseignement résultant d’un couplage de microdonnées, comme de tout autre renseignement statistique, se fait uniquement à un niveau agrégé qui assure la protection de la confidentialité des renseignements personnels.
En 2023-2024, 28 couplages de microdonnées comportant des renseignements personnels ont été approuvés. Un résumé de ces couplages de microdonnées figure à l’annexe C.
Divulgations de renseignements dans l’intérêt public
Aucune divulgation n'a été faite en vertu de l'alinéa 8(2)(m) de la Loi sur la protection des renseignements personnels au cours de la période visée par le rapport.
Surveillance de la conformité
À Statistique Canada, le Bureau de l’AIPRP traite les demandes et en fait le suivi en les enregistrant dans un système appelé Privasoft – Access Pro Case Management. Un accusé de réception de la demande est envoyé au client et un formulaire de recherche est transmis au secteur de programme concerné (bureau de première responsabilité [BPR]). Si le BPR et le Bureau de l’AIPRP doivent obtenir des précisions sur la demande, le Bureau de l’AIPRP communique avec le client. Statistique Canada examine actuellement les options pour une nouvelle solution logicielle dont il ferait l’acquisition, qui appuiera la modernisation et l’amélioration du traitement des demandes reçue par l’organisme. Le processus d’acquisition est chapeauté par le Secrétariat du Conseil du Trésor du Canada au nom du gouvernement du Canada.
Le formulaire de récupération fourni au BPR a été créé par le Bureau de l’AIPRP de Statistique Canada et est basé sur la Directive sur les demandes d’accès à l’information du Secrétariat du Conseil du Trésor du Canada. Sur le formulaire figurent le texte de la demande, le nom et le numéro de téléphone de l’agent de l’AIPRP et la date à laquelle les documents doivent être fournis (normalement un délai de 5 à 10 jours). Le formulaire comprend une liste de vérification que les BPR remplissent pour confirmer qu’ils ont effectué une recherche approfondie ainsi qu’un calendrier de recommandations pour déterminer les renseignements sensibles et la nature particulière du préjudice qui pourrait être causé par la diffusion.
La personne fournissant les dossiers est invitée à identifier tout dossier qui pourrait être de nature sensible (par exemple, des questions juridiques, des confiances du Cabinet, des informations personnelles, des informations sur les entreprises, des conseils au ministre), ce qui pourrait nécessiter des consultations, et/ou qui pourrait susciter l’intérêt des médias. Le directeur général, ou le délégué approprié du secteur de programme a signé le formulaire.
Le Bureau de l’AIPRP aide les secteurs de programme avec les procédures administratives liées à la récupération des dossiers. Une fois les documents reçus du BPR, le Bureau de l’AIPRP s’assure qu’un formulaire de recherche est dûment complété par le directeur du programme. Le BPR et les directeurs de programme sont rappelés de répondre aux demandes de l’AIPRP de manière opportune et exhaustive. Le rendement des BPR en matière de réponse aux demandes de documents est présenté à la haute direction dans un tableau de bord mensuel, afin de s’assurer que tous les problèmes sont cernés et résolus.
Dans le cadre de l’examen des documents pertinents, si des documents ont été créés par un autre organisme ou lui appartiennent, nous ne procédons à des consultations en vertu de la Loi sur la protection des renseignements personnels que nous avons des raisons de penser qu’un caviardage doit être appliqué. En vertu de la Loi sur la protection des renseignements personnels, nous cherchons à limiter les consultations dans la mesure du possible afin de préserver la confidentialité du demandeur. En ce qui concerne les demandes de renseignements personnels reçues au cours de l’exercice, nous n’avons consulté que le ministère de la Justice, dans les cas où une affaire était en cours devant les tribunaux.
Les renseignements demandés en vertu de la Loi sur la protection des renseignements personnels peuvent généralement être fournis dans le délai de 30 jours. Les données du recensement peuvent être demandées en vertu de la Loi ou par l’intermédiaire de la Sous-section des microfilms et des recherches aux fins des pensions (recensement). Le volume de demandes reçues par l’organisme n’est pas assez élevé pour justifier la création d’une autre méthode d’accès.
Annexe A : Ordonnance de délégation
Arrêté sur la délégation en vertu des Lois sur l'accès àl'information et la protection des renseignements personnels
En vertu de l'article 73 de la Loi sur l'accès à l'information et de l'article 73 de la Loi sur la protection des renseignements personnels, le Ministre de l'Innovation, des Sciences et de l'Industrie délègue aux titulaires des postes mentionnés à l'annexe ci-après, ainsi qu'aux personnes occupant à titre intérimaire les-dits postes, les attributions dont il est, en qualité de responsable de Statistique Canada, investi par les articles des Lois mentionnées en regard de chaque poste. Le présent décret de délégation remplace et annule tout décret antérieur.
Annexe
Poste
Loi sur l'acces à l'information et règlements
Loi sur la protection des renseignements personnels et règlements
Statisticien en chef du Canada
Autorité absolue
Autorité absolue
Chef de cabinet, Bureau du Statisticien en chef
Autorité absolue
Autorité absolue
Directeur(trice), Bureau de gestion de la protection de la vie privée et de coordination de l'information
Autorité absolue
Autorité absolue
Directeur(trice) Adjoint(e) Bureau de gestion de la protection de la vie privée et de coordination de l'information
Autorité absolue
Autorité absolue
Gestionnaire principal(e) de projet, Accés à l'information et la protection des renseignements personnels
La version originale a été signée par
L'honorable Françoeis-Philippe Champagne
Ministre de l'innovation, des sciences et de l'industrie
Daté, en la ville d'Ottawa
Le 18 mai 2021
Annexe B : Rapport statistique sur la Loi sur la protection des renseignements personnels
Nom de l'institution : Statistique Canada
Période d'établissement de rapport : 2024-04-01 à 2025-03-31
Section 1 – Demandes en vertu de la Loi sur la protection des renseignements personnels
1.1 Nombre de demandes reçues
Nombre de demandes reçues
Nombre de demandes
Reçues pendant la période d'établissement de rapport
40
En suspens à la fin de la période d'établissement de rapport précédente
1
En suspens à la fin de la période d'établissement de rapport précédente
1
En suspens pour plus d'une période d'établissement de rapport Total
0
Total
41
Fermées pendant la période d'établissement de rapport
34
Reportées à la prochaine période d'établissement de rapport
7
Reportées à la prochaine période d'établissement de rapport dans les délais prévus par la Loi
5
Reportées à la prochaine période d'établissement de rapport au-delà des délais prévus par la Loi
2
1.2 Mode des demandes
Mode des demandes
Mode
Nombre de demandes
En ligne
38
Courriel
2
Poste
0
En personne
0
Téléphone
0
Télécopieur
0
Total
40
Section 2 – Demandes informelles
2.1 Nombre de demandes informelles
Nombre de demandes informelles
Nombre de demandes
Reçues pendant la période d'établissement de rapport
1
En suspens à la fin de la période d'établissement de rapport précédente
0
En suspens à la fin de la période d'établissement de rapport précédente
0
En suspens pour plus d'une période d'établissement de rapport
0
Total
1
Fermées pendant la période d'établissement de rapport
1
Reportées à la prochaine période d'établissement de rapport
0
2.2 Mode des demandes informelles
Mode des demandes informelles
Mode
Nombre de demandes
En ligne
0
Courriel
1
Poste
0
En personne
0
Téléphone
0
Télécopieur
0
Total
1
2.3 Délai de traitement pour les demandes informelles
Délai de traitement pour les demandes informelles
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
0
1
0
0
0
0
0
1
2.4 Pages communiquées informellement
Pages communiquées informellement
Moins de 100 pages communiquées
De 100 à 500 pages communiquées
De 501 à 1 000 pages communiquées
De 1 001 à 5 000 pages communiquées
Plus de 5 000 pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
1
36
0
0
0
0
0
0
0
0
Section 3 – Demandes fermées pendant la période d'établissement de rapport
3.1 Disposition et délai de traitement
Disposition et délai de traitement
Disposition des demandes
Délai de traitement
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
Communication totale
3
4
1
0
0
0
0
8
Communication partielle
0
10
7
0
0
0
0
17
Exception totale
0
0
0
0
0
0
0
0
Exclusion totale
0
0
0
0
0
0
0
0
Aucun document n'existe
1
2
0
0
0
0
0
3
Demande abandonnée
3
0
1
0
0
0
0
4
Ni confirmée ni infirmée
0
2
0
0
0
0
0
2
Total
7
18
9
0
0
0
0
34
3.2 Exceptions
Exceptions
Article
Nombre de demandes
18(2)
0
19(1)(a)
1
19(1)(b)
0
19(1)(c)
0
19(1)(d)
0
19(1)(e)
0
19(1)(f)
0
20
0
21
0
22(1)(a)(i)
0
22(1)(a)(ii)
0
22(1)(a)(iii)
0
22(1)(b)
0
22(1)(c)
0
22(2)
0
22.1
0
22.2
0
22.3
0
22.4
0
23(a)
0
23(b)
0
24(a)
0
24(b)
0
25
1
26
16
27
2
27.1
0
28
0
3.3 Exclusions
Exclusions
Article
Nombre de demandes
69(1)(a)
0
69(1)(b)
0
69.1
0
70(1)
0
70(1)(a)
0
70(1)(b)
0
70(1)(c)
0
70(1)(d)
0
70(1)(e)
0
70(1)(f)
0
70.1
0
3.4 Format des documents communiqués
Format des documents communiqués
Papier
Électronique
Autres
Document électronique
Ensemble de données
Vidéo
Audio
2
23
0
0
0
0
3.5 Complexité
3.5.1 Pages pertinentes traitées et communiquées en formats papier, document électronique et ensemble de données
Pages pertinentes traitées et communiquées en formats papier, document électronique et ensemble de données
Nombre de pages traitées
Nombre de pages traitées
Nombre de demandes
3813
2660
31
3.5.2 Pages pertinentes traitées en fonction de l’ampleur des demandes en formats papier, document électronique et ensemble de données par disposition des demandes
Pages pertinentes traitées en fonction de l’ampleur des demandes en formats papier, document électronique et ensemble de données par disposition des demandes
Disposition
Moins de 100 pages traitées
De 100 à 500 pages traitées
De 501 à 1 000 pages traitées
1 001 à 5 000 pages traitées
Plus de 5 000 pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Nombre de demandes
Pages traitées
Communication totale
7
35
1
101
0
0
0
0
0
0
Communication partielle
10
342
5
1249
1
517
1
1569
0
0
Exception totale
0
0
0
0
0
0
0
0
0
0
Exclusion totale
0
0
0
0
0
0
0
0
0
0
Demande abandonée
4
0
0
0
0
0
0
0
0
0
Ni confirmée ni infirmée
2
0
0
0
0
0
0
0
0
0
Total
23
377
6
1350
1
517
1
1569
0
0
3.5.3 Minutes pertinentes traitées et communiquées en format audio
Minutes pertinentes traitées et communiquées en format audio
Nombre de minutes traitées
Nombre de minutes communiquées
Nombre de demandes
0
0
0
3.5.4 Minutes pertinentes traitées en fonction de l'ampleur des demandes en format audio par dispositions des demandes
Minutes pertinentes traitées en fonction de l'ampleur des demandes en format audio par dispositions des demandes
Disposition
Moins de 60 minutes traitées
60-120 minutes traitées
Plus de 120 minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Communication totale
0
0
0
0
0
0
Communication partielle
0
0
0
0
0
0
Exception totale
0
0
0
0
0
0
Exclusion totale
0
0
0
0
0
0
Demande abandonnée
0
0
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
0
0
Total
0
0
0
0
0
0
3.5.5 Minutes pertinentes traitées et communiquées en format vidéo
Minutes pertinentes traitées et communiquées en format vidéo
Nombre de minutes traitées
Nombre de minutes communiquées
Nombre de demandes
0
0
0
3.5.6 Minutes pertinentes traitées en fonction de l'ampleur des demandes en format vidéo par dispositions des demandes
Minutes pertinentes traitées en fonction de l'ampleur des demandes en format vidéo par dispositions des demandes
Disposition
Moins de 60 minutes traitées
60-120 minutes traitées
Plus de 120 minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Nombre de demandes
Minutes traitées
Communication totale
0
0
0
0
0
0
Communication partielle
0
0
0
0
0
0
Exception totale
0
0
0
0
0
0
Exclusion totale
0
0
0
0
0
0
Demande abandonnée
0
0
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
0
0
Total
0
0
0
0
0
0
3.5.7 Autres complexités
Autres complexités
Disposition
Consultation requise
Avis juridique
Renseignements entremêlés
Autres
Total
Communication totale
0
0
0
0
0
Communication partielle
0
1
0
0
1
Exception totale
0
0
0
0
0
Exclusion totale
0
0
0
0
0
Demande abandonnée
0
0
0
0
0
Ni confirmée ni infirmée
0
0
0
0
0
Total
0
1
0
0
1
3.6 Demandes fermées
3.6.1 Nombre de demandes fermées dans les délais prévus par la Loi
Nombre de demandes fermées dans les délais prévus par la Loi
Nombre de demandes fermées dans les délais prévus par la Loi
27
Pourcentage des demandes fermées dans les délais prévus par la Loi (%)
79,41176471
3.7 Présomptions de refus
3.7.1 Motifs du non-respect des délais prévus par la Loi
Motifs du non-respect des délais prévus par la Loi
Nombre de demandes fermées au-delà des délais prévus par la Loi
Motif principal
Entrave au fonctionnement / Charge de travail
Consultation externe
Consultation interne
Autres
7
0
0
0
7
3.7.2 Demandes fermées au-delà des délais prévus par la Loi (y compris toute prolongation prise)
Demandes fermées au-delà des délais prévus par la Loi (y compris toute prolongation prise)
Nombre de jours au-delà des délais prévus par la Loi
Nombre de demandes fermées au-delà des délais prévus par la Loi où aucune prolongation n'a été prise
Nombre de demandes fermées au-delà des délais prévus par la Loi où une prolongation a été prise
Total
1 à 15 jours
4
0
4
16 à 30 jours
2
0
2
31 à 60 jours
0
0
0
61 à 120 jours
1
0
1
121 à 180 jours
0
0
0
181 à 365 jours
0
0
0
Plus de 365 jours
0
0
0
Total
7
0
7
3.8 Demandes de traduction
Demandes de traduction
Demandes de traduction
Acceptées
Refusées
Total
De l'anglais au français
0
0
0
Du français à l'anglais
0
0
0
Total
0
0
0
Section 4 – Communications en vertu des paragraphes 8(2) et 8(5)
Communications en vertu des paragraphes 8(2) et 8(5)
Alinéa 8(2)(e)
Alinéa 8(2)(m)
Paragraphe 8(5)
Total
0
0
0
0
Section 5 - Demandes de correction de renseignements personnels et mentions
Demandes de correction de renseignements personnels et mentions
Disposition des demandes de correction reçues
Nombre
Mentions annexées
0
Demandes de correction acceptées
0
Total
0
Section 6 – Prorogations
6.1 Motifs des prorogations
Motifs des prorogations
Nombre de prorogations prises
15a)(i) Entrave au fonctionnement de l'institution
15a)(ii) Consultation
15b) Traduction ou cas de transfert sur support de substitution
Examen approfondi nécessaire pour déterminer les exceptions
Grand nombre de pages
Grand volume de demandes
Les documents sont difficiles à obtenir
Document confidentiels du Cabinet (article 70)
Externe
Interne
3
1
1
0
1
0
0
0
0
6.2 Durée des prorogations
Durée des prorogations
Durée des prorogations
15a)(i) Entrave au fonctionnement de l'institution
15a)(ii) Consultation
15(b)Traduction ou cas de transfert sur support de substitution
Examen approfondi nécessaire pour déterminer les exceptions
Grand nombre de pages
Grand volume de demandes
Les documents sont difficiles à obtenir
Document confidentiels du Cabinet (article 70)
Externe
Interne
1 à 15 jours
0
0
0
0
0
0
0
0
16 à 30 jours
1
1
0
1
0
0
0
0
Plus de 31 jours
0
Total
1
1
0
1
0
0
0
0
Section 7 – Demandes de consultation reçues d’autres institutions et organisations
7.1 Demandes de consultation reçues d’autres institutions du gouvernement du Canada et autres organisations
Demandes de consultation reçues d’autres institutions du gouvernement du Canada et autres organisations
Consultations
Autres institutions du gouvernement du Canada
Nombre de pages à traiter
Autres organisations
Nombre de pages à traiter
Reçues pendant la période d'établissement de rapport
0
0
0
0
En suspens à la fin de la période d'établissement de rapport précédente
0
0
0
0
Total
0
0
0
0
Fermées pendant la période d'établissement de rapport
0
0
0
0
Reportées à l'intérieur des délais négociés à la prochaine période d'établissement de rapport
0
0
0
0
Reportées au-delà des délais négociés à la prochaine période d'établissement de rapport
0
0
0
0
7.2 Recommandations et délai de traitement pour les demandes de consultation reçues d’autres institutions du gouvernement du Canada
Recommandations et délai de traitement pour les demandes de consultation reçues d’autres institutions du gouvernement du Canada
Recommandation
Nombre de jours requis pour traiter les demandes de consultation
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
Communiquer en entier
0
0
0
0
0
0
0
0
Communiquer en partie
0
0
0
0
0
0
0
0
Exempter en entier
0
0
0
0
0
0
0
0
Exclure en entier
0
0
0
0
0
0
0
0
Consulter une autre institution
0
0
0
0
0
0
0
0
Autre
0
0
0
0
0
0
0
0
Total
0
0
0
0
0
0
0
0
7.3 Recommandations et délai de traitement pour les demandes de consultation reçues d’autres organisations
Recommandations et délai de traitement pour les demandes de consultation reçues d’autres organisations
Recommandation
Nombre de jours requis pour traiter les demandes de consultation
0 à 15 jours
16 à 30 jours
31 à 60 jours
61 à 120 jours
121 à 180 jours
181 à 365 jours
Plus de 365 jours
Total
Communiquer en entier
0
0
0
0
0
0
0
0
Communiquer en partie
0
0
0
0
0
0
0
0
Exempter en entier
0
0
0
0
0
0
0
0
Exclure en entier
0
0
0
0
0
0
0
0
Consulter une autre institution
0
0
0
0
0
0
0
0
Autre
0
0
0
0
0
0
0
0
Total
0
0
0
0
0
0
0
0
Section 8 – Délais de traitement des demandes de consultation sur les documents confidentiels du Cabinet
8.1 Demandes auprès des services juridiques
Demandes auprès des services juridiques
Nombre de jours
Moins de 100 pages traitées
De 100 à 500 pages traitées
De 501 à 1 000 pages traitées
1 001 à 5 000 pages traitées
Plus de 5 000 pages traitées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
1 à 15
0
0
0
0
0
0
0
0
0
0
16 à 30
0
0
0
0
0
0
0
0
0
0
31 à 60
0
0
0
0
0
0
0
0
0
0
61 à 120
0
0
0
0
0
0
0
0
0
0
121 à 180
0
0
0
0
0
0
0
0
0
0
181 à 365
0
0
0
0
0
0
0
0
0
0
Plus de 365
0
0
0
0
0
0
0
0
0
0
Total
0
0
0
0
0
0
0
0
0
0
8.2 Demandes auprès du Bureau du Conseil privé
Demandes auprès du Bureau du Conseil privé
Nombre de jours
Moins de 100 pages traitées
De 100 à 500 pages traitées
De 501 à 1 000 pages traitées
1 001 à 5 000 pages traitées
Plus de 5 000 pages traitées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
Nombre de demandes
Pages communiquées
1 à 15
0
0
0
0
0
0
0
0
0
0
16 à 30
0
0
0
0
0
0
0
0
0
0
31 à 60
0
0
0
0
0
0
0
0
0
0
61 à 120
0
0
0
0
0
0
0
0
0
0
121 à 180
0
0
0
0
0
0
0
0
0
0
181 à 365
0
0
0
0
0
0
0
0
0
0
Plus de 365
0
0
0
0
0
0
0
0
0
0
Total
0
0
0
0
0
0
0
0
0
0
Section 9 – Avis de plaintes et d'enquêtes reçus
Avis de plaintes et d'enquêtes reçus
Article 31
Article 33
Article 35
Recours judiciaire
Total
0
0
0
0
0
Section 10 – Évaluations des facteurs relatifs à la vie privée (ÉFVP) et des Fichiers de renseignements personnels (FRP)
10.1 Évaluations des facteurs relatifs à la vie privée
Évaluations des facteurs relatifs à la vie privée
Nombre d'ÉFVP terminées
3
Nombre d'ÉFVP modifiées
12
10.2 Fichiers de renseignements personnels spécifiques à l'institution et centraux
Fichiers de renseignements personnels spécifiques à l'institution et centraux
Fichiers de renseignements personnels
Actifs
Créés
Supprimés
Modifiés
Spécifiques à l'institution
62
3
0
0
Centraux
0
0
0
0
Total
62
3
0
0
Section 11 – Atteintes à la vie privée
11.1 Atteintes substantielles à la vie privée signalée
Atteintes substantielles à la vie privée signalée
Nombre d'atteintes substantielles à la vie privée signalées au SCT
0
Nombre d'atteintes substantielles à la vie privée signalées au CPVP
0
11.2 Atteintes à la vie privée signalée non-substantielles
Atteintes à la vie privée signalée non-substantielles
Nombre d'atteintes à la vie privée non-substantielles
7
Section 12 – Ressources liées à la Loi sur la protection des renseignements personnels
12.1 Coûts répartis
Coûts répartis
Dépenses
Montant
Salaires
35 745 $
Heures supplémentaires
981 $
Biens et services
532 $
Contrats de services professionnels
0 $
Autre
532 $
Total
37 258 $
12.2 Ressources humaines
Ressources humaines
Ressources
Années-personnes consacrées aux activités liées à la protection des renseignements personnels
Employés à temps plein
0,380
Employés à temps partiel et occasionnels
0,000
Employés régionaux
0,000
Experts-conseils et personnel d'agence
0,000
Étudiants
0,000
Total
0,380
Remarque : Entrer des valeurs à trois décimales.
Annexe C : Couplage de microdonnées 2024-2025
Couplages de microdonnées approuvés contenant des renseignements personnels
Projet pilote de couplage du Tribunal des droits de la personne avec les données du recensement, les données fiscales, les données judiciaires et les données sur la santé pour déterminer la prévalence, la nature et l’incidence du dépôt d’une plainte relative aux droits de la personne au Canada, afin de mieux éclairer les mesures de prévention et d’autres formes de soutien aux plaignants (008-2024)
Objet : L’objet du présent projet est de combler les lacunes actuelles en matière de données liées aux répercussions du dépôt d’une plainte relative aux droits de la personne sur les plaignants, jusqu’à la résolution de la question et par la suite au Canada. Ces données sont nécessaires à la création d’un ensemble de connaissances amélioré sur la prévalence, la nature et l’incidence du dépôt d’une plainte relative aux droits de la personne au Canada, ce qui éclairera mieux les mesures de prévention et d’autres formes de soutien aux plaignants. Les données aideront également à fournir des renseignements représentatifs sur les facteurs de risque et les sous-populations ayant la plus grande probabilité de subir de la discrimination, ce qui permettra donc de mieux éclairer les futures mesures de prévention et formes de soutien.
Produit : Les données couplées seront utilisées par Statistique Canada pour produire des résultats analytiques pour le client et les fournisseurs de données sous forme de tableaux personnalisés, de feuillets d’information et d’un rapport analytique.
Caractéristiques liées à la diversité du personnel enseignant à temps plein et à temps partiel dans les universités canadiennes (009-2024)
Objet : Ce projet de couplage de microdonnées a pour objectif de rassembler les caractéristiques liées à la diversité à partir d’autres sources de données et de les intégrer aux données administratives sur le personnel à temps plein, à temps partiel et contractuel enseignant dans les universités canadiennes. Ces renseignements réunis permettront de produire des statistiques agrégées sur les diverses populations au sein des universités canadiennes. Ces statistiques peuvent servir à rendre compte de la représentation des divers groupes de population parmi le personnel enseignant des universités canadiennes et aider à mesurer les progrès réalisés pour créer une communauté universitaire qui représente fidèlement la population canadienne.
Produit : Le résultat final de ce couplage de microdonnées sera anonymisé. L’accès au fichier de microdonnées couplées sera limité aux employés de Statistique Canada (y compris les personnes réputées être employées de Statistique Canada) dont le travail exige cet accès. Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. Les résultats agrégés à l’échelle des établissements seront publiés dans une étude de faisabilité, dans des rapports internes et externes et dans des présentations.
Couplage de microdonnées des fichiers d’impôt sur le revenu (Fichier des familles T1, T4, T4E et T5007) avec les utilisateurs de refuges d’urgence et les participants au programme Logement d’abord en Alberta entre 2009 et 2018 (010-2024)
Objet : L’objet du présent projet est de préparer et de réaliser une analyse d’un ensemble de données fiscales administratives longitudinales pour les personnes qui ont séjourné dans un refuge ou participé au programme Logement d’abord en Alberta entre 2009 et 2018. Le couplage entre les données de l’Alberta et les données fiscales permettra aux chercheurs et aux administrations publiques d’obtenir des renseignements sur les résultats en matière de revenu et d’emploi des participants au programme Logement d’abord, ainsi que sur les situations d’emploi avant d’entrer dans un refuge. Cette perspective facilitera l’élaboration de stratégies pour atténuer certaines des causes de l’itinérance et l’évaluation de l’efficacité du programme Logement d’abord en ce qui concerne les résultats des participants en matière de revenu et d’emploi. Les chercheurs et les administrations publiques auront accès au document analytique et aux ensembles de données couplés au moyen des centres de données de recherche.
Produit : Les résultats du présent projet seront publiés dans un rapport analytique diffusé sur le site Web de Statistique Canada. La mobilisation sera réalisée avec les intervenants autochtones appropriés avant la publication de tout document, tableau ou autre produit utilisant les ensembles de données couplés. Les fichiers analytiques, sans identificateurs, seront rendus accessibles aux fins de vérification au moyen des centres de données de recherche (CDR) de Statistique Canada. Lorsque ce processus de vérification sera terminé, les données définitives seront alors rendues accessibles sur le réseau général des CDR. L’accès sera accordé uniquement aux personnes réputées être employées de Statistique Canada, après que le processus d’approbation normalisé a suivi son cours. Seules les statistiques et analyses agrégées non confidentielles conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique et à toute exigence applicable de la Loi sur la protection des renseignements personnels seront diffusées à l’extérieur de Statistique Canada.
Couplage de microdonnées pour la totalisation des revenus de l’industrie juridique canadienne (011-2024)
Objet : Ce projet vise à fournir à la septième Commission quadriennale d’examen de la rémunération des juges du ministère de la Justice des statistiques sur les niveaux de rémunération des avocats en pratique privée et leur répartition. Les produits seront des tableaux statistiques agrégés qui permettront au ministère de la Justice d’évaluer et de déterminer la rémunération concurrentielle des juges nommés par le gouvernement fédéral. Pour entreprendre ce projet, Statistique Canada compilera les données des sociétés professionnelles de droit et des sociétés en nom collectif de droit et les joindra aux données de la Base de données canadienne sur la dynamique employeurs-employés et aux déclarations de revenus T5013 correspondantes pour la dernière année disponible, soit 2021. Les travaux porteront uniquement sur les sociétés professionnelles et en nom collectif de droit en vertu du code du SCIAN 541110 – Études d’avocats. Aucun autre code du SCIAN ne sera pris en considération.
Produit : Les tableaux statistiques agrégés ne seront mis à la disposition que du ministère de la Justice, qui est le client de ce projet. Il s’agira de tableaux sur les revenus totaux des avocats indépendants du secteur privé, des sociétés professionnelles de droit et des sociétés en nom collectif de droit pour l’année la plus récente où les données sur la source de l’impôt sur le revenu sont disponibles. Les statistiques calculées sur le revenu professionnel des avocats indépendants comprendront le nombre, la moyenne, la médiane, l’écart-type et les valeurs du 75e centile, selon l’âge et les groupes de régions métropolitaines de recensement et le seuil de faible revenu de 80 000 $. Les mêmes statistiques seront également calculées pour les sociétés en nom collectif de droit (nombre, taille, nombre de types d’associés) et le revenu généré et distribué aux associés.
Couplage du Recensement de la population avec la Banque de données administratives longitudinales (DAL) à des fins d’analyses sociodémographiques et économiques. (013-2024)
Objet : Ce projet a pour objet d’améliorer la capacité des chercheurs et des décideurs à répondre à des questions pressantes en temps opportun, de les aider à mesurer les résultats des politiques et des programmes déjà en place, et à possiblement mettre en place de nouvelles mesures ou améliorer les décisions de politique publique qui profiteront à la population canadienne. Il prévoit la création de deux fichiers de clés de couplage entre la banque DAL et celles du Recensement de 2016 et du Recensement de 2021. Ces deux fichiers seront accessibles dans les centres de données de recherche (CDR) de Statistique Canada, uniquement aux chercheurs dont les projets ont été approuvés. Ce projet comblera d’importantes lacunes dans les données en permettant de mieux comprendre les différents contextes socioéconomiques des Canadiens, et les revenus à long terme (cycle de vie, trajectoire de revenus au fil du temps) et facilitera la recherche et la formulation de recommandations sur les multiples difficultés que rencontrent les Canadiens dans leur vie quotidienne.
Produit : Comme produit final il y aura deux fichiers de clés de couplage évolutifs, qui seront actualisés annuellement lors de la mise à jour de la banque DAL : 1) le fichier de clés de couplage des données de la banque DAL avec celles du Recensement de 2016, et 2) le fichier de clés de couplage des données de la banque DAL avec celles du Recensement de 2021. Chaque fichier contiendra deux champs représentant des identificateurs d’enregistrement non confidentiels : le premier champ sera le numéro d’identification de la banque DAL et le deuxième sera le numéro d’identification du recensement. Ces deux champs permettront aux personnes réputées être employées de Statistique Canada de coupler les données de la banque DAL avec les données pertinentes tirées du questionnaire détaillé du recensement. Ces fichiers de clés de couplage seront uniquement mis à la disposition des personnes réputées être employées de Statistique Canada selon le processus d’approbation, à partir des points d’accès sécurisé de Statistique Canada (comme les CDR).
Seules les analyses et les statistiques agrégées non confidentielles qui sont conformes aux dispositions en matière de confidentialité de la Loi sur la statistique et à toute exigence applicable de la Loi sur la protection des renseignements personnels seront diffusées à l’extérieur de Statistique Canada.
Tous les produits issus du couplage des données du recensement avec celles de la banque DAL au moyen des fichiers de clés de couplage relevant de ce projet seront diffusés conformément aux politiques, aux lignes directrices et aux normes de Statistique Canada. Les produits découlant de ce couplage pourraient comprendre un grand nombre d’analyses et de tableaux de données normalisés, ainsi que des totalisations personnalisées. Toutes les données diffusées à l’extérieur des CDR ou de Statistique Canada feront l’objet d’un examen conformément aux règles de confidentialité qui s’appliquent aux produits avant leur diffusion.
Couplage des microdonnées d’Emplois d’été Canada avec le recensement et les dossiers administratifs (014-2024)
Objet : Conformément à la demande du Bureau du vérificateur général (BVG), la Division de l’analyse sociale et de la modélisation (DASM) de Statistique Canada couplera les données du programme Emplois d’été Canada (EEC) avec le recensement et les fichiers analytiques administratifs maintenus par Statistique Canada. Le fichier couplé permettra à la DASM de produire des statistiques liées à la représentation et aux résultats possibles liés à EEC en comparant les participants au programme avec des groupes de comparaison appropriés.
À cette fin, les données d’EEC (de 2008 à 2023) seront liées à une série de fichiers de données de Statistique Canada, y compris le questionnaire détaillé du Recensement de la population (2016 et 2021), le Fichier de données longitudinales sur la main-d’œuvre (2008 à 2021) et le Système d’information sur les étudiants postsecondaires (de 2009 à 2021).
Produit : Les tableaux contenant des statistiques liées à la représentation et aux résultats possibles liés à EEC seront remis au BVG (le client). Seuls les statistiques agrégées et les résultats de l’analyse descriptive et de l’analyse multivariée de cette étude seront communiqués au client sous forme de tableaux personnalisés.
Couplage des programmes de la Direction générale de l’alimentation et des boissons du ministère de l’Agriculture et de l’Alimentation de la Colombie-Britannique dans le cadre du Partenariat canadien pour l’agriculture (PCA) et l’Environnement de fichiers couplables - Entreprises (EFC-E) pour estimer l’effet des programmes sur le rendement financier des bénéficiaires (015-2024)
Objet : L’objectif principal du présent projet est d’estimer l’effet des programmes de la Direction générale de l’alimentation et des boissons du ministère de l’Agriculture et de l’Alimentation de la Colombie-Britannique dans le cadre du PCA sur le rendement financier des bénéficiaires. Les participants aux programmes de la Direction générale de l’alimentation et des boissons de la Colombie-Britannique dans le cadre du PCA seront liés à l’EFC-E pour extraire des indicateurs de rendement clés qui seront utilisés dans le cadre d’une étude d’incidence. Les résultats de l’étude permettront de mieux comprendre l’incidence sur les entreprises en Colombie-Britannique recevant un soutien par l’intermédiaire du PCA.
Produit : Les résultats seront présentés sous forme de tableaux récapitulatifs et de modèles à effets fixes qui compareront le rendement économique des entreprises ayant reçu un soutien financier à celle des entreprises non soutenues. La liste des entreprises des programmes de la Direction générale de l’alimentation et des boissons du ministère de l’Agriculture et de l’Alimentation de la Colombie-Britannique sera hébergée au Centre des projets spéciaux sur les entreprises (CPSE).
Un ensemble de données de recherche sera produit, et la base de données intégrée complète sera utilisée par une personne réputée être employée de Statistique Canada pour produire une analyse et des tableaux sur mesure de statistiques agrégées non confidentielles pour Agriculture et Agroalimentaire Canada. Le résultat sera analysé pour la confidentialité par les employés de CPSE.
Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada.
Couplage des données de l’Enquête sur les établissements de soins infirmiers et de soins pour bénéficiaires internes (EESISBI) avec certains renseignements employeurs-employés pour analyser les conditions de travail des travailleurs dans le domaine des soins de longue durée au Canada (016-2024)
Objet : Le couplage proposé réunira l’Enquête sur les établissements de soins infirmiers et de soins pour bénéficiaires internes (EESISBI) et certains fichiers de la Base de données canadienne sur la dynamique employeurs-employés (BDCDEE) afin d’appuyer la recherche sur les conditions de travail des travailleurs dans le domaine des soins de longue durée. L’objectif est de mettre en lumière les mauvais résultats économiques et en matière de santé qu’ont eus les travailleurs du secteur des soins de longue durée avant et pendant la pandémie de COVID-19.
Produit : Un fichier analytique, sans identificateurs personnels, sera produit à partir de ce processus de couplage. Les résultats méthodologiques et analytiques obtenus à partir des données couplées peuvent servir à préparer les résultats de recherche en vue de les publier dans des rapports analytiques ou des revues scientifiques à comité de lecture ou de les présenter à des conférences, à des ateliers ou à des réunions, ainsi qu’à produire des données tabulaires ou des indicateurs à diffuser sur le site Web de Statistique Canada. Des règles de contrôle de confidentialité seront élaborées et appliquées conformément aux règles en place. Seuls les données agrégées non confidentielles et les produits analytiques conformes aux dispositions en matière de confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. La proposition de couplage vise à combler un besoin actuel de réponse à une question de recherche précise et n’est pas conçue pour fournir un couplage permanent de la BDCDEE avec l’EESISBI.
Couplage des programmes agricoles à valeur ajoutée administrés par le ministère de l’Agriculture et de l’Irrigation de l’Alberta, dans le cadre du Partenariat canadien pour l’agriculture, avec l’Environnement de fichiers couplables des entreprises (EFC-E) afin d’estimer l’effet de ces programmes sur les résultats financiers des bénéficiaires. (017-2024)
Objet : L’objectif principal de ce projet est d’estimer l’effet des programmes agricoles à valeur ajoutée du ministère de l’Agriculture et de l’Irrigation de l’Alberta (AGI) :
possibilités émergentes, aliments et agrotransformation
programme de possibilités émergentes
programme de mise en marché des produits
programme de mise en marché des produits à valeur ajoutée
programme de valeur ajoutée à la ferme
programme de valeur ajoutée
dans le cadre du Partenariat canadien pour l’agriculture sur les résultats financiers des bénéficiaires. La première étape consistera à préparer les profils des participants aux programmes et à les comparer aux non-participants admissibles à l’aide des variables de l’Environnement de fichiers couplables des entreprises (EFC-E) et de la Base de données sur la diversité et les compétences (BDDC). La deuxième étape consistera à utiliser l’appariement pour constituer un groupe témoin et à utiliser des modèles de régression pour étudier l’effet des programmes sur le rendement financier des bénéficiaires (p. ex. les recettes).
Produit : Le produit prendra la forme de tableaux sommaires et d’un modèle à effets fixes qui permettront d’examiner les résultats économiques des entreprises qui ont reçu un soutien financier des programmes agricoles à valeur ajoutée du ministère de l’Agriculture et de l’Irrigation de l’Alberta dans le cadre du Partenariat canadien pour l’agriculture par rapport à des entreprises non soutenues. La liste couplée des entreprises du ministère de l’Agriculture et de l’Irrigation de l’Alberta sera hébergée au Centre des projets spéciaux sur les entreprises (CPSE) de Statistique Canada.
Un ensemble de données de recherche sera créé et la base de données intégrée sera utilisée dans son entièreté par une équipe de recherche de Statistique Canada composée de personnes réputées être employées en vue de produire une analyse et des tableaux personnalisés de statistiques agrégées non confidentielles pour Agriculture et Agroalimentaire Canada. Les résultats seront analysés par les employés du CPSE à des fins de confidentialité. Ils ne seront pas envoyés au Centre canadien d’élaboration de données et de recherche économique.
Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada.
Le rôle des politiques environnementales dans les prévisions du prix de l’énergie et les choix de production des fabricants (019 2024)
Objet : Ce projet de recherche vise à mesurer les réactions des fabricants canadiens aux changements dans les politiques environnementales. Les résultats peuvent contribuer au débat public en permettant d’évaluer les répercussions économiques et environnementales de ces politiques. Ils peuvent également aider les décideurs à déterminer l’efficacité des politiques environnementales tant sur le plan de l’économie que de l’environnement, afin de mieux évaluer les politiques environnementales existantes et d’en concevoir de meilleures à l’avenir.
Produit : Les fichiers de données anonymisées seront disponibles à partir des points d’accès sécurisés de Statistique Canada (comme les centres de données de recherche [CDR]) et l’accès sera accordé seulement aux personnes réputées être employées de Statistique Canada, conformément au processus d’approbation standard. Les chercheurs de l’Université de la Colombie Britannique et du Consumer Financial Protection Bureau utiliseront les fichiers de données anonymisées couplés pour réaliser une étude qui sera présentée à une revue à comité de lecture. Les fichiers de données anonymisées resteront dans les CDR pour les projets à venir. Seules les données agrégées non confidentielles et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusées à l’extérieur de Statistique Canada.
Seules les données agrégées non confidentielles et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusées à l’extérieur de Statistique Canada.
Initiative sur les services correctionnels communautaires destinés aux Autochtones : étude sur les nouveaux contacts (020-2024)
Objet : Ce projet vise à évaluer l’efficacité de l’Initiative sur les services correctionnels communautaires destinés aux Autochtone (ISCCA) pour ce qui est de réduire les nouveaux contacts avec le système de justice pénale. L’ISCCA appuie des solutions de rechange à l’incarcération et des projets de réinsertion sociale adaptés aux circonstances particulières des Autochtones au Canada.
Produit : Statistique Canada utilisera des fichiers analytiques couplés et des clés de couplage anonymisées pour produire des tableaux statistiques agrégés non confidentiels et des rapports analytiques à l’intention de Sécurité publique Canada.
Les répercussions du projet gouvernemental concernant l’impôt sur les gains en capital. (021-2024)
Objet : Le directeur parlementaire du budget (DPB) propose une étude visant à examiner les effets sur la répartition du changement proposé relativement au taux d’inclusion des gains en capital. Pour faciliter l’analyse du DPB, Statistique Canada effectuera le couplage d’un ensemble de certaines variables tirées de la Banque de données administratives longitudinales (DAL), des fichiers des familles T1 (FFT1), des fichiers de données fiscales des sociétés T2, ainsi que des fichiers de rémunération d’emploi T4 et des fichiers de données fiscales des sociétés de personnes T5013, pour les années 2013 à 2022. Les résultats de cette étude permettront au DPB de mieux comprendre la répartition des ménages les plus touchés par le changement proposé concernant l’impôt sur les gains en capital. Ils lui permettront également de fournir aux parlementaires des conseils indépendants, non partisans et fondés sur des données probantes à ce sujet, ce qui favorisera une plus grande transparence et responsabilisation en ce qui concerne le budget et appuiera l’élaboration de politiques fiscales justes et efficaces dans l’intérêt des Canadiens et Canadiennes.
Produit : Ce couplage de microdonnées sera conforme aux politiques et normes de Statistique Canada. Les identificateurs personnels et d’entreprise seront retirés du fichier d’analyse une fois le couplage terminé. Les chercheurs et chercheuses du Bureau du DPB, en tant que personnes réputées être employées de Statistique Canada, pourront accéder au fichier analytique dans les points d’accès sécurisés de l’organisme et ainsi effectuer l’analyse de la répartition proposée portant sur les gains en capital. Seule l’analyse non confidentielle qui ne permet pas de déterminer l’identité d’une personne, d’une entreprise ou d’une organisation sera diffusée à l’extérieur de Statistique Canada. Une fois l’analyse terminée, le Bureau du DPB préparera un rapport qu’il rendra public sur son site Web et présentera aux deux chambres du Parlement.
Couplage du programme Agri-Innover d’Agriculture et Agroalimentaire Canada (AAC) avec l’Environnement de fichiers couplables - Entreprises (EFC-E) pour estimer l’effet du programme sur le rendement financier des bénéficiaires (022-2024)
Objet : L’objectif principal du présent projet est d’estimer l’effet du programme Agri-Innover d’AAC sur le rendement financier des bénéficiaires. La phase initiale consistera à préparer des profils des participants au programme et à les comparer aux non-participants admissibles et aux participants refusés en utilisant les variables dans l’Environnement de fichiers couplables - Entreprises (EFC-E), y compris les données fiscales, la Base de données sur la diversité et les compétences (BDDC) ainsi que les variables du recensement des propriétaires d’entreprises. La deuxième phase comprendra l’utilisation de la correspondance pour constituer un groupe de référence, et l’utilisation de modèles de régression pour étudier l’effet du programme sur le rendement financier des bénéficiaires (par exemple, revenues).
Produit : Les résultats seront sous forme de tableaux récapitulatifs et d’un modèle à effets fixes qui examinera le rendement économique des entreprises ayant reçu un soutien financier du programme Agri-Innover d’AAC et de celles qui n’ont pas reçu de soutien du programme ou dont la demande a été refusée. La liste des entreprises du programme Agri-Innover d’AAC sera hébergée au Centre des projets spéciaux sur les entreprises (CPSE) de Statistique Canada, et une équipe de chercheurs réputés être employés par Statistique Canada provenant d’AAC rédigera une étude d’incidence en utilisant des variables fiscales.
Couplage de l’Enquête sur l’apprentissage des étudiants de la Colombie-Britannique avec la Plateforme longitudinale entre l’éducation et le marché du travail pour effectuer une analyse de la satisfaction des étudiants concernant les résultats pédagogiques (023-2024)
Objet : L’objet de ce projet est de comprendre la façon dont les expériences scolaires des élèves dans le système de la maternelle à la 12e année de la Colombie-Britannique diffèrent en fonction des caractéristiques démographiques et d’évaluer les résultats de l’éducation et du marché du travail des élèves en fonction de leur satisfaction scolaire. En couplant les données de la Plateforme longitudinale entre l’éducation et le marché du travail, les caractéristiques démographiques et les trajectoires des étudiants peuvent être modélisées au niveau des microdonnées.
Produit : L’accès au fichier analytique couplé sera fourni aux chercheurs du ministère de l’Éducation et des Services de garde de la Colombie-Britannique travaillant en tant que personnes réputées être employées de Statistique Canada. Les chercheurs auront accès aux fichiers de projet anonymisés conformément aux procédures normalisées de Statistique Canada pour les personnes réputées être employées accédant aux fichiers dans les centres de données de recherche de Statistique Canada. Les résultats du projet seront rendus publics dans le cadre de l’initiative Anti-Racism Data Act (ARDA) du gouvernement de la Colombie-Britannique.
Couplage des données du programme de défis d’Impact Canada à celles de la Base de données canadienne sur la dynamique employeurs-employés pour évaluer l’incidence du fait de gagner un défi sur le rendement des entreprises (025-2024)
Objet : Ce projet a pour but de réaliser une évaluation quantitative de l’incidence du programme de défis d’Impact Canada. Plus précisément, le projet vise à comparer les résultats des entreprises qui se sont classées au premier rang lors d’un défi avec les résultats d’entreprises semblables qui n’ont pas participé au défi ou qui ne sont pas arrivées au premier rang. L’objectif ultime est d’examiner le lien entre la participation à un défi et les résultats des entreprises en matière d’innovation et de rendement. Les résultats seront utilisés pour améliorer le programme de défis continu d’Impact Canada, notamment en apportant des changements pertinents aux défis futurs et en les adaptant afin de mieux soutenir les entreprises participantes à l’avenir.
Produit : Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. La diffusion des produits ayant fait l’objet d’un contrôle sera effectuée par le personnel de Statistique Canada. Les renseignements seront présentés dans des tableaux de résultats de régression et de statistiques sommaires associés à l’objectif du projet. Le fichier analytique anonymisé sera rendu accessible à partir des points d’accès sécurisé de Statistique Canada (comme les centres de données de recherche) et l’accès sera accordé aux personnes réputées être employées de Statistique Canada selon le processus d’approbation normalisé. Les clients devront également devenir des personnes réputées être employées de Statistique Canada pour accéder aux données à partir d’un point d’accès sécurisé approuvé.
Combler l’écart : analyse des incidences du capital de risque pour les entreprises canadiennes en démarrage (027-2024)
Objet : Ce projet a pour objectif d’étudier le rôle de la BDC (Banque de développement du Canada) Capital dans l’écosystème des entreprises en démarrage. Il permettra à Innovation, Sciences et Développement économique Canada (ISDE) de mieux comprendre le paysage du financement des entreprises en démarrage en tirant parti de la fonction unique de la BDC dans l’écosystème des entreprises du Canada. Plus précisément, le projet permettra d’étudier les effets de l’appui de la BDC Capital sur le rendement des entreprises en comparant la croissance, l’innovation et la compétitivité des entreprises soutenues par la BDC à celles qui reçoivent du capital d’autres sources, ce qui mettra en évidence les contributions uniques de la BDC Capital à la réussite des petites et moyennes entreprises.
Pour lancer ce projet, ISDE fournira des données sur les clients de la BDC Capital ainsi que des renseignements complémentaires provenant de sources de capital de risque privées et de programmes gouvernementaux afin de les coupler au Registre des entreprises et au Fichier de microdonnées longitudinales des comptes nationaux de Statistique Canada. Les données couplées ainsi obtenues serviront à comparer les résultats des entreprises soutenues par la BDC Capital à un échantillon similaire d’entreprises.
Produit : Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. Les renseignements seront présentés sous la forme de tableaux de résultats de régression et de statistiques sommaires. Le fichier analytique anonymisé sera mis à la disposition des personnes réputées être employées de Statistique Canada au Centre fédéral de données de recherche de Statistique Canada.
Couplage des données de la Base de données canadienne sur la dynamique employeurs-employés à celles de la Déclaration pays par pays aux fins d’analyse des salaires, de la productivité et du transfert de bénéfices des entreprises multinationales canadiennes (028-2024)
Objet : Ce projet vise à évaluer la mesure dans laquelle les entreprises multinationales (EMN) canadiennes pratiquent le transfert de bénéfices et l’incidence de celui-ci sur les salaires, la productivité et l’inégalité des revenus. À l’aide du couplage des données de la Base de données canadienne sur la dynamique employeurs-employés à celles de la Déclaration pays par pays de 2016 à 2022, cette étude examinera ce qui suit :
Qu’advient-il du revenu des EMN canadiennes qui n’est pas dépensé en impôts?
Le salaire des travailleurs est-il plus élevé dans les EMN qui pratiquent le transfert de bénéfices?
En quoi le transfert de bénéfices est-il lié à l’inégalité des salaires? Les augmentations salariales des travailleurs hautement qualifiés occupant des professions à revenu élevé sont-elles plus importantes que celles des travailleurs peu qualifiés travaillant dans des EMN qui pratiquent le transfert de bénéfices?
Les travailleurs dans les EMN qui pratiquent le transfert de bénéfices sont-ils plus productifs?
Les EMN qui pratiquent le transfert de bénéfices sont-elles plus productives que d’autres sociétés semblables au Canada?
Produit : Les données couplées serviront à rédiger un article de recherche comprenant une description de la méthodologie, des tableaux sommaires non confidentiels et des totalisations non confidentielles des résultats d’estimations. Cet article paraîtra dans des publications externes (revues scientifiques) et dans des publications internes de Statistique Canada. Il sera aussi présenté lors de conférences et possiblement à d’autres organismes du gouvernement fédéral. Les mesures de sécurité prises pour protéger les clés de couplage, les identificateurs et le fichier d’analyse couplé seront conformes aux politiques et normes de Statistique Canada. Tous les identificateurs directs d’entreprises et de particuliers seront retirés du fichier d’analyse une fois le couplage terminé.
Déterminer la taille des fournisseurs du gouvernement du Canada afin de produire des estimations du montant des achats effectués par les petites et moyennes entreprises, selon la taille du contrat et le ministère ou l’organisme, pour les exercices financiers 2021 à 2024. (029-2024)
Objet : L’objectif du couplage de microdonnées est de déterminer la taille des fournisseurs du gouvernement du Canada. Il est essentiel de connaître la taille des fournisseurs pour prendre des décisions fondées sur des données probantes dans le contexte d’une proposition budgétaire visant à cibler un certain niveau d’approvisionnement auprès des PME, dont l’inclusion est envisagée dans l’Énoncé économique de l’automne 2024.
Produit : Les tableaux agrégés sont produits pour le compte d’Innovation, Sciences et Développement économique Canada (ISDE) et seront diffusés au public une fois que les règles de confidentialité de StatCan auront été appliquées.
Les résultats du couplage de microdonnées seront disponibles à partir des points d’accès sécurisés de Statistique Canada (tels que les centres de données de recherche) et l’accès sera accordé seulement aux personnes réputées être employées de Statistique Canada conformément au processus d’approbation standard.
ISDE a demandé que les résultats du couplage de microdonnées soient accessibles dans le Centre fédéral de données de recherche (CFDR).
Insécurité alimentaire et revenu utilisant l’Enquête canadienne sur le revenu (ECR) et les Fichiers des familles T1 (FFT1) (030-2024)
Objet : L’objet du présent projet est de mieux comprendre ce qui explique la prévalence persistante et croissante de l’insécurité alimentaire malgré une baisse du taux de pauvreté, afin d’éclairer l’élaboration de réponses stratégiques efficaces pour réduire l’insécurité alimentaire au sein des ménages. Le présent projet vise à déterminer la mesure dans laquelle la mauvaise harmonisation des taux de pauvreté et d’insécurité alimentaire se manifeste dans le cadre d’une exploration détaillée des différentes périodes de référence pour la mesure de l’insécurité alimentaire des ménages et des revenus dans le cadre de l’ECR, ainsi que la présence des actifs et des dettes des ménages. Il vise également à déterminer la contribution des expériences récentes de chocs de revenu négatifs des ménages à leur probabilité actuelle d’insécurité alimentaire et à déterminer les principaux facteurs de ces chocs pour éclairer les interventions stratégiques publiques.
Dans le cadre de ce projet de recouvrement des coûts, Statistique Canada couplera l’ECR à un sous-ensemble de variables du Fichier des familles T1. L’accès à l’ensemble de données fusionné se fera par l’entremise des CDR pour les employés du programme de recherche PROOF de l’Université de Toronto. Seuls les tableaux vérifiés sans renseignement identifiable seront transférés aux chercheurs.
Produit : Les fichiers analytiques définitifs liés sans identifiants personnels seront mis à disposition dans les points d’accès sécurisés de Statistique Canada. L’accès ne sera accordé qu’aux chercheurs, après que le processus d’approbation normalisé a suivi son cours. Des rapports de recherche et des présentations seront générés à partir des fichiers d’analyse. Seuls les statistiques et tableaux agrégés non confidentiels conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique et à toute exigence applicable de la Loi sur la protection des renseignements personnels seront diffusés à l’extérieur de Statistique Canada.
Évaluation de l’incidence de la Prestation canadienne d’urgence sur la crise des surdoses d’opioïdes. (032-2024)
Objet : L’objectif de ce projet est d’évaluer l’incidence de la Prestation canadienne d’urgence (PCU) comme facteur possible de la hausse du nombre de surdoses d’opioïdes pendant la pandémie de COVID-19. Les chercheurs étudieront l’hypothèse selon laquelle l’augmentation temporaire et inattendue des liquidités fournies par la PCU pourrait avoir eu une incidence négative sur un segment vulnérable de la population présentant des antécédents de prescription d’opioïdes ou de maladies mentales, ce qui aurait entraîné une hausse de la consommation d’opioïdes ou de la dépendance à ceux-ci.
L’étude comprendra le nouveau couplage de l’Enquête sur la santé dans les collectivités canadiennes (ESCC) avec la PCU et le Profil vectoriel de l’assurance-emploi.
Produit : Seules des données agrégées conformes aux dispositions en matière de confidentialité de la Loi sur la statistique seront diffusées à l’extérieur de Statistique Canada. Les ensembles de données analytiques seront placés dans les centres de données de recherche (CDR) et l’accès à ces ensembles sera accordé conformément au processus d’approbation normalisé des CDR. Les ensembles de données sources seront anonymisés et conformes aux restrictions relatives aux variables en vigueur pour les ensembles de données sources. Les principaux résultats serviront à rédiger des rapports de recherche, aux fins de publication dans des revues évaluées par des pairs, ainsi qu’à préparer des présentations pour des ateliers et des conférences.
Ensemble de données sur la mortalité de la population relevant des services correctionnels : couplage de microdonnées de la Base canadienne de données des coroners et des médecins légistes (BCDCML) avec celles de l’Enquête sur les services correctionnels canadiens (ESCC) et celles de la Base canadienne de données sur l’état civil — Décès (BCDECD) (001-2025)
Objet : L’objectif principal de l’ensemble de données sur la mortalité de la population relevant des services correctionnels est de fournir aux chercheurs universitaires et aux analystes des politiques gouvernementales des renseignements supplémentaires sur les personnes qui sont décédées durant ou après une période de surveillance correctionnelle. En s’appuyant sur les données de la Base canadienne de données des coroners et des médecins légistes (BCDCML), de l’Enquête sur les services correctionnels canadiens (ESCC) et de la Base canadienne de données sur l’état civil — Décès (BCDECD), on sera en mesure de recueillir des renseignements supplémentaires sur ces décès non naturels et les circonstances qui les entourent. Il s’agit notamment des décès attribuables aux accidents, aux lésions auto-infligées, aux surdoses accidentelles de drogues et aux homicides. Cette étude permettra de combler d’importantes lacunes statistiques concernant cette population très vulnérable.
Produit : Seuls les tableaux agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité prévues par la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. Le fichier analytique, sans identificateurs personnels, sera accessible dans les points d’accès sécurisés de Statistique Canada, et l’accès ne sera accordé qu’aux personnes réputées être employées par Statistique Canada selon le processus d’approbation normalisé de l’organisme.
La productivité des entreprises soutenues par Investissement Québec. (002-2025)
Objet : Le projet a pour objectif d'examiner les tendances de la productivité du travail des entreprises soutenues par l'initiative Productivité innovation d'Investissement Québec. Comme Investissement Québec ne recueille pas de renseignements sur la productivité du travail des entreprises, il fournira la liste des entreprises qu’il soutient à Statistique Canada, qui les couplera au Registre des entreprises, puis au Fichier de microdonnées longitudinales des comptes nationaux. Cette base de données contient les caractéristiques financières des entreprises, ce qui permet de calculer les mesures de la productivité.
Produit : Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. Les résultats seront présentés sous la forme de tableaux indiquant les tendances de la productivité des entreprises au fil des années et selon les secteurs d'activité, en dollars courants et constants, de 2015 à l'année la plus récente pour laquelle des données sont disponibles.
Couplage des données du Recensement de la population avec celles de l’Enquête intégrée sur les tribunaux de juridiction criminelle (EITJC) et de l’Enquête sur les services correctionnels canadiens (ESCC) pour explorer les caractéristiques des personnes qui entrent en contact avec le système de justice pénale par rapport à celles qui n’entrent pas en contact avec lui. (004-2025)
Objet : L’objectif de ce projet est d’examiner la mesure dans laquelle les différences en matière de possibilités et de circonstances socioéconomiques peuvent expliquer les différences entre les groupes sur le plan des contacts avec le système de justice pénale. Le projet portera plus particulièrement sur les groupes qui sont surreprésentés dans le système de justice pénale.
Produit : Les fichiers analytiques et les clés de couplage, sans identificateurs, seront accessibles dans les centres de données de recherche de Statistique Canada. L’accès ne sera accordé qu’aux personnes réputées être employées de Statistique Canada selon le processus d’approbation normalisé. Statistique Canada pourrait également utiliser des fichiers analytiques couplés et des clés de couplage anonymisées pour produire des tableaux statistiques de données agrégées non confidentielles et des rapports analytiques, comme des rapports qui paraîtront dans Juristat, la publication phare de Statistique Canada sur la justice et la sécurité publique.
Examen des différences entre les chiffres de population de Statistique Canada et les méthodes d’échantillonnage déterminées par les répondants en collaboration avec la communauté de Notre santé compte afin de dénombrer les populations des Premières Nations, des Métis et des Inuit à Thunder Bay et à Kenora. (005-2025)
Objet : Les projets de Notre santé compte (NSC) sont menés par des spécialistes de la santé autochtone en collaboration avec des prestataires de services de santé autochtones locaux. Ils ont permis de produire des estimations du nombre de membres des Premières Nations, des Métis et des Inuit vivant dans plusieurs zones urbaines, dont London, Kenora, Ottawa, Thunder Bay et Toronto. Ces estimations démographiques sont plus élevées que les chiffres correspondants du Recensement de 2016, qui a eu lieu le 10 mai 2016. Ce projet collaboratif entre NSC et Statistique Canada permettra d’étudier les différences afin d’améliorer le dénombrement des membres des Premières Nations, des Métis et des Inuit vivant en milieu urbain et dans les territoires connexes.
Le projet consistera à coupler les données de NSC sur les membres des Premières Nations, les Métis et les Inuit vivant à Thunder Bay et à Kenora avec les fonds de données de Statistique Canada, notamment les données du Recensement de la population de 2016 et du Dépôt d’enregistrements dérivés (Environnement de couplage des données sociales). Tous les aspects du projet seront établis conjointement, y compris la sélection des fonds de données pertinents qui seront couplés aux données de NSC, les méthodes d’analyse appropriées et la diffusion des résultats. Les données de NSC seront fournies par les administrateurs légaux des ensembles de données de NSC, Anishnawbe Mushkiki (NSC de Thunder Bay) et Waasegiizhig Nanaandawe’iyewigamig (NSC de Kenora). Les répondants à l’enquête ont été invités à consentir à ce que leurs données soient couplées à celles du recensement. Seules les données des personnes qui ont donné leur accord seront couplées. À la fin du projet, Statistique Canada détruira les ensembles de données couplées ainsi que les données originales de NSC.
Produit : Les résultats comprendront la proportion de répondants de NSC dont les données ont été couplées au Recensement de 2016 et à d’autres ensembles de données, ainsi qu’une description des caractéristiques démographiques (c.-à-d. l’âge, le genre et la géographie) des répondants dont les données n’ont pas été couplées avec succès. L’état du dénombrement du recensement sera également comparé avec les renseignements sur la participation au recensement autodéclarés dans le cadre de l’étude de NSC. Seules les estimations agrégées ayant fait l’objet d’un contrôle de divulgation seront diffusées.
Les entreprises des sciences de la vie (006-2025)
Objet : L'objectif de ce projet est de fournir un profil de l'industrie des sciences de la vie à Santé Canada pour lui permettre de comprendre l'environnement économique de l'industrie et d'évaluer les incidences possibles de la mise en œuvre de nouvelles réglementations. Santé Canada fournira une liste de noms d'entreprises considérées comme faisant partie de la sous-classe des dispositifs médicaux de l’industrie des sciences de la vie, qui sera couplée au Registre des entreprises, puis au Fichier de microdonnées longitudinales des comptes nationaux. Cette base de données sera utilisée pour la production de statistiques agrégées sur les revenus et l'emploi.
Produit : Seuls les analyses et les produits statistiques agrégés non confidentiels et conformes aux dispositions relatives à la confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada. Les résultats seront présentés sous la forme d’un tableau de bord indiquant des statistiques agrégées sur l’emploi et les revenus de l’industrie. Ce tableau de bord sera fourni à Santé Canada et ne sera accessible qu'aux membres approuvés du Bureau de la modernisation des lois et des règlements (BMLR).
Projet de couplage des microdonnées du Programme de placement et de surveillance dans le cadre d’un programme intensif de réadaptation (PSPIR) avec les données sur la justice pénale, la santé et l’éducation, les données du recensement et les données fiscales (007-2025)
Objet : Le Programme de placement et de surveillance dans le cadre d’un programme intensif de réadaptation (PSPIR) du gouvernement fédéral est un programme de contribution auquel participent toutes les provinces et tous les territoires pour la prestation de programmes et de services thérapeutiques spécialisés aux jeunes ayant des besoins en santé mentale qui sont reconnus coupables d’une infraction grave avec violence. Le Programme de PSPIR est une composante importante de la surveillance correctionnelle des jeunes au Canada. Le principal objectif de ce projet est d’offrir des possibilités de couplage pour déterminer les nouveaux contacts avec le système de justice pénale et d’autres résultats pour la population participant au Programme de PSPIR. Les renseignements sommaires sur les résultats affichés par les jeunes après avoir participé au Programme de PSPIR et, le cas échéant, les comparaisons avec les résultats de cohortes de non-participants constituent depuis de nombreuses années une lacune importante dans les données qui permettraient d’évaluer la réussite du Programme de PSPIR. En collaboration avec les programmes correctionnels pour les jeunes participants et le ministère de la Justice, Statistique Canada vise à combler cette lacune dans son programme statistique sur les services correctionnels pour les jeunes en intégrant les données du Programme de PSPIR à d’autres données sociales, pour comprendre l’incidence du Programme de PSPIR. Les partenaires et les intervenants en matière de justice ainsi que le public canadien profiteront des résultats compilés, car les renseignements contribuent à la création de politiques et de programmes fondés sur des données probantes et, par le fait même, à l’intérêt public. Ces données aident à répondre au besoin d’éclairer les approches fondées sur des données probantes en matière de prévention de la criminalité et de programmes de lutte contre la criminalité visant à réduire la récidive, ainsi que les programmes conçus pour la réadaptation, l’intégration communautaire et la sécurité publique.
Produit : Statistique Canada effectuera le couplage d’enregistrements de ces données en vertu du cadre établi de gouvernance et de protection des renseignements personnels, afin d’élaborer des ensembles de données analytiques pour déterminer les résultats sociaux des jeunes après leur participation au Programme de PSPIR. Les résultats, l’interprétation et les conclusions de l’analyse au moyen des données couplées concerneront les participants couplés et ne seront pas généralisés à la population totale du Programme de PSPIR. Un rapport sur les agrégats statistiques sera mis à la disposition des employés du ministère de la Justice qui participent au projet de PSPIR. Seuls les tableaux agrégés non confidentiels conformes aux dispositions en matière de confidentialité de la Loi sur la statistique seront diffusés à l’extérieur de Statistique Canada.
Couplage des données de l’Enquête canadienne sur la santé buccodentaire (ECSB) et du Régime canadien de soins dentaires (RCSD) aux variables sociodémographiques et socioéconomiques ainsi qu’aux résultats en matière de santé (008-2025)
Objet : Le projet vise à améliorer la compréhension de la santé buccodentaire, des facteurs de risque et de la couverture de l’assurance des Canadiennes et Canadiens dans le but d’éclairer l’élaboration de politiques et de surveiller les tendances en matière de santé buccodentaire au fil du temps. Il soutient le Régime canadien de soins dentaires (RCSD) lancé par Santé Canada en décembre 2023 en fournissant des données essentielles à l’amélioration des services de soins dentaires à l’échelle du pays. Les résultats aideront à déployer et à évaluer efficacement le RCSD, à assurer un accès équitable aux soins dentaires et à remédier aux disparités régionales et socioéconomiques, ce qui, au bout du compte, servira l’intérêt public.
Produit : Les fichiers analytiques (sans identificateurs) seront accessibles à partir des points d’accès sécurisés de Statistique Canada, comme le Centre fédéral de données de recherche (CFDR) et le réseau des centres de données de recherche (CDR). L’accès sera uniquement accordé aux employés de Statistique Canada (y compris les personnes réputées être employées de Statistique Canada) dont le travail l’exige et il sera accordé selon le processus d’approbation normalisé.
Couplage de microdonnées pour la création d’une base de sondage au niveau personne pour les enquêtes sociales (009-2025)
Objectif : Ce projet de couplage vise à produire de l’information au niveau des personnes plutôt qu’au niveau des logements, afin de soutenir l’échantillonnage des enquêtes sociales ciblant les individus. L’utilisation de couplage de microdonnées permet d’obtenir de l’information plus détaillée et de meilleure qualité pour les petites collectivités et populations, tout en permettant des gains de temps et d’argent. Cela garantit également que les enquêtes sociales menées au niveau des personnes demeurent exactes, pertinentes et efficaces en termes de coûts.
Produit : Les données issues de ces couplages sont intégrées pour produire des bases de sondage destinées aux enquêtes sociales. Aucune information statistique issue de ces couplages ne sera diffusée.
Découvrez le potentiel des données sur la santé de Statistique Canada
Le Programme de la statistique sur la santé de Statistique Canada est heureux de lancer une nouvelle série de webinaires conçue pour les utilisateurs de données sur la santé. Ces séances d’une heure, offertes tous les deux ou trois mois, seront adaptées à vos besoins et à vos intérêts selon vos commentaires.
Prochaine séance
Date : 21 novembre 2025 Séance en français : 11 h (HNE) Séance en anglais : 13 h (HNE) Inscrivez-vous dès maintenant : Remplissez le formulaire d’inscription pour réserver votre place.
Cette première séance de la série est conçue pour vous aider à tirer pleinement parti des vastes et variées données sur la santé de Statistique Canada.
Ce que vous apprendrez
Découvrez la grande variété de sources de données, notamment :
les données d’enquêtes
les données administratives
les échantillons biologiques
les données couplées
Comprenez les différentes façons d’accéder aux données :
portails de données ouvertes
environnements sécurisés
services de données personnalisés
Apprenez-en davantage sur les outils et améliorations permettant d’affiner les données selon vos besoins de recherche.
Présentateurs
Sylvain Tremblay, directeur, Centre d’intégration des données de santé et de mesures directes (séance en français)
Steve Trites, directeur, Centre des données sur la santé des populations (séance en anglais)
À qui s’adresse ce webinaire?
Chercheurs, analystes, décideurs politiques et professionnels de la santé qui souhaitent tirer parti des données de santé de Statistique Canada pour mener des recherches et prendre des décisions éclairées.
À Statistique Canada, le Centre de l’intégration des données sur la santé et des mesures directes (CIDSMD) est responsable de la production de statistiques sur les indicateurs de la santé qui requièrent une mesure directe de la santé physique à l’échelle de la population dans plusieurs domaines, tels que les maladies chroniques, la santé buccodentaire, les maladies infectieuses et les contaminants environnementaux. Alors que le CIDSMD envisage l’avenir de ses programmes, il va par exemple revoir et mettre à jour les plans d’enquête, les infrastructures de collecte, le contenu des enquêtes et les plans analytiques.
Statistique Canada s’est engagé à fournir des données de qualité. Dans le cadre des programmes de mesures directes de la santé, le CIDSMD a lancé une série de séances de consultation auprès des principales parties prenantes, comme les entités gouvernementales du domaine de la santé, les organisations pancanadiennes, les coordonnateurs statistiques provinciaux et territoriaux, les chercheurs universitaires et les organisations non gouvernementales.
Les commentaires recueillis aideront Statistique Canada à prévoir le développement des programmes déjà en place, comme l’Enquête canadienne sur les mesures de la santé, ainsi qu’à concevoir et à mettre en œuvre de nouveaux programmes afin de répondre aux besoins des parties prenantes. L’objectif de ces consultations était de déterminer les besoins et les lacunes en matière de données, de faire connaître les fonds de données de Statistique Canada, de mettre à profit l’expertise spécialisée des différentes parties et d’explorer les possibilités de collaboration.
Méthodes de mobilisation consultative
Les consultations sur les programmes de mesures directes de la santé ont été menées sous la forme de séances d’information virtuelles, lesquelles comprenaient des discussions de groupe avec un large éventail de parties prenantes dans le domaine des mesures directes de la santé. Ainsi, ce sont 58 organisations différentes qui ont pu formuler leurs commentaires, dont des organisations non gouvernementales, des organisations gouvernementales et des organismes de recherche. Ces séances ont eu lieu en février 2025 et leur tenue a été annoncée sur le site Web de Statistique Canada à la page Consultation des Canadiens. Par ailleurs, les différentes parties ont été personnellement invitées par courriel à participer aux séances et à transmettre l’invitation aux membres de leur réseau. En plus de prendre part aux séances en mode virtuel, les participants ont eu la possibilité de nous communiquer leurs commentaires au moyen d’un formulaire électronique ou par écrit. Dans l’ensemble, Statistique Canada a animé 16 séances de consultation dans les deux langues officielles et a recueilli des commentaires auprès de 98 personnes représentant 58 organisations des secteurs public et privé.
Ce que nous ont dit les parties prenantes
Les consultations ont fait ressortir une volonté des participants de conclure des ententes de collaboration officielles avec Statistique Canada, qui définiraient clairement les rôles, les responsabilités et les attentes de chacun.
Les participants ont souligné l’importance des données de Statistique Canada pour leurs travaux. Ils ont néanmoins indiqué que l’accès aux données et la rapidité de leur diffusion étaient des points pouvant être améliorés. Selon les commentaires recueillis, les sources de données des mesures directes les plus utilisées étaient les mesures d’accéléromètre (données sur l’activité physique), les mesures anthropométriques, les biomarqueurs, les données sur les maladies et l’état de santé, les renseignements sociodémographiques, et les données sur l’intoxication aux drogues et la consommation de substances ainsi que sur l’exposition aux substances chimiques. Les participants ont également indiqué avoir besoin de données supplémentaires en ce qui concerne la santé environnementale, la nutrition, les biomarqueurs, les covariables, des domaines spécialisés de la santé et les mesures physiques. Les consultations ont permis de confirmer que l’utilisation d’enquêtes transversales menées auprès de la population et représentatives à l’échelle nationale suffit pour répondre aux besoins actuels en matière de données. Toutefois, les participants ont également confirmé le besoin d’une désagrégation plus fine des données géographiques et des données des variables. Les lacunes statistiques actuelles concernent entre autres les données relatives aux trois territoires ainsi que les données longitudinales, étant donné qu’il n’existe aucune source de données longitudinales des mesures directes de la santé dans l’entrepôt de données de Statistique Canada.
Statistique Canada tient à remercier toutes les personnes qui ont participé à cette initiative de mobilisation consultative et qui ont fourni des commentaires. Nous continuerons à collaborer avec certaines parties sur des enquêtes et des sujets précis afin de répondre aux commentaires reçus lors des séances de consultation.
Le Plan d'action sur les données désagrégées (PADD), établi dans le cadre du budget de 2021, consiste en une approche pangouvernementale que dirige Statistique Canada pour recueillir, analyser et diffuser des données désagrégées concernant les quatre groupes visés par l'équité en matière d'emploi (EE) : les femmes, les Autochtones, les populations racisées et les personnes ayant une incapacité. De plus, dans les cas où il est pertinent et possible de le faire, le plan couvre des niveaux géographiques inférieurs et d'autres groupes en quête d'équité et de droits (p. ex. les personnes bispirituelles, lesbiennes, gaies, bisexuelles, transgenres, queers et intersexes ainsi que celles qui emploient d'autres termes relatifs à la diversité sexuelle ou de genre [population 2ELGBTQI+]; les immigrants; les populations à faible revenu; les enfants; les aînés). Le PADD a pour objet de soutenir les efforts déployés par les administrations publiques et la société visant à éliminer les inégalités connues en intégrant des considérations d'équité et d'inclusion dans la prise de décisions. Le budget de 2021 prévoyait l'affectation de 172 millions de dollars à l'appui des cinq premières années du PADD. Une autre somme de 36,3 millions de dollars a été affectée au soutien d'activités connexes en cours.
La structure de gouvernance du PADD était formée d'organismes de gouvernance interministériels et au niveau de l'organisme. À Statistique Canada, le Comité directeur des statisticiens en chef adjoints et statisticiennes en chef adjointes (SCA) est appuyé par le Comité de gouvernance des directeurs généraux et directrices générales et ses groupes de travail. Les organismes externes comprennent le Comité consultatif fédéral des sous-ministres adjoints sur les données désagrégées et le Comité consultatif fédéral sur la désagrégation des statistiques sur la justice et la sécurité des collectivités. Le soutien administratif et logistique est assuré par le Secrétariat du PADD.
Le PADD devrait contribuer à bâtir un Canada plus équitable en favorisant une collecte de données plus représentative, en améliorant les statistiques sur les divers groupes de populations, en luttant contre le racisme systémique et la discrimination fondée sur le genre et en intégrant l'équité et l'inclusion dans les processus de prise de décisions en vue de produire les effets escomptés. Le PADD comportait divers projets destinés à rehausser la capacité de l'organisme à désagréger les données. De plus, les dirigeants de l'organisme ont favorisé un changement culturel vers la priorisation des données et des analyses désagrégées. Bien que la plus grande partie (66 %) du financement ait été affectée au Secteur de la statistique sociale, de la santé et du travail (secteur 8), presque tous les secteurs ont bénéficié des initiatives du PADD.
Depuis sa création, le PADD a appuyé un éventail de projets et d'activités au moyen d'un financement de base et d'appels de demandes ciblés. Au total, 10 projets ayant fait l'objet d'un financement de base ont constitué l'assise de l'engagement du PADD. Ils ont reçu un financement continu au cours de plusieurs exercices financiers ou jusqu'à leur achèvement. Les projets financés dans le cadre du processus d'appel de demandes ont été choisis en fonction de critères harmonisés avec les objectifs du PADD et devaient servir à appuyer des travaux préliminaires ou en cours. Jusqu'en 2024-2025, le PADD avait subventionné 74 projets et activités. Au moment où l'initiative entame la dernière année de son financement sur cinq ans, les 172 millions de dollars ont été entièrement attribués.
L'objectif de cette évaluation est de fournir des renseignements crédibles et impartiaux sur la pertinence, la conception, l'exécution et le rendement du PADD. L'évaluation a porté sur la conception et l'exécution du PADD, y compris sa structure de gouvernance; la viabilité des nouvelles activités s'inscrivant dans les opérations courantes de l'organisme; enfin, la progression vers les résultats escomptés à court, à moyen et à long terme.
Principales constatations et recommandations
Le PADD contribue à répondre aux besoins d'information du Canada et s'harmonise avec les priorités pangouvernementales, ainsi qu'avec les priorités stratégiques et les responsabilités essentielles de Statistique Canada. Les projets et les activités du PADD sont conformes aux priorités et aux besoins en matière de données qui ont été énoncés dans les récents budgets, stratégies et rapports du gouvernement fédéral. Ils cadrent aussi avec les priorités globales de l'organisme qui sont décrites dans les lettres de mandat et les documents stratégiques et qui visent des données plus désagrégées, des méthodes de pointe et l'intégration des données.
La structure et les mécanismes de gouvernance du PADD facilitent la surveillance à l'échelle du gouvernement fédéral et de l'organisme, mais ils sont principalement axés sur la surveillance de la mise en œuvre plutôt que le suivi des progrès accomplis vers l'obtention des résultats escomptés. Bien que la structure de gouvernance comporte certains éléments de reddition de comptes, il reste des lacunes, et l'emphase sur la mise en œuvre plutôt que l'orientation stratégique limite sa capacité à faciliter l'atteinte des résultats à moyen et à long terme.
Des efforts de consultation ont aidé à orienter un certain nombre de priorités et de projets du PADD; toutefois, il subsiste des préoccupations selon lesquelles certains produits de données désagrégées sont diffusés sans consultation suffisante, ce qui risque de renforcer un message d'inadéquation. Bien que les activités du PADD aient pris appui sur l'infrastructure, les ressources et les capacités existantes et les aient améliorées dans certains cas, les initiatives qui dépendent d'un suréchantillonnage ne sont pas viables. Les efforts visant à soutenir les nouvelles activités financées par le PADD en les intégrant aux opérations courantes de l'organisme ont été limités. Des ententes de recouvrement des coûts pourraient être utiles, mais le climat financier actuel limite cette option.
Bien que le PADD progresse vers les résultats escomptés, certains aspects nécessitent une attention plus poussée. Les activités de sensibilisation et de formation ont aidé les participants à mieux comprendre la désagrégation des données, mais certains obstacles à l'application et à l'acquisition de connaissances sur les données désagrégées ont été relevés. Le PADD contribue à combler les lacunes en matière d'information, mais il n'est pas jugé viable de dépendre du suréchantillonnage pour produire des données désagrégées à partir d'enquêtes phares. Le plan d'action améliore certains aspects de la qualité des données, mais certains problèmes liés à la pertinence et à l'accessibilité persistent.
Le PADD favorise et renforce un changement culturel où l'on accorde la priorité aux données désagrégées et à l'analyse intersectionnelle en élargissant l'offre de données désagrégées et de produits connexes. Cependant, pour continuer de progresser, il faudra insister davantage sur la sensibilisation et la formation. Certains éléments probants préliminaires semblent indiquer que le PADD a une incidence positive sur les utilisateurs de données, mais ces effets sont en partie limités par la capacité des utilisateurs de données et des décideurs à comprendre et à utiliser les données désagrégées et les produits analytiques connexes. On note également une certaine préoccupation quant au fait que le résultat à long terme du PADD échappe à l'influence et au mandat de Statistique Canada.
À la lumière de ces constatations, les recommandations suivantes sont proposées.
Recommandation 1
Le SCA du secteur 8 devrait veiller à renforcer la gouvernance du PADD afin de contribuer directement à l'obtention des résultats intermédiaires et finals de l'initiative au moyen des mesures suivantes :
mettre à jour le mandat des comités de surveillance du PADD afin d'énoncer clairement les responsabilités, surtout en ce qui concerne l'orientation stratégique à donner et l'atteinte des objectifs à moyen et à long terme du PADD;
axer les activités et les projets futurs sur la viabilité;
établir une communication efficace (p. ex. tirer parti des tables de gouvernance proposées) pour veiller à ce que les priorités, les mesures du rendement et les résultats attendus soient bien compris par le personnel, les principaux partenaires et les parties prenantes (p. ex. de façon régulière, au moyen d'un véritable dialogue).
Recommandation 2
Le SCA du secteur 8 devrait veiller à ce que les efforts de sensibilisation et de mobilisation soient exhaustifs et constants, afin que les besoins continus des utilisateurs de données, y compris ceux des groupes visés par l'EE, soient compris et qu'ils soient comblés par les données désagrégées et les produits analytiques connexes du PADD.
Le Plan d'action sur les données désagrégées (PADD), établi dans le cadre du budget de 2021, consiste en une approche pangouvernementale que dirige Statistique Canada pour recueillir, analyser et diffuser des données désagrégées concernant les quatre groupes visés par l'équité en matière d'emploi (EE) : les femmes, les Autochtones, les populations racisées et les personnes ayant une incapacité. De plus, dans les cas où il est pertinent et possible de le faire, le plan couvre des niveaux géographiques inférieurs et d'autres groupes en quête d'équité et de droits (p. ex. les personnes bispirituelles, lesbiennes, gaies, bisexuelles, transgenres, queers et intersexes ainsi que celles qui emploient d'autres termes relatifs à la diversité sexuelle ou de genre [population 2ELGBTQI+]; les immigrants; les populations à faible revenu; les enfants; les aînés). Le PADD a pour objet de soutenir les efforts déployés par les administrations publiques et la société visant à éliminer les inégalités connues en intégrant des considérations d'équité et d'inclusion dans la prise de décisions. Le budget de 2021 prévoyait l'affectation de 172 millions de dollars à l'appui des cinq premières années du PADD. Une autre somme de 36,3 millions de dollars a été affectée au soutien d'activités connexes en cours.
La structure de gouvernance du PADD était formée d'organismes de gouvernance interministériels et au niveau de l'organisme. À Statistique Canada, le Comité directeur des statisticiens en chef adjoints et statisticiennes en chef adjointes (SCA) est appuyé par le Comité de gouvernance des directeurs généraux et directrices générales et ses groupes de travail. Les organismes externes comprennent le Comité consultatif fédéral des sous-ministres adjoints sur les données désagrégées et le Comité consultatif fédéral sur la désagrégation des statistiques sur la justice et la sécurité des collectivités. Le soutien administratif et logistique est assuré par le Secrétariat du PADD.
Le PADD devrait contribuer à bâtir un Canada plus équitable en favorisant une collecte de données plus représentative, en améliorant les statistiques sur les divers groupes de populations, en luttant contre le racisme systémique et la discrimination fondée sur le genre et en intégrant l'équité et l'inclusion dans les processus de prise de décisions en vue de produire les effets escomptés. Le PADD comportait divers projets destinés à rehausser la capacité de l'organisme à désagréger les données. De plus, les dirigeants de l'organisme ont favorisé un changement culturel vers la priorisation des données et des analyses désagrégées. Bien que la plus grande partie (66 %) du financement ait été affectée au Secteur de la statistique sociale, de la santé et du travail (secteur 8), presque tous les secteurs ont bénéficié des initiatives du PADD.
Depuis sa création, le PADD a appuyé un éventail de projets et d'activités au moyen d'un financement de base et d'appels de demandes ciblés. Au total, 10 projets ayant fait l'objet d'un financement de base ont constitué l'assise de l'engagement du PADD. Ils ont reçu un financement continu au cours de plusieurs exercices financiers ou jusqu'à leur achèvement. Les projets financés dans le cadre du processus d'appel de demandes ont été choisis en fonction de critères harmonisés avec les objectifs du PADD et devaient servir à appuyer des travaux préliminaires ou en cours. Jusqu'en 2024-2025, le PADD avait subventionné 74 projets et activités. Au moment où l'initiative entame la dernière année de son financement sur cinq ans, les 172 millions de dollars ont été entièrement attribués.
L'objectif de cette évaluation est de fournir des renseignements crédibles et impartiaux sur la pertinence, la conception, l'exécution et le rendement du PADD. L'évaluation a porté sur la conception et l'exécution du PADD, y compris sa structure de gouvernance; la viabilité des nouvelles activités s'inscrivant dans les opérations courantes de l'organisme; enfin, la progression vers les résultats escomptés à court, à moyen et à long terme.
Principales constatations et recommandations
Le PADD contribue à répondre aux besoins d'information du Canada et s'harmonise avec les priorités pangouvernementales, ainsi qu'avec les priorités stratégiques et les responsabilités essentielles de Statistique Canada. Les projets et les activités du PADD sont conformes aux priorités et aux besoins en matière de données qui ont été énoncés dans les récents budgets, stratégies et rapports du gouvernement fédéral. Ils cadrent aussi avec les priorités globales de l'organisme qui sont décrites dans les lettres de mandat et les documents stratégiques et qui visent des données plus désagrégées, des méthodes de pointe et l'intégration des données.
La structure et les mécanismes de gouvernance du PADD facilitent la surveillance à l'échelle du gouvernement fédéral et de l'organisme, mais ils sont principalement axés sur la surveillance de la mise en œuvre plutôt que le suivi des progrès accomplis vers l'obtention des résultats escomptés. Bien que la structure de gouvernance comporte certains éléments de reddition de comptes, il reste des lacunes, et l'emphase sur la mise en œuvre plutôt que l'orientation stratégique limite sa capacité à faciliter l'atteinte des résultats à moyen et à long terme.
Des efforts de consultation ont aidé à orienter un certain nombre de priorités et de projets du PADD; toutefois, il subsiste des préoccupations selon lesquelles certains produits de données désagrégées sont diffusés sans consultation suffisante, ce qui risque de renforcer un message d'inadéquation. Bien que les activités du PADD aient pris appui sur l'infrastructure, les ressources et les capacités existantes et les aient améliorées dans certains cas, les initiatives qui dépendent d'un suréchantillonnage ne sont pas viables. Les efforts visant à soutenir les nouvelles activités financées par le PADD en les intégrant aux opérations courantes de l'organisme ont été limités. Des ententes de recouvrement des coûts pourraient être utiles, mais le climat financier actuel limite cette option.
Bien que le PADD progresse vers les résultats escomptés, certains aspects nécessitent une attention plus poussée. Les activités de sensibilisation et de formation ont aidé les participants à mieux comprendre la désagrégation des données, mais certains obstacles à l'application et à l'acquisition de connaissances sur les données désagrégées ont été relevés. Le PADD contribue à combler les lacunes en matière d'information, mais il n'est pas jugé viable de dépendre du suréchantillonnage pour produire des données désagrégées à partir d'enquêtes phares. Le plan d'action améliore certains aspects de la qualité des données, mais certains problèmes liés à la pertinence et à l'accessibilité persistent.
Le PADD favorise et renforce un changement culturel où l'on accorde la priorité aux données désagrégées et à l'analyse intersectionnelle en élargissant l'offre de données désagrégées et de produits connexes. Cependant, pour continuer de progresser, il faudra insister davantage sur la sensibilisation et la formation. Certains éléments probants préliminaires semblent indiquer que le PADD a une incidence positive sur les utilisateurs de données, mais ces effets sont en partie limités par la capacité des utilisateurs de données et des décideurs à comprendre et à utiliser les données désagrégées et les produits analytiques connexes. On note également une certaine préoccupation quant au fait que le résultat à long terme du PADD échappe à l'influence et au mandat de Statistique Canada.
À la lumière de ces constatations, les recommandations suivantes sont proposées.
Recommandation 1
Le SCA du secteur 8 devrait veiller à renforcer la gouvernance du PADD afin de contribuer directement à l'obtention des résultats intermédiaires et finals de l'initiative au moyen des mesures suivantes :
mettre à jour le mandat des comités de surveillance du PADD afin d'énoncer clairement les responsabilités, surtout en ce qui concerne l'orientation stratégique à donner et l'atteinte des objectifs à moyen et à long terme du PADD;
axer les activités et les projets futurs sur la viabilité;
établir une communication efficace (p. ex. tirer parti des tables de gouvernance proposées) pour veiller à ce que les priorités, les mesures du rendement et les résultats attendus soient bien compris par le personnel, les principaux partenaires et les parties prenantes (p. ex. de façon régulière, au moyen d'un véritable dialogue).
Recommandation 2
Le SCA du secteur 8 devrait veiller à ce que les efforts de sensibilisation et de mobilisation soient exhaustifs et constants, afin que les besoins continus des utilisateurs de données, y compris ceux des groupes visés par l'EE, soient compris et qu'ils soient comblés par les données désagrégées et les produits analytiques connexes du PADD.
Sigles et abréviations
2ELGBTQI+
Personnes aux deux esprits (ou bispirituelles), lesbiennes, gaies, bisexuelles, transgenres, queers et intersexes ainsi que celles qui emploient d'autres termes relatifs à la diversité sexuelle ou de genre
ACS Plus
Analyse comparative entre les sexes Plus
CGS
Comité de gestion stratégique
CNSD
Centre des normes en matière de statistiques et de données
DG
Directeur général
EDI
Équité, diversité et inclusion
EE
Équité en matière d'emploi
EFPC
École de la fonction publique du Canada
GC
Gouvernement du Canada
PADD
Plan d'action sur les données désagrégées
SCA
Statisticien en chef adjoint
Secteur 6
Secteur de la gestion stratégique des données, des méthodes et de l'analyse
Secteur 7
Secteur du recensement, des services régionaux et des opérations
Secteur 8
Secteur de la statistique sociale, de la santé et du travail
SIPEUC
Système d'information sur le personnel d'enseignement dans les universités et les collèges
SMA
Sous-ministre adjoint
Contenu
Contexte
Le mandat de Statistique Canada consiste à produire des données objectives de grande qualité qui aident les Canadiens à mieux comprendre leurs conditions sociales, économiques et environnementales afin d'orienter l'élaboration et l'évaluation des politiques et des programmes publics et d'améliorer la prise de décisions. Toutefois, comme l'a démontré la pandémie de COVID-19, qui a entraîné des réalités sociales et économiques inégales pour divers groupes, les conditions sociales, économiques et environnementales des Canadiens ne sont pas universelles. Pour remédier à ces disparités, il faut des données plus détaillées qui sont ventilées — ou désagrégées — en sous-catégories telles que le genre, les caractéristiques ethnoculturelles, l'âge, l'orientation sexuelle, l'incapacité et la région géographique.
Le Plan d'action sur les données désagrégées (PADD), établi dans le cadre du budget de 2021, consiste en une approche pangouvernementale que dirige Statistique Canada pour recueillir, analyser et diffuser des données désagrégées concernant les quatre groupes visés par l'équité en matière d'emploi (EE) : les femmes, les Autochtones, les populations racisées et les personnes ayant une incapacité. De plus, dans les cas où il est pertinent et possible de le faire, le plan couvre des niveaux géographiques inférieurs et d'autres groupes en quête d'équité et de droits (p. ex. les personnes bispirituelles, lesbiennes, gaies, bisexuelles, transgenres, queers et intersexes et celles qui emploient d'autres termes liés à la diversité sexuelle ou de genre [population 2ELGBTQI+]; les immigrants; les populations à faible revenu; les enfants; les aînés). Le PADD a pour objet de soutenir les efforts mis par les administrations publiques et la société à éliminer les inégalités connues en intégrant des considérations d'équité et d'inclusion dans la prise de décisions. Le budget de 2021 prévoyait l'affectation de 172 millions de dollars à l'appui des cinq premières années du PADD. Une autre somme de 36,3 millions de dollars a été affectée au soutien d'activités connexes en cours.
Le PADD est guidé par les quatre principes suivants :
Il y a lieu de désagréger les données et les analyses au plus fin niveau démographique possible en tenant compte des considérations relatives à l'Analyse comparative entre les sexes Plus (ACS Plus) et en respectant la confidentialité des données et les normes de qualité.
L'analyse doit être axée sur l'intersectionnalité (p. ex. jeunes, Noirs, femmes) plutôt que sur des interactions binaires. Une optique d'ACS Plus doit être appliquée à l'analyse des données.
Les normes approuvées par Statistique Canada doivent être utilisées pour la désagrégation dans l'ensemble des programmes.
Les données doivent être publiées au plus fin niveau géographique possible.
Les activités du PADD sont organisées en cinq piliers décrits au tableau 1.
Tableau 1. Piliers du Plan d'action sur les données désagrégées Note de bas de page 1
Accroissement des actifs de données désagrégées
Enrichissement des perspectives intersectionnelles et longitudinales
Accès à des données désagrégées améliorées
Normes statistiques
Mobilisation et communication améliorées
Fournir de plus amples renseignements sur les populations à divers niveaux géographiques
Faire la lumière sur les inégalités et favoriser l'équité et l'inclusion
Assurer l'accès du public, de tous les ordres de gouvernement et des autres utilisateurs des données
Examiner les normes statistiques, en élaborer et les promouvoir pour permettre la comparaison des données au fil du temps et entre les secteurs de compétence
Mieux représenter l'expérience vécue par les groupes de population et répondre aux besoins des utilisateurs de données
Gouvernance
La structure de gouvernance du PADD était formée d'organismes de gouvernance interministériels et au niveau de l'organisme (voir la figure 1).
Au sein de Statistique Canada, c'est le Comité de gestion stratégique (CGS), son organisme de gouvernance supérieur présidé par le statisticien en chef et composé de statisticiens en chef adjoints (SCA), qui assure l'orientation stratégique générale de l'organisme, y compris du PADD.
Le Comité directeur des SCA prend des décisions de haut niveau et est chargé de coordonner, de faciliter et de surveiller la mise en œuvre du PADD à Statistique Canada. Ce comité est coprésidé par le SCA du Secteur de la statistique sociale, de la santé et du travail (secteur 8) et le SCA du Secteur du recensement, des services régionaux et des opérations (secteur 7).
Le Comité de gouvernance des directeurs généraux et directrices générales (DG) est chargé de recommander des décisions au Comité directeur des SCA et d'appuyer la surveillance des projets du PADD. Le Comité de gouvernance des DG est coprésidé par les DG du Secteur de la gestion stratégique des données, des méthodes et de l'analyse (secteur 6) et du secteur 8.
Au cours des deux premiers exercices financiers du PADD, six groupes de travail au niveau de l'organisme ont été mis sur pied à l'appui des cinq piliers, soit les groupes de travail sur la mobilisation et la communication, les normes en matière de données, l'élaboration et l'acquisition de données, l'accès et la diffusion, les perspectives analytiques, ainsi que l'infrastructure statistique. Ces groupes relevaient du Comité de gouvernance des DG et étaient chargés de formuler des recommandations à l'appui des activités du PADD.
Le Secrétariat du PADD, au Centre de la statistique sociale et de la population du secteur 8, apporte un soutien administratif et logistique aux comités du PADD de l'organisme et de l'extérieur, sauf au CGS.
Le Comité consultatif fédéral des sous-ministres adjoints (SMA) sur les données désagrégées est un comité externe qui conseille Statistique Canada au sujet de la mise en œuvre du PADD et qui est chargé de favoriser la collaboration et la coordination entre les ministères fédéraux, de déterminer les besoins en données et d'y répondre, ainsi que de promouvoir des stratégies de collecte de données désagrégées au niveau des programmes, y compris l'utilisation de normes nationales relatives aux données. Le comité est coprésidé par le SCA du secteur 8 et le secrétaire adjoint du Cabinet, Priorités et Planification et unité des résultats et de la livraison du Bureau du Conseil privé. Il se compose de SMA de l'ensemble du gouvernement fédéral Note de bas de page 2. Quatre groupes de travail interministériels établis en 2023 relevaient du comité des SMA, à savoir les groupes de travail sur la mobilisation et la collaboration, l'accès à des données désagrégées, la protection des renseignements personnels et la confidentialité et, enfin, l'accroissement des actifs de données.
Le Comité consultatif fédéral sur la désagrégation des statistiques sur la justice et la sécurité des collectivités est un comité externe appelé à prodiguer des conseils propres aux projets du PADD liés à la justice.
Figure 1. Structure de gouvernance du Plan d'action sur les données désagrégéesDescription - Figure 1. Structure de gouvernance du Plan d'action sur les données désagrégées
La figure 1 présente un organigramme de la structure de gouvernance du Plan d'action sur les données désagrégées (PADD).
Au sein de Statistique Canada, les comités suivants existent :
Le Comité de gestion stratégique (CGS) est présidé par le statisticien en chef et composé de statisticiens en chef adjoints (SCA).
Le Comité directeur des SCA est coprésidé par le SCA du Secteur de la statistique sociale, de la santé et du travail (secteur 8) et le SCA du Secteur du recensement, des services régionaux et des opérations (secteur 7).
Le Comité de gouvernance des directeurs généraux et directrices générales (DG) est coprésidé par les DG du Secteur de la gestion stratégique des données, des méthodes et de l'analyse (secteur 6) et du secteur 8. Ce comité est appuyé par six groupes de travail, chacun codirigé par les directeurs des secteurs 6 et 7 :
Mobilisation et communication
Normes en matière de données
Élaboration et acquisition de données
Accès et diffusion
Perspectives analytiques
Infrastructure statistique
Le Secrétariat du PADD, situé au sein du secteur 8, apporte un soutien administratif et logistique aux comités du PADD de l'organisme et de l'extérieur, sauf au CGS.
À l'extérieur de Statistique Canada, il existe les deux comités suivants :
Le Comité consultatif fédéral des sous-ministres adjoints (SMA) sur les données désagrégées, un comité externe coprésidé par le SCA du secteur 8.
Le Comité consultatif fédéral externe sur la désagrégation des statistiques de la justice et de la sécurité communautaire, un comité externe coprésidé par le DG du secteur 8.
Résultats attendus
Le PADD devrait contribuer à bâtir un Canada plus équitable en favorisant une collecte de données plus représentative, en bonifiant les statistiques sur les populations d'identités diverses, en luttant contre le racisme systémique et la discrimination fondée sur le genre et en intégrant l'équité et l'inclusion dans les processus de prise de décisions en vue de produire les effets escomptés. Le tableau 2 résume les résultats immédiats, intermédiaires et à long terme attendus du PADD.
Tableau 2. Résultats du Plan d'action sur les données désagrégéesNote de bas de page 3
Échéancier
Résultats
Indicateurs de rendement pertinents
Résultats immédiats (1 à 3 ans)
Connaissance et compréhension accrues du besoin de données désagrégées et de la nécessité de l'Analyse comparative entre les sexes Plus.
Plus grande qualité des données et moins de lacunes en matière d'information.
Accès accru et amélioré à des données désagrégées et à des renseignements statistiques détaillés.
Proportion des indicateurs désagrégés en fonction des groupes visés par l'équité en matière d'emploi (femmes, Autochtones, populations racisées et personnes ayant une incapacité)
Résultat intermédiaire (3 à 5 ans)
Changement de culture où l'on accorde la priorité à l'utilisation et à la collecte de données désagrégées et, dans la mesure du possible, à des analyses intersectionnelles pour répondre aux besoins des décideurs et d'autres utilisateurs de données.
Sans objet
Résultat à long terme (5 ans et plus)
Élaboration de lois, de politiques et de programmes de plus en plus équitables et inclusifs dans tous les ordres de gouvernement et dans la société.
Sans objet
Pour atteindre ces résultats, Statistique Canada a mené et continuera de mener les activités fondamentales suivantes :
l'élaboration de données administratives;
la désagrégation des indicateurs du marché du travail;
la désagrégation des indicateurs sociaux;
la désagrégation des indicateurs de la santé de la population;
la désagrégation des enquêtes par panel sur le Web;
le Programme d'élaboration de données sociales longitudinales;
l'élargissement de la déclaration universelle de la criminalité;
l'enquête sur la diversité au sein des conseils d'administration d'organismes sans but lucratif;
l'enquête sur la situation des entreprises;
l'amélioration du Centre des statistiques sur le genre, la diversité et l'inclusion.
Activités et projets financés
Le PADD comportait divers projets destinés à rehausser la capacité de l'organisme à désagréger les données. De plus, les dirigeants de l'organisme ont favorisé un changement culturel vers la priorisation des données et des analyses désagrégées. Bien que la plus grande partie (66 %) du financement ait été affectée au secteur 8, presque tous les secteurs ont bénéficié des initiatives du PADD.
Depuis sa création, le PADD a appuyé un éventail de projets et d'activités au moyen d'un financement de base et d'appels de demandes ciblés. Au total, 10 projets ayant fait l'objet d'un financement de base, lesquels ont constitué l'assise de l'engagement du PADD, et d'autres activités particulières de communication, de mobilisation et de formation appuyant la promotion du PADD et les consultations à son sujet ont reçu un financement continu au cours de plusieurs exercices financiers ou jusqu'à leur achèvement. Les projets financés dans le cadre du processus d'appel de demandes ont été choisis en fonction de critères harmonisés avec les objectifs du PADD. Ces projets ont été examinés et choisis par le Comité de gouvernance des DG et devaient servir à appuyer des travaux préliminaires ou en cours. Pour les exercices financiers 2022-2023 et 2023-2024, les projets financés dans le cadre du processus d'appel de demandes ont reçu un financement annuel ou pluriannuel. Cependant, l'appel de demandes en 2023-2024 n'a pas été aussi largement annoncé qu'en 2022-2023, et seuls quelques projets choisis dans le secteur 8 ont été retenus.
En 2022-2023, les projets du PADD ont été assujettis à des contraintes budgétaires en raison du contexte financier général de l'organisme, ce qui a nui à la capacité des responsables de projet à pleinement mettre en œuvre les activités de la manière prévue. À mesure que de nouvelles initiatives étaient financées, il était incertain si les besoins en dotation pouvaient être comblés pour certains projets. Afin que ce problème puisse être réglé, des sommes complémentaires aux affectations initiales ont été prévues pour 2022-2023, et des mesures correctives ont été prises à mi-chemin, lesquelles ont notamment consisté à reporter certains projets, à réduire le budget global des projets et à réaffecter des fonds pour accorder la priorité aux projets qui contribuaient directement aux objectifs fondamentaux du PADD. Jusqu'en 2024-2025, le PADD avait subventionné 74 projets et activités. Alors que l'initiative entame la dernière année de son financement sur cinq ans, les 172 millions de dollars ont été entièrement attribués.
À propos de l'évaluation
Autorité
L'évaluation a été menée conformément à la Politique sur les résultats du Conseil du Trésor et au Plan d'audit et d'évaluation fondé sur les risques de Statistique Canada (2024-2025 à 2028-2029).
Objectif et portée
L'objectif de l'évaluation est de fournir des renseignements crédibles et impartiaux sur la pertinence, la conception, l'exécution et le rendement du PADD.
L'évaluation a porté sur la conception et l'exécution du PADD, y compris sa structure de gouvernance; la viabilité des nouvelles activités s'inscrivant dans les opérations courantes de l'organisme; enfin, la progression vers les résultats escomptés à court, à moyen et à long terme. La portée a été établie en collaboration avec le bureau de première responsabilité, et l'évaluation s'est déroulée de novembre 2024 à février 2025. Elle a fait suite à un processus de consultation préalable des cadres supérieurs et des responsables de projet et comprenait l'élaboration d'un modèle logique pendant la phase de planification.
Approche et méthodologie
Les trois questions d'évaluation suivantes ont été définies :
Dans quelle mesure le PADD est-il pertinent lorsqu'il s'agit de répondre aux besoins et de donner suite aux priorités du gouvernement fédéral, y compris ceux de Statistique Canada?
Dans quelle mesure la conception et l'exécution du PADD facilitent-elles l'atteinte des résultats escomptés?
Dans quelle mesure le PADD progresse-t-il vers les résultats escomptés à court, à moyen et à long terme?
De plus amples renseignements sur les questions d'évaluation et les indicateurs connexes figurent à l'annexe A.
Les méthodes de collecte de données décrites à la figure 2 ont servi à orienter l'évaluation. Les constatations exposées dans le présent rapport sont fondées sur la triangulation de ces méthodes de collecte de données.
Figure 2. Méthodes de collecte de donnéesDescription - Figure 2. Méthodes de collecte de données
La figure 2 présente les méthodes utilisées par l'évaluation pour la collecte de données.
Entrevues internes : Des entrevues semi-structurées ont été menées auprès des membres des comités de gouvernance des DG et des SCA ainsi que des responsables de projet. Au total, 27 entrevues internes ont été réalisées auprès de 33 personnes.
Entrevues externes: Des entrevues semi-structurées ont été menées avec des parties prenantes et des utilisateurs de données des gouvernements fédéral, provinciaux et territoriaux, du milieu universitaire et d'autres organismes. Au total, 21 entrevues externes ont été réalisées auprès de 22 personnes.
Études de cas : Trois études de cas ont été réalisées en utilisant une méthodologie mixte, axée sur le Fonds pour les données administratives du PADD, les normes statistiques et la formation interne. Les méthodes de collecte de données pour les études de cas comprenaient :
un examen des dossiers
un sondage auprès des participants à la formation de Statistique Canada. La taille de l'échantillon était 23 avec un taux de réponse de 31 %
8 entrevues internes et externes
Sondage externe : Un sondage a été mené auprès des utilisateurs de données des gouvernements fédéral, provinciaux et territoriaux, du milieu universitaire et d'autres organismes. La taille de l'échantillon était de 370 avec un taux de réponse de 29 %.
Examen de documents : Un examen des dossiers et documents de Statistique Canada a été effectué.
Deux limites principales ont été cernées, et des stratégies d'atténuation ont été employées, comme il est indiqué au tableau 3.
Tableau 3. Limites et stratégies d'atténuation
Limites
Stratégies d'atténuation
Les points de vue recueillis dans le cadre des entrevues externes ne sont peut-être pas entièrement représentatifs, car les données désagrégées financées par le Plan d'action sur les données désagrégées (PADD) ne peuvent pas toujours être distinguées en tant que données de Statistique Canada ou données désagrégées.
Les personnes consultées ont été choisies en fonction de critères précis destinés à maximiser la portée stratégique. De multiples stratégies de recrutement ont été utilisées. Les évaluateurs ont été en mesure de dégager des tendances générales cohérentes.
Les renseignements financiers détaillés sur les dépenses du PADD et leur répartition à l'échelle de l'organisme étaient limités.
L'équipe d'évaluation a tenté de combler ces lacunes, dans la mesure du possible, au moyen d'autres sources d'éléments probants, dont des entrevues auprès d'informateurs clés.
Leçon tirées
Pertinence
Dans quelle mesure le Plan d'action sur les données désagrégées est-il pertinent lorsqu'il s'agit de répondre aux besoins et de donner suite aux priorités du gouvernement fédéral, y compris ceux de Statistique Canada?
Le Plan d'action sur les données désagrégées (PADD) contribue à répondre aux besoins d'information du Canada et s'harmonise avec les priorités pangouvernementales, ainsi qu'avec les priorités stratégiques et les responsabilités essentielles de Statistique Canada. Les projets et les activités du PADD sont conformes aux priorités et aux besoins en matière de données qui ont été énoncés dans les récents budgets, stratégies et rapports du gouvernement fédéral. Ils cadrent aussi avec les priorités globales de l'organisme qui sont décrites dans les lettres de mandat et les documents stratégiques et qui visent des données plus désagrégées, des méthodes de pointe et l'intégration des données.
Les projets et les activités du PADD sont conformes aux priorités et aux besoins en matière de données qui ont été énoncés dans les récents budgets, stratégies et rapports du gouvernement fédéral.
Les projets et les activités du PADD qui contribuent à l'accroissement des actifs de données désagrégées, à l'enrichissement des analyses intersectionnelles et à l'amélioration de l'accès à des données désagrégées cadrent avec plusieurs priorités et stratégies fédérales visant à comprendre les enjeux sociaux, économiques et environnementaux, à faire progresser l'équité, à s'attaquer aux problèmes qui touchent les communautés vulnérables, et à appuyer l'élaboration de politiques fondées sur des données probantes.
En 2018, le gouvernement du Canada (GC) a demandé que davantage de données soient désagrégées selon le genre et d'autres facteurs identitaires croisés pour appuyer la mise en œuvre de son Cadre des résultats relatifs aux genres et de sa Stratégie pour les femmes en entrepreneuriat.
Des données désagrégées selon la race ou les origines ethnoculturelles et les identités croisées ont été recueillies et analysées à l'appui de Construire une fondation pour le changement : La stratégie canadienne de lutte contre le racisme 2019–2022 et de Changer les systèmes pour transformer des vies : la stratégie canadienne de lutte contre le racisme 2024-2028.
Dans son budget de 2021, le gouvernement fédéral a accordé la priorité à la collecte et à l'utilisation de données désagrégées pour moderniser le système de justice du Canada, renforcer l'élaboration de politiques fondées sur des données probantes et appuyer le Cadre de qualité de vie servant à éclairer la prise de décisions et l'établissement des budgets du gouvernement fédéral. Toujours en 2021, le Plan de mise en œuvre fédéral du Canada pour le Programme 2030 a établi que les ministères fédéraux doivent cerner les lacunes en matière de données désagrégées qui orientent les objectifs de développement durable et travailler en partenariat avec Statistique Canada à combler les lacunes statistiques.
Le PADD s'harmonise bien avec la Stratégie relative aux données de 2023 à 2026 pour la fonction publique fédérale, selon laquelle les organisations fédérales doivent élaborer une approche pangouvernementale à l'égard des normes en matière de données qui permettra de mieux comprendre les enjeux, de réduire le dédoublement des données et de favoriser l'interopérabilité. Les deux initiatives ont une vision commune et soulignent l'importance d'élaborer et d'intégrer des normes statistiques et de renforcer les capacités au sein de la fonction publique.
En plus de cadrer avec les stratégies et les priorités fédérales, l'approche pangouvernementale et les piliers du PADD sont conformes à plusieurs recommandations du Bureau du vérificateur général visant à :
renforcer la collaboration entre les ministères et organismes fédéraux, dont Statistique Canada, pour déterminer et prioriser les besoins en matière de données désagrégées afin d'orienter les objectifs de développement durable;
accroître la collecte et l'utilisation de données désagrégées à l'appui de l'ACS Plus afin d'orienter et d'évaluer les politiques et les programmes.
Les projets et les activités du PADD s'harmonisent également avec les priorités et les stratégies à l'échelle de l'organisme.
Les projets et les activités du PADD se reflètent dans la lettre de mandat de 2021 de l'organisme, qui engageait Statistique Canada à favoriser une approche pangouvernementale en matière d'amélioration de la collecte, de l'analyse et de l'offre de données désagrégées. L'accent mis par le PADD sur l'accès amélioré, les normes en matière de données ainsi que la mobilisation et la collaboration est conforme à la stratégie de modernisation de Statistique Canada, qui met en valeur la prestation de services axés sur l'utilisateur, les méthodes de pointe et l'intégration des données, le renforcement des capacités statistiques et le leadership, de même que le partage et la collaboration. Il cadre également avec la Stratégie de données de Statistique Canada, en particulier la recherche de données et l'interopérabilité de ces dernières.
Conception et exécution
Dans quelle mesure la conception et l'exécution du Plan d'action sur les données désagrégées facilitent-elles l'atteinte des résultats escomptés?
La structure et les mécanismes de gouvernance du Plan d'action sur les données désagrégées (PADD) facilitent la surveillance à l'échelle du gouvernement fédéral et de l'organisme, mais ils sont principalement axés sur la surveillance de la mise en œuvre plutôt que le suivi des progrès accomplis vers l'obtention des résultats escomptés. Bien que la structure de gouvernance comporte certains éléments de reddition de comptes, il reste des lacunes, et l'emphase sur la mise en œuvre plutôt que l'orientation stratégique limite sa capacité à faciliter l'atteinte des résultats à moyen et à long terme.
Des efforts de consultation ont aidé à orienter un certain nombre de priorités et de projets du PADD; toutefois, il subsiste des préoccupations selon lesquelles certains produits de données désagrégées sont diffusés sans consultation suffisante, ce qui risque de renforcer un message d'inadéquation. Bien que les activités du PADD aient pris appui sur l'infrastructure, les ressources et les capacités existantes et les aient améliorées dans certains cas, les initiatives qui dépendent d'un suréchantillonnage ne sont pas viables. Les efforts visant à soutenir les nouvelles activités financées par le PADD en les intégrant aux opérations courantes de l'organisme ont été limités. Des ententes de recouvrement des coûts pourraient être utiles, mais le climat financier actuel limite cette option.
La structure et les mécanismes de gouvernance du PADD facilitent la surveillance à l'échelle du gouvernement fédéral et de l'organisme et appuient la réalisation des produits livrables des projets et des activités du PADD ainsi que la gestion des fonds du PADD.
Le Comité consultatif fédéral des SMA sur les données désagrégées a exercé une surveillance suffisante pour veiller à ce que les priorités du plan de travail des quatre groupes de travail interministériels mènent à la réalisation des produits livrables attendus. Les réunions trimestrielles de ce comité, appuyées par le Secrétariat du PADD, ont servi à suivre l'état d'avancement des produits livrables des groupes de travail au moyen d'exposés périodiques présentés par les coresponsables des groupes de travail. Les efforts de surveillance du comité des SMA ont contribué à l'achèvement en temps opportun des produits livrables des groupes de travail. Selon les procès-verbaux des réunions du comité des SMA, tous les produits livrables attendus, y compris le lancement du Carrefour de ressources en matière de données désagrégées, étaient en voie d'être achevés au plus tard au début de 2025. Cependant, les éléments probants de l'évaluation n'indiquent pas clairement dans quelle mesure le comité des SMA est prêt à surveiller la mise en œuvre et l'adoption des produits livrables du plan de travail à l'échelle du gouvernement fédéral.
Le Comité de gouvernance des DG, avec l'aide du Secrétariat du PADD, a exercé une surveillance suffisante pour veiller à ce que les produits livrables des activités et des projets dirigés par l'organisme soient sur la bonne voie ou soient révisés en fonction des circonstances changeantes. Chaque trimestre, le Comité de gouvernance des DG a passé en revue le rapport du tableau de bord des projets Note de bas de page 4 afin de déterminer s'il fallait prendre des mesures à l'égard des projets qui étaient sur la mauvaise voie, retardés ou annulés. Les rapports de projet trimestriels ont permis au Comité de gouvernance des DG de prévoir les projets pour lesquels un excédent budgétaire était attendu et d'en repérer rapidement d'autres auxquels les fonds seraient utiles Note de bas de page 5. De plus, le Comité de gouvernance des DG a assuré un suivi suffisant pour appuyer la réalisation des produits livrables des groupes de travail au niveau de l'organisme, au moyen d'exposés présentés par les coresponsables des groupes de travail. Avant sa dissolution, chaque groupe de travail a présenté ses recommandations et les éventuels outils ou stratégies s'y rattachant au Comité de gouvernance des DG. Toutefois, il n'était pas clair dans quelle mesure la surveillance exercée par ce comité a favorisé l'efficacité des groupes de travail et de leurs produits livrables. Certains représentants de l'organisme ont signalé que les groupes de travail se voulaient essentiellement des groupes de discussion et n'avaient pas de directives claires sur les problèmes qu'ils cherchaient à régler.
Les comités des DG et des SCA ont exercé une surveillance financière afin de gérer l'affectation des fonds du PADD. La surveillance financière s'est appuyée sur les outils de suivi trimestriel des projets et les cahiers d'établissement des coûts au niveau du projet et au niveau stratégique. Les efforts de surveillance financière du Comité directeur des SCA ont mené à une réduction du financement des projets destinée à compenser l'affectation excédentaire de fonds prévue en 2022-2023.
La surveillance de certains indicateurs de rendement assurée par la gouvernance du PADD a contribué à l'atteinte de certains résultats à court terme, mais le nombre restreint d'indicateurs de rendement a limité la mesure dans laquelle les responsables de la gouvernance du PADD ont pu suivre les progrès vers l'obtention des résultats attendus.
Le Comité de gouvernance des DG a assuré une certaine surveillance des progrès réalisés en vue de combler les lacunes en matière d'information. À cette fin, il s'en est remis aux rapports annuels du Secrétariat du PADD sur la proportion des indicateurs désagrégés en fonction des quatre groupes visés par l'EE. Cette surveillance a fait ressortir le fait que la proportion des indicateurs désagrégés en fonction des populations racisées et des personnes ayant une incapacité n'atteignait pas la cible. Les membres du comité ont donc été priés de travailler avec leurs équipes respectives à accroître les indicateurs liés aux populations racisées. Le comité a conclu qu'aucune autre mesure n'était requise à l'égard des personnes ayant une incapacité parce que la diffusion des données quinquennales de l'Enquête canadienne sur l'incapacité devait permettre de combler cette lacune. L'absence d'indicateurs de rendement supplémentaires a limité la capacité des responsables de la gouvernance du PADD à surveiller les progrès accomplis vers l'atteinte des résultats attendus.
Le Comité de gouvernance des DG a apporté de récents changements à ses efforts de surveillance pour faciliter le suivi des résultats des projets afin de mieux comprendre comment ils contribuent à l'atteinte des résultats escomptés.
En 2024-2025, le Comité de gouvernance des DG a étendu sa surveillance des projets et des activités du PADD à la progression vers les résultats escomptés des projets afin d'être mieux capable de surveiller l'harmonisation des projets du PADD avec les résultats attendus. À l'appui de cette surveillance élargie, le Comité de gouvernance des DG a misé sur des efforts supplémentaires qui ont notamment consisté à revenir à des réunions mensuelles (plutôt que trimestrielles), à réviser les rapports de projet trimestriels afin d'y intégrer d'autres variables liées aux risques (plus précisément, la capacité à favoriser l'avancement et le degré de difficulté à atteindre les jalons) et à inviter les équipes de projet à présenter un exposé sur leurs progrès, y compris la façon dont les fonds du PADD ont été utilisés.
La gouvernance du PADD comporte certains éléments de reddition de comptes, et l'on a pris des mesures destinées à améliorer la reddition de comptes en matière de gouvernance afin de veiller à ce que les projets cadrent avec les objectifs du PADD.
À en juger par des éléments probants, des mécanismes de reddition de comptes en matière de gouvernance ont été établis. Mentionnons notamment les mandats de gouvernance et le cadre de référence du Secrétariat du PADD, du Comité de gouvernance des DG, du Comité directeur des SCA, du Comité consultatif fédéral des SMA sur les données désagrégées ainsi que des comités et des groupes de travail au niveau de l'organisme qui en décrivent la raison d'être, les rôles et les responsabilités et la structure hiérarchique. Les mécanismes en question comprenaient également une méthode d'évaluation officielle destinée à orienter le choix et le financement des projets au moyen d'appels de propositions, ainsi que des rapports de projet périodiques et quelques indicateurs de rendement établis. Cependant, des obstacles à la reddition de comptes en matière de gouvernance ont contribué à des problèmes liés à la recommandation et à l'approbation des projets du PADD.
Les projets du PADD financés dans le cadre du processus d'appel de demandes étaient choisis par le Comité des DG sur la gouvernance et approuvés par le Comité directeur des SCA. Le Secrétariat du PADD s'est servi d'une grille d'évaluation pour veiller à ce que les projets possibles figurant sur la liste initiale présentée au Comité de gouvernance des DG soient conformes aux principes fondamentaux du PADD. Or, aucun des deux comités ne semblait disposer de mécanismes supplémentaires permettant de vérifier que la recommandation et l'approbation des projets financés cadraient avec les résultats attendus du PADD. Il a été mentionné que le peu de temps dont disposait le Comité directeur des SCA pour délibérer sur les recommandations de financement limitait davantage sa capacité à rendre des comptes à l'égard de l'approbation des projets recommandés. Les lacunes dans la reddition de comptes relative à la recommandation et à l'approbation des projets ont créé un risque que certains projets financés par le PADD puissent ne pas être harmonisés avec les résultats attendus. En 2022-2023, le Comité directeur des SCA a diffusé une directive visant à renforcer la reddition de comptes quant au choix des projets en exigeant que tous les projets cadrent avec les engagements fondamentaux du PADD. Par conséquent, certains projets ont été réduits ou privés de financement en complément aux mesures correctives financières mentionnées précédemment.
Des personnes consultées à l'interne ont soulevé un manque de transparence et de communication dans les processus d'appel de demandes et de choix des projets. Une meilleure communication des attentes tout au long de ces processus aurait amélioré l'harmonisation des propositions, bien que certains mécanismes de soutien aient été en place. Au cours de la première année de mise en œuvre, certains projets ont également rencontré des défis initiaux en raison d'attentes peu claires et de mécanismes de rapport non définis, lesquels ont fini par être réglés. Le moment auquel les décisions de financement étaient prises était problématique aussi, car il ne concordait pas avec la planification des projets, ce qui laissait peu de temps aux équipes de projet pour planifier les activités et obtenir des ressources.
Les lacunes dans la reddition de comptes en matière de gouvernance peuvent nuire à l'atteinte des résultats à moyen et à long terme.
Les produits livrables des groupes de travail étaient censés favoriser le changement de culture au sein de l'organisme et dans l'ensemble du gouvernement fédéral. Des lacunes dans la reddition de comptes à l'égard de la mise en œuvre des produits livrables des groupes de travail ont été relevées chez les comités des DG et des SMA. Le Comité de gouvernance des DG ne disposait pas de ressources affectées tout particulièrement à la mise en œuvre et au suivi des recommandations des groupes de travail de l'organisme, ni d'un plan clair à cet égard, ce qui a nui à leur mise en œuvre complète. Le Comité consultatif fédéral des SMA sur les données désagrégées ne semble pas avoir de plan pour appuyer l'adoption et l'application des ressources produites par les groupes de travail interministériels et accessibles sur le Carrefour de ressources en matière de données désagrégées. Bien que le carrefour de données fasse partie de la plateforme de l'École de la fonction publique du Canada (EFPC), il n'est pas clair si le comité des SMA est responsable de sa surveillance et de sa mise à jour.
On a investi dans le suréchantillonnage de certains groupes dans des enquêtes phares pour pouvoir produire des données désagrégées en temps opportun afin de favoriser l'atteinte des résultats à court terme. Toutefois, les comités des DG et des SCA ont reconnu que le suréchantillonnage n'était pas un moyen viable de produire des données désagrégées, étant donné les coûts relativement élevés et la diminution des taux de réponse. Malgré certaines mesures prises au sein du Comité de gouvernance des DG pour remédier à la dépendance au suréchantillonnage Note de bas de page 6, l'évaluation a révélé peu d'éléments probants selon lesquels l'un ou l'autre des comités était responsable de faire avancer l'élaboration ou l'application de méthodes de rechange. Cette lacune dans la reddition de comptes à l'égard des efforts visant à s'attaquer aux problèmes de suréchantillonnage nuit à l'obtention des résultats à moyen et à long terme. Faute de solutions de rechange viables, des personnes clés ont dit s'attendre à ce que les enquêtes se rabattent sur des ensembles de données plus agrégées.
L'orientation stratégique à l'appui de l'atteinte des résultats escomptés était limitée, en raison de documents de base inadéquats et d'une vision à court terme plutôt qu'à long terme.
La mesure dans laquelle la gouvernance du PADD permettait d'assurer une orientation stratégique était limitée parce qu'il n'en était pas question dans les mandats et les priorités des comités des DG, des SCA et des SMA. Au niveau de l'organisme, les priorités des comités des DG et des SCA étaient axées sur l'affectation du financement et la mise en œuvre des projets et des activités plutôt que sur l'orientation stratégique à donner. Le comité externe des SMA a priorisé la mise en œuvre du plan de travail visant à éliminer les obstacles à la collecte et à l'utilisation de données désagrégées, mais il y avait peu d'indications selon lesquelles des efforts supplémentaires ont été consacrés à la planification stratégique d'une approche pangouvernementale relative à l'obtention des résultats attendus à moyen et à long terme.
Il a surtout été mentionné que les priorités et l'orientation du PADD étaient fondées sur les documents de base. Toutefois, ces documents ne comportaient pas de modèle logique qui décrivait clairement les résultats attendus, les indicateurs de rendement et la stratégie de mesure propres au PADD. Ils comprenaient plutôt un modèle logique plus générique qui cadrait avec les résultats de l'organisme. L'inclusion d'un modèle logique propre au PADD dans les documents de base aurait pu aider les responsables de la gouvernance du PADD à mener une réflexion plus stratégique pour orienter l'élaboration, le suivi et les modifications du plan d'action. Aucun élément probant dans l'évaluation ne permettait de penser que des indicateurs de rendement liés aux résultats à moyen et à long terme faisaient l'objet d'une mesure, d'une surveillance ou de rapports, ce qui limitait la capacité des responsables de la gouvernance du PADD à cerner les lacunes en matière de rendement et à modifier le plan de manière stratégique.
Divers efforts de consultation ont permis d'orienter certains projets et activités du PADD afin de répondre aux besoins des utilisateurs de données.
Les efforts de consultation menés dans le cadre du PADD comprenaient des questionnaires en ligne, des démarches ciblées auprès des partenaires, des parties prenantes, des groupes sous-représentés et marginalisés, des provinces et des territoires et des experts du milieu universitaire, de même que des discussions internes (au niveau de l'organisme et du GC). L'évaluation n'a pas permis de déterminer dans quelle mesure il y a eu des consultations auprès des parties prenantes dans l'ensemble des projets et des activités du PADD. Cependant, selon certains documents internes, plus du tiers des équipes de projet du PADD ont dit avoir prévu ou mené à bien des activités de consultation. En plus des consultations officielles auprès des parties prenantes, il a été mentionné que des réunions courantes avec les utilisateurs de données (p. ex. les coordonnateurs statistiques provinciaux et territoriaux ou la Fédération canadienne des municipalités) ont servi à orienter certains projets.
La rétroaction issue des consultations représente un élément important de la reddition de comptes qui aide à clarifier et à confirmer les besoins des parties prenantes afin de veiller à ce que les données désagrégées et les produits analytiques connexes soient pertinents. Selon les utilisateurs de données sondés qui ont dit avoir participé à des consultations sur les données désagrégées, 63 % Note de bas de page 7 (n=177) ont déclaré avoir reçu un résumé ou des comptes rendus de la rétroaction donnée à Statistique Canada, et 90 % étaient satisfaits des efforts mis par Statistique Canada à comprendre leurs besoins en matière de données désagrégées et leurs points de vue à ce sujet. Quelques utilisateurs de données ont souligné que les améliorations apportées aux consultations de Statistique Canada au cours des cinq dernières années, en particulier auprès des Autochtones, s'étaient traduites par une plus grande satisfaction à l'égard des données désagrégées et des produits analytiques connexes.
Les consultations ont amélioré la pertinence de certains projets du PADD. Toutefois, certaines préoccupations ont été soulevées quant au fait que la diffusion de données désagrégées et de produits connexes sans consultation suffisante risquait de renforcer un message d'inadéquation.
Les commentaires recueillis lors des consultations auraient eu une incidence sur certains projets. Des responsables de projet ont dit que, par suite des consultations auprès des parties prenantes, leur projet avait fait l'objet de plusieurs améliorations qui ont aidé à faire en sorte qu'on réponde aux besoins des utilisateurs de données. Voici quelques exemples :
des révisions apportées au contenu des enquêtes afin qu'il réponde mieux aux besoins des utilisateurs de données tout en étant conforme aux priorités du PADD (p. ex. les indicateurs du marché du travail et le questionnaire de collecte par approche participative sur la diversité au sein des conseils d'administration d'organismes de bienfaisance et sans but lucratif);
l'élaboration d'un document de lignes directrices et d'un cadre analytique et la création d'un comité spécial relevant de l'Association canadienne des chefs de police afin d'aider les secteurs de compétence à élaborer une approche en matière de collecte de données déclarées par la police sur les identités autochtones et racisées;
des modifications de la portée du projet sur les indicateurs environnementaux, sociaux et de gouvernance relatifs aux Autochtones afin de mettre l'accent sur l'établissement de lignes directrices concernant l'élaboration d'indicateurs autochtones, grâce à une compréhension plus poussée des complexités entourant leur création.
Certaines préoccupations ont été soulevées quant au fait que des représentants du groupe de population visé n'ont pas suffisamment été consultés avant la diffusion d'une variété de données ou de produits analytiques liés à des projets du PADD. La diffusion de données sans une participation suffisante de ces représentants peut, par inadvertance, renforcer des messages d'inadéquation, car l'omission possible d'importants facteurs contextuels peut se traduire par des données qui ne répondent pas aux besoins des parties prenantes (p. ex. les Autochtones). Bien que certaines équipes de projet du PADD aient sollicité l'aide des communautés pour orienter les produits livrables du PADD (p. ex. les portraits de certains groupes de population racisés), certaines personnes clés recommandent que l'organisme consacre plus de temps à consulter les parties prenantes externes à propos des messages communiqués par les produits de données désagrégées.
Certains projets du PADD sont exécutés de manière efficace grâce à l'infrastructure existante, à des approches méthodologiques et d'échantillonnage améliorées et à l'expertise interne. Quelques projets ont contribué à l'enrichissement des capacités et des ressources de Statistique Canada.
La plupart des responsables de projet ont dit disposer de suffisamment de compétences internes et de partenariats pour répondre aux besoins de leur projet, et que le financement du PADD a aidé à recruter le personnel nécessaire pour combler tout déficit de connaissances ou de ressources. Il y a des indications selon lesquelles certains projets du PADD ont contribué à limiter les coûts supplémentaires par le recours à l'infrastructure, aux ressources et aux capacités existantes. À cette fin, ils ont notamment employé les moyens suivants :
utiliser l'infrastructure déjà mise en place par l'organisme pour la collecte, le traitement et la diffusion des données d'enquête;
utiliser les données d'autres enquêtes ou bases de données couplées (p. ex. le Programme de déclaration uniforme de la criminalité, le recensement, la Base de données longitudinales sur l'immigration) pour appuyer la désagrégation des données;
appliquer les approches méthodologiques actuelles (p. ex. l'estimation sur petits domaines) pour produire des données plus détaillées dans le cadre de l'Enquête sur la population active;
tirer parti des initiatives d'autres ministères pour progresser vers les résultats du PADD (p. ex. miser sur le partenariat avec l'EFPC pour faire avancer les programmes et les outils de formation sur les données désagrégées);
créer des échantillons d'enquête ciblant des groupes de population particuliers (p. ex. les personnes racisées) à partir du recensement et de sources de données administratives connexes afin d'accroître les taux de réponse et de réduire la taille des échantillons;
mettre à profit l'expertise et l'expérience de l'équipe des communications de Statistique Canada et du Centre de la statistique et des partenariats autochtones à l'appui des activités de consultation et de communication.
Quelques initiatives du PADD ont contribué à l'enrichissement des capacités et des ressources de Statistique Canada. Par exemple, une équipe de projet a mis l'accent sur l'amélioration des capacités méthodologiques en collaborant avec l'équipe de la science des données à appliquer l'apprentissage automatique à la recherche de solutions à la non-réponse aux enquêtes. Les groupes de travail ont produit plusieurs ressources pour aider à répondre aux besoins des employés de l'organisme et des autres employés fédéraux en matière de collecte, d'analyse et de communication de données désagrégées. Ils ont notamment créé un carrefour de données désagrégées qui contient des ressources et des liens vers des ressources en matière de données désagrégées, des guides et des documents de formation élaborés par l'organisme ou par d'autres ministères. Cependant, il n'est pas clair à quel point ces ressources ont permis d'améliorer les compétences ou les connaissances au sein de l'organisme.
Certaines activités du PADD ont été conçues de manière qu'elles appuient la désagrégation continue des données au-delà de la période de financement, mais les efforts visant à soutenir les activités financées par le PADD n'ont pas été suffisamment priorisés.
Certaines activités du PADD ont été conçues de façon qu'elles favorisent l'obtention de résultats longtemps après la fin de l'enveloppe de financement du PADD. Les activités liées aux normes et à l'acquisition de données ont pour objet de combler les lacunes en matière d'information et d'éviter de devoir mener des enquêtes supplémentaires, tandis que l'élaboration de ressources accessibles et d'un carrefour de données désagrégées pour le personnel fédéral doit permettre de mieux faire connaître et comprendre le besoin de données désagrégées et de favoriser une culture où la priorité leur est accordée. Des représentants du Comité de gouvernance des DG ont décrit le financement offert dans le cadre du processus d'appel de demandes comme étant des fonds d'amorçage destinés à aider à lancer des projets et à en démontrer l'utilité aux parties prenantes. Toutefois, les efforts visant à soutenir les activités de projet n'auraient pas été systématiquement priorisés, et l'on s'attend à ce qu'un financement demeure nécessaire à la désagrégation continue des données. Cette dépendance à l'aide financière du PADD souligne la nécessité d'adopter une approche plus stratégique pour assurer la viabilité à long terme des résultats du PADD.
Bien que le suréchantillonnage ne soit pas une pratique viable, relativement peu d'efforts ont été consacrés à l'étude ou à l'adoption d'approches méthodologiques de rechange.
Lorsque le PADD a été élaboré, le suréchantillonnage a servi à la production de données désagrégées. La plupart des employés de l'organisme participant à des projets qui reposent sur un suréchantillonnage continu ont déclaré qu'aucune autre méthode ne permettait de produire des résultats semblables en fait de données. Le personnel de l'organisme reconnaissait les coûts élevés du suréchantillonnage, mais il a signalé que, comme la diminution des taux de réponse continuait de poser des problèmes, toute réduction du financement du suréchantillonnage limitait la capacité des enquêtes phares à produire des données désagrégées.
Il y a des éléments probants selon lesquels le financement du PADD a contribué aux efforts méthodologiques visant à favoriser un échantillonnage efficace Note de bas de page 8, à mieux comprendre la non-réponse et à élaborer des lignes directrices relatives aux données synthétiques. Néanmoins, il existe peu de preuve que les efforts consacrés à l'avancement de solutions méthodologiques de rechange au suréchantillonnage ont été stratégiquement priorisés au début de l'initiative. Certains représentants de l'organisme s'attendent à ce que l'initiative d'accélération méthodologique fasse ressortir les techniques émergentes à appliquer au PADD, mais l'étendue des progrès réalisés à cet égard demeure incertaine.
Fonds pour les données administratives du Plan d'action sur les données désagrégées
L'objectif du fonds pour les données administratives du Plan d'action sur les données désagrégées (PADD) est d'offrir à des partenaires externes l'occasion d'améliorer leurs fonds de données administratives désagrégées au moyen d'un financement qui couvre les coûts directs. Les divisions qui ont trouvé des partenaires sont invitées à présenter des propositions dans le cadre d'un processus de demande officiel. À l'heure actuelle, cinq projets de divers secteurs ont été financés ou sont en cours. La collaboration avec des partenaires externes, des ministères et Statistique Canada dans le cadre de multiples projets se révèle essentielle à l'avancement des efforts de modernisation des données.
Par exemple, le projet de modernisation du Système d'information sur le personnel d'enseignement dans les universités et les collèges (SIPEUC) illustre la façon dont le PADD a contribué à la résolution novatrice de problèmes en vue d'une gestion durable de défis complexes, tels que le fardeau de réponse, tout en faisant progresser ses priorités. En ajoutant des variables aux sondages auprès du personnel et en les combinant à des données provenant d'autres sources (p. ex. le Recensement de la population), le projet pilote a fourni de précieux renseignements sur les initiatives d'équité, de diversité et d'inclusion (EDI) et a permis de cerner des aspects à améliorer dans les universités, sans compromettre la vie privée des répondants. Le projet de modernisation du SIPEUC a depuis été élargi et comprend des données sur des groupes qui n'étaient auparavant pas représentés dans le système. Il est prévu d'ajouter les données du SIPEUC à l'Environnement de couplage de données sociales de Statistique Canada, ce qui pourrait fournir un cadre solide d'analyse de l'EDI au moyen de divers indicateurs démographiques. Les partenaires externes sont optimistes quant à l'avenir du projet et à ses retombées positives durables, mais, comme pour d'autres projets du PADD, il demeure prioritaire de veiller à disposer de sources de financement sûres dans l'avenir pour que le projet continue de connaître du succès.
Les ententes de recouvrement des coûts peuvent aider à soutenir certains projets du PADD, mais le climat financier actuel limite considérablement la viabilité de cette option.
Des personnes clés ont signalé que le financement continu plus limité du PADD servira à appuyer des projets essentiels à la mission, comme l'Enquête sur la population active, alors que d'autres projets peuvent s'attendre à des réductions de financement. Pour assurer la viabilité des projets, les responsables de la gouvernance du PADD discutent de la possibilité que certaines initiatives du PADD soient converties en projets à recouvrement des coûts.
Au moins un projet (le compte satellite autochtone) a opéré une transition vers une entente de recouvrement des coûts avec Services aux Autochtones Canada afin qu'il puisse se poursuivre pour une deuxième année, et quelques autres équipes de projet ont dit étudier des options de recouvrement des coûts avec des partenaires fédéraux (p. ex. Patrimoine canadien, Emploi et Développement social Canada), provinciaux et territoriaux. Cependant, de nombreuses personnes consultées ont fait remarquer que, bien que le PADD produise des données et des analyses qui répondent aux besoins des utilisateurs de données, les possibilités de recouvrement des coûts sont limitées et plus compliquées en raison du climat financier actuel. De plus, certaines personnes consultées ont souligné que les utilisateurs de données sont moins enclins à utiliser leurs propres fonds du fait que Statistique Canada a reçu un important financement pour élargir et améliorer les données et les analyses désagrégées.
Rendement
Dans quelle mesure le Plan d'action sur les données désagrégées progresse-t-il vers les résultats escomptés à court, à moyen et à long terme?
Bien que le Plan d'action sur les données désagrégées (PADD) progresse vers les résultats escomptés, certains aspects nécessitent une attention plus poussée. Les activités de sensibilisation et de formation ont aidé les participants à mieux comprendre la désagrégation des données, mais certains obstacles à l'application et à l'acquisition de connaissances sur les données désagrégées ont été relevés. Le PADD contribue à combler les lacunes en matière d'information, mais il n'est pas jugé viable de dépendre du suréchantillonnage pour produire des données désagrégées à partir d'enquêtes phares. Le plan d'action améliore certains aspects de la qualité des données, mais certains problèmes liés à la pertinence et à l'accessibilité persistent.
Le PADD favorise et renforce un changement culturel où l'on accorde la priorité aux données désagrégées et à l'analyse intersectionnelle en élargissant l'offre de données désagrégées et de produits connexes. Cependant, pour continuer de progresser, il faudra insister davantage sur la sensibilisation et la formation. Certains éléments probants préliminaires semblent indiquer que le PADD a une incidence positive sur les utilisateurs de données, quoique ces effets soient en partie limités par la capacité des utilisateurs de données et des décideurs à comprendre et à utiliser les données désagrégées et les produits analytiques connexes. On note également une certaine préoccupation quant au fait que le résultat à long terme du PADD échappe à l'influence et au mandat de Statistique Canada.
Les activités de sensibilisation et de formation du PADD favorisent et permettent de maintenir une grande prise de conscience et compréhension de l'importance des données désagrégées et de l'ACS Plus.
De nombreuses activités de sensibilisation au besoin de données désagrégées et à la nécessité de l'ACS Plus ont été mises en œuvre tant à Statistique Canada qu'à l'extérieur de l'organisme. À la fin de 2022-2023, le Secrétariat du PADD avait présenté plus d'une centaine d'exposés à l'échelle de l'organisme, à d'autres ministères et à des parties prenantes externes Note de bas de page 9 afin de les sensibiliser à l'importance des données désagrégées et aux priorités du PADD. Parmi les autres efforts de sensibilisation à l'interne et à l'externe, mentionnons une page Web spéciale sur le site intranet de l'organisme, un carrefour pangouvernemental de données désagrégées, des présentations au forum de recherche de l'organisme, des publications sur les médias sociaux, des balados, des conférences et des ateliers, ainsi qu'une vidéo d'introduction en deux parties aux données désagrégées, qui a été visionnée plus de 850 fois au cours des cinq premiers mois. La majorité (79 %) des utilisateurs de données sondés (n=370) ont dit connaître le concept des données désagrégées.
En réponse au besoin reconnu de formation pour aider les parties prenantes à comprendre les données désagrégées et l'ACS Plus, le PADD a financé six programmes de formation Note de bas de page 10 s'adressant au personnel de l'organisme et aux autres employés du gouvernement fédéral. Les cours ont porté sur divers aspects clés liés à l'utilisation et à l'importance des données désagrégées (p. ex. la protection des renseignements personnels, la confidentialité, l'accessibilité, l'utilité, l'éthique, l'estimation sur petits domaines, les types et les formats de données, les cadres, les lignes directrices, l'application, les stratégies, les études de cas). De 2022 à 2024, plus de 350 employés fédéraux (de l'organisme et d'autres ministères) ont participé aux programmes synchrones.
La plupart des utilisateurs très expérimentés et de longue date des données de Statistique Canada ont déclaré que leur niveau de connaissance et de compréhension du besoin de données désagrégées et de la nécessité de l'ACS Plus n'avait pas changé au cours des quatre dernières années, puisqu'il était déjà élevé. Bien que quelques utilisateurs de données aient constaté parmi leurs parties prenantes une plus grande sensibilisation aux données désagrégées et une plus grande importance accordée à ces dernières, ce phénomène n'a pu être attribué au PADD.
Les activités de formation du PADD aident les participants à comprendre la désagrégation des données, mais certains obstacles à l'application et à l'acquisition de connaissances sur les données désagrégées ont été relevés.
Les participants de Statistique Canada se sont dits très satisfaits des cours de formation du PADD. Selon le sondage lié aux études de cas, l'atelier initial d'analyse des données désagrégées a eu une incidence positive sur la connaissance que les participants avaient du PADD et de ses composantes, y compris les considérations éthiques, les pratiques relatives à la confidentialité et les normes en matière de données. L'atelier a amélioré de manière efficace l'application des connaissances pour la plupart des participants. En outre, les cours de formation ont renforcé et élargi le réseau communautaire d'utilisateurs de données désagrégées, à mesure que les participants découvraient de nouvelles personnes-ressources et établissaient de nouvelles relations auxquelles faire appel dans le cadre de leur travail. Toutefois, les participants ont également mentionné certains obstacles à une pleine utilisation des compétences qu'ils ont acquises pendant la formation, à savoir des données désagrégées insuffisantes pour effectuer le niveau d'analyse requis, le besoin de formation analytique supplémentaire, le manque de ressources (qu'il s'agisse de budget, de personnel ou de technologie) et le temps limité pour appliquer leurs apprentissages.
À l'extérieur de Statistique Canada, il y a certaines indications selon lesquelles les programmes de formation sur les données désagrégées pourraient bénéficier d'efforts de sensibilisation supplémentaires. Un peu plus de la moitié (53 %) des utilisateurs de données sondés qui étaient des employés du gouvernement fédéral (n=231) ont dit ne pas être au courant de la formation offerte, tandis que 15 % avaient participé à au moins une partie de la formation. Parmi les personnes qui ont pris part à la formation, le résultat le plus souvent mentionné était une meilleure compréhension des données désagrégées et de la façon dont elles peuvent orienter l'élaboration des politiques.
Le PADD aide à combler les lacunes en matière d'information en augmentant la proportion des indicateurs désagrégés pour les quatre groupes visés par l'EE, mais peu d'utilisateurs de données ont fait état de retombées particulières de la multiplication des données désagrégées.
Depuis 2020-2021, le pourcentage des indicateurs socioéconomiques désagrégés en fonction du genre, des populations racisées, des Autochtones et des personnes ayant une incapacité a augmenté. En 2023-2024, les indicateurs liés au genre avaient dépassé la cible de 17 points de pourcentage, les indicateurs liés aux populations racisées étaient à 1 point de pourcentage de leur cible et les indicateurs liés aux Autochtones et aux personnes ayant une incapacité avaient augmenté, mais demeuraient à 6 et à 8 points de pourcentage, respectivement, de leur cible (voir la figure 3).
Figure 3. Pourcentage des indicateurs statistiques produits régulièrement par le programme de la statistique socioéconomique qui sont liés aux personnes et sont désagrégés en fonction du groupe visé par l'équité en matière d'emploi, 2020-2021 à 2023-2024Description - Figure 3. Pourcentage des indicateurs statistiques produits régulièrement par le programme de la statistique socioéconomique qui sont liés aux personnes et sont désagrégés en fonction du groupe visé par l'équité en matière d'emploi, 2020-2021 à 2023-2024
La figure 3 est un graphique à colonnes qui montre le pourcentage d'indicateurs statistiques régulièrement produits par le programme de la Statistique socioéconomique qui concernent les personnes et sont désagrégés selon le groupe d'équité en emploi pour les exercices financiers 2020-2021 à 2023-2024.
Pour le genre, la cible est de 80 % et le pourcentage pour chaque exercice financier était le suivant :
2020-2021 : 64 %
2021-2022 : 65 %
2022-2023 : 80 %
2023-2024 : 97 %
Pour les Autochtones, la cible est de 70 % et le pourcentage pour chaque exercice financier était le suivant :
2020-2021 : 47 %
2021-2022 : 48 %
2022-2023 : 49 %
2023-2024 : 64 %
Pour les populations racisées, la cible est de 70 % et le pourcentage pour chaque exercice financier était le suivant :
2020-2021 : 43 %
2021-2022 : 49 %
2022-2023 : 60 %
2023-2024 : 69 %
Pour les personnes ayant une incapacité, la cible est de 50 % et le pourcentage pour chaque exercice financier était le suivant :
2020-2021 : 23 %
2021-2022 : 26 %
2022-2023 : 19 %
2023-2024 : 42 %
Parmi les utilisateurs de données sondés qui ont répondu à la question portant sur la mesure dans laquelle les données désagrégées de Statistique Canada comblent les lacunes en matière d'information depuis 2021 (n=342), environ 65 % ont déclaré que ces données comblaient effectivement les lacunes en matière d'information. Ils ont répondu dans une proportion de 23 % que ces lacunes étaient comblées dans une grande ou une très grande mesure. Les utilisateurs de données jugent que l'efficacité avec laquelle Statistique Canada produit des données qui permettent de mieux comprendre les groupes visés par l'EE est la plus élevée pour les femmes (55 %), suivies des populations racisées (44 %), des Autochtones (42 %) et des personnes ayant une incapacité (34 %). Cependant, peu de personnes consultées ont pu préciser si, et en quoi, la multiplication des données désagrégées contribuait aux débats entourant la prise de décisions, la recherche ou les politiques. Les utilisateurs de données qui pouvaient témoigner de la contribution du PADD à leur organisation ont déclaré que la multiplication des données désagrégées aide à orienter les genres de questions de recherche auxquelles s'intéressent les membres de leur organisation, à fournir les données probantes nécessaires à l'appui d'une révision du financement et des investissements, ainsi qu'à orienter les activités organisationnelles de recherche et de collecte de données.
Comme il a déjà été mentionné, parce que le recours au suréchantillonnage pour la production de données désagrégées à partir d'enquêtes phares est peu viable, il permet difficilement de combler les lacunes en matière d'information. Il n'est toutefois pas clair dans quelle mesure l'organisme a accru sa capacité d'éviter le recours ou de réduire sa dépendance au suréchantillonnage en mettant de l'avant des méthodologies qui aident à remédier à la diminution des taux de réponse.
Le PADD améliore certains aspects de la qualité des données, mais quelques lacunes sur le plan de la pertinence et de l'accessibilité ont été relevées.
Le PADD produit des données qui, selon de nombreux utilisateurs de données, répondent à leurs besoins. Néanmoins, des personnes clés et des utilisateurs de données sondés ont également signalé que la désagrégation devait aller au-delà des quatre groupes visés par l'EE et inclure en particulier la population 2ELGBTQI+ et des niveaux géographiques inférieurs Note de bas de page 11. Bien que la désagrégation des données en fonction de la population 2ELGBTQI+ et de niveaux géographiques inférieurs fasse partie des priorités du PADD, les projets axés sur des populations autres que les quatre groupes visés par l'EE n'auraient pas été priorisés. Des utilisateurs de données ont recommandé que Statistique Canada se concentre sur l'élaboration de méthodes d'estimation ou d'échantillonnage appropriées pour régler les préoccupations relatives à la protection des renseignements personnels et à la confidentialité qui contribuent aux lacunes qui persistent.
Les normes du PADD contribuent à la cohérence et à la comparabilité des données. Le PADD a favorisé l'approbation et l'adoption par le gouvernement fédéral de deux normes Note de bas de page 12 relatives aux données désagrégées, ainsi que l'approbation et l'adoption par l'organisme de normes liées à l'orientation sexuelle et au travail à la demande. Les efforts visant à améliorer la convivialité des normes ont notamment consisté à créer une page Web spéciale et à rendre les normes du PADD accessibles au moyen de l'interface de programmation d'application pour les données de référence en tant que service. Cependant, l'élaboration de normes est un processus complexe et long, et il faut qu'elles soient adoptées à l'extérieur de Statistique Canada si l'on veut assurer l'interopérabilité entre les organismes gouvernementaux et non gouvernementaux.
Normes statistiques
Pour remédier au manque d'uniformité dans l'utilisation des normes statistiques relatives aux données désagrégées à l'échelle de Statistique Canada et du gouvernement du Canada (GC), et pour répondre au besoin de communications, de produits et de services davantage axés sur l'utilisateur, le Centre des normes en matière de statistiques et de données (CNSD) de Statistique Canada a lancé plusieurs initiatives à l'appui du Plan d'action sur les données désagrégées. Ces initiatives donnent une orientation concernant les méthodes d'enquête, améliorent l'interopérabilité et prévoient une vaste mobilisation des parties prenantes internes et externes. De plus, le CNSD s'est attaché à accroître l'accessibilité des normes au moyen d'un site Web amélioré et de consultations auprès de groupes clés. En outre, l'équipe a mis au point des outils de formation pour aider les analystes et les gestionnaires d'enquête à appliquer efficacement ces normes.
Le CNSD a utilisé des processus, des structures de gouvernance et des outils établis, ainsi que des dépôts de normes de données et des réseaux de consultation, pour aider à mettre en place des normes statistiques clés dans l'ensemble du GC. Par exemple, il a élaboré une validation de principe au moyen de certaines variables liées à la qualité de vie pour diffuser des données désagrégées au niveau le plus bas possible tout en respectant la confidentialité et la qualité des données. De plus, des consultations menées auprès de plus de 300 groupes et personnes ont contribué à l'élaboration de cadres inclusifs de collecte de données. Ces démarches ont aidé à harmoniser les données sur le genre et l'orientation sexuelle dans diverses enquêtes et à peaufiner ces normes.
La priorité consiste maintenant à s'assurer d'un financement durable, à intégrer de nouvelles normes aux systèmes existants et à sensibiliser les parties prenantes à l'utilité de la normalisation, car l'adaptation des questions d'enquête dans les différents secteurs de compétence exige une attention particulière aux concepts sous-jacents pour des raisons d'uniformité.
Par ailleurs, le PADD a favorisé une plus grande accessibilité des données désagrégées et des produits analytiques en mettant à jour le Carrefour de statistiques sur le genre, la diversité et l'inclusion de Statistique Canada et en lançant le Centre de données municipales et locales, en diffusant un plus grand nombre de publications analytiques et de tableaux de données en ligne et dans le bulletin de diffusion officiel de Statistique Canada, Le Quotidien, et en faisant la promotion de nouvelles données et analyses désagrégées dans les médias sociaux. Certains utilisateurs de données ont déclaré que le PADD permet à un plus grand nombre d'organisations d'avoir accès à des données désagrégées parce que des données qu'on pouvait obtenir uniquement au moyen de demandes de rapport à recouvrement des coûts sont maintenant accessibles sur le site Web de Statistique Canada sans frais supplémentaires. Toutefois, moins de la moitié (35 %) des utilisateurs de données sondés (n=370) ont dit que l'accès à des données désagrégées de Statistique Canada était plutôt facile ou meilleur. Parmi les obstacles figuraient des problèmes de navigation sur le site Web, l'utilité limitée du carrefour pour des besoins complexes, le couplage limité des données avec des sources externes et la capacité interne restreinte des utilisateurs.
Il a été mentionné que les priorités liées à la souveraineté des données pouvaient nuire à l'objectif d'améliorer l'accès à des données désagrégées en recueillant et en intégrant des données d'autres sources. Des personnes clés ont reconnu que l'organisme travaille encore à élaborer son approche en matière de soutien à la souveraineté des données pour divers secteurs de compétence et diverses populations, mais elles continuaient de craindre que le partage de données avec l'organisme ne leur fasse perdre la maîtrise des données et de la façon dont elles sont utilisées. Pour répondre à cette préoccupation, des personnes clés ont recommandé que l'organisme continue de travailler avec d'autres intendants des données à déterminer la façon de partager les données tout en respectant les besoins et les engagements des parties concernées.
Le PADD renforce un changement culturel où l'on accorde la priorité aux données désagrégées et à l'analyse intersectionnelle en élargissant l'offre de données désagrégées et de produits analytiques connexes. Pour faire progresser le changement culturel à l'extérieur de l'organisme, il faudrait mettre davantage l'accent sur les efforts de sensibilisation et de formation.
Des personnes consultées au sein de l'organisme ont souligné que le PADD favorise un changement de culture. On peut le constater par l'attention accrue portée aux statistiques désagrégées et les plus amples analyses intersectionnelles dans les directions situées à l'extérieur du secteur 8, comme celles du Secteur de la statistique économique. Elles ont également mentionné que les données désagrégées sont prises en compte plus tôt dans le processus depuis la mise en œuvre du PADD.
Les résultats du sondage lié aux études de cas le confirment, puisque 78,3 % des répondants ont déclaré que l'organisme favorise un environnement où l'on mise sur l'horizontalité des travaux relatifs aux données désagrégées, tout en soulignant l'importance de l'analyse intersectionnelle et des perspectives longitudinales. Cependant, une proportion légèrement plus faible (61,7 %) des participants qui ont répondu à la question ont dit que l'accent est mis sur l'application de l'optique d'ACS Plus à l'ensemble des projets et des initiatives.
Un changement culturel au sein du gouvernement fédéral s'observait notamment par la demande accrue de données désagrégées chez les utilisateurs de données à l'échelle fédérale. Néanmoins, quelques personnes consultées ont fait remarquer que le changement culturel ne s'opère pas au même rythme dans chaque ministère. La littératie des données d'un ministère, son mandat de recherche et l'engagement de ses dirigeants semblent avoir une plus grande incidence sur son utilisation de données désagrégées.
Les utilisateurs de données consultés ont dit que le PADD favorise un virage culturel vers la priorisation de la collecte et de l'utilisation de données désagrégées et de l'ACS Plus. Toutefois, bon nombre d'entre eux ont souligné que ce virage s'est amorcé avant la mise en œuvre du PADD. Des utilisateurs de données ont également déclaré que, parce que Statistique Canada est perçu comme un chef de file en matière de données, la disponibilité accrue de données désagrégées et de produits analytiques connexes contribue à répandre et à solidifier ce changement culturel. Pour faire progresser davantage un changement culturel où la priorité est accordée à la collecte et à l'analyse de données désagrégées, certains utilisateurs de données ont recommandé d'accroître les efforts de sensibilisation et de formation auprès des utilisateurs de données autres qu'à l'échelle fédérale pour les aider à mieux comprendre les renseignements à leur disposition et la façon dont ils peuvent servir à leur travail.
Certains éléments probants préliminaires semblent indiquer que le PADD a une incidence positive sur les débats des utilisateurs de données entourant la prise de décisions, la recherche et les politiques, mais ces effets sont limités par la capacité des utilisateurs de données et des décideurs à comprendre et à utiliser les données désagrégées.
Alors que le PADD entame la dernière année de son financement sur cinq ans, certains signes de progrès vers l'atteinte de son résultat à long terme peuvent être observés. Parmi les utilisateurs de données sondés qui ont répondu à la question de savoir si les données désagrégées de Statistique Canada améliorent leurs débats entourant la recherche, la prise de décisions ou les politiques (n=340), 61 % ont déclaré qu'elles avaient une incidence positive. Cependant, les données probantes montrent également que certains utilisateurs de données sont encore en train de mesurer l'incidence globale des données désagrégées de Statistique Canada, comme en témoigne le fait qu'un peu moins du quart (23 %) des répondants ont dit ne pas savoir si les données amélioraient leur travail. Parmi les avantages particuliers qui découlent des données désagrégées de Statistique Canada, il y a le fait qu'elles permettent de combler ou de cerner les lacunes en matière d'information, de mettre en évidence des tendances ou des inégalités particulières, d'orienter les interventions ou les politiques et de cibler les ressources ou les recommandations.
Comme il a été mentionné, peu de personnes clés ont pu faire état de retombées concrètes liées au PADD sur leurs débats entourant la prise de décisions, la recherche ou les politiques. Les données désagrégées avaient une incidence positive sur la mise en œuvre et l'efficacité de l'ACS Plus dans les budgets fédéraux. Le résultat à long terme qui consiste en l'élaboration de lois, de politiques et de programmes de plus en plus équitables et inclusifs est limité par la capacité des utilisateurs de données et des décideurs à comprendre et à utiliser les données désagrégées et les produits analytiques correspondants. Des personnes clés ont déclaré que les petits secteurs de compétence, les organisations non gouvernementales et les employés du gouvernement n'ont souvent pas la capacité ou les ressources nécessaires pour comprendre et utiliser les données désagrégées, ce qui limitait l'incidence du PADD sur l'élaboration de politiques et de programmes. Pour combler ces lacunes en matière de capacité, il est notamment suggéré de mener des efforts de sensibilisation et de formation soutenus au sein et à l'extérieur du gouvernement fédéral, particulièrement auprès des dirigeants fédéraux.
On note une certaine préoccupation quant au fait que le résultat à long terme du PADD échappe à l'influence et au mandat de Statistique Canada.
Certaines préoccupations ont été soulevées quant au fait que le résultat à long terme du PADD qui consiste en des lois, des politiques et des programmes de plus en plus équitables et inclusifs ne relève pas du mandat de Statistique Canada. Bien que les activités du PADD soient principalement axées sur la multiplication des données désagrégées et des produits analytiques connexes, Statistique Canada a une influence limitée lorsqu'il s'agit de décider si, et comment, les données sont prises en compte dans l'élaboration des programmes et des politiques. La réalisation du résultat à long terme du PADD est considérée comme étant plutôt la responsabilité collective des dirigeants de l'ensemble du gouvernement fédéral. Toutefois, certaines personnes doutent si l'actuel Comité consultatif fédéral des SMA sur les données désagrégées constitue un mécanisme efficace pour faire progresser l'engagement qu'ont pris les dirigeants fédéraux d'appliquer les données désagrégées et l'analyse intersectionnelle.
Comment améliorer le programme
Recommandation 1
Le SCA du secteur 8 devrait veiller à renforcer la gouvernance du PADD afin de contribuer directement à l'obtention des résultats intermédiaires et finals de l'initiative au moyen des mesures suivantes :
mettre à jour le mandat des comités de surveillance du PADD afin d'énoncer clairement les responsabilités, surtout en ce qui concerne l'orientation stratégique à donner et l'atteinte des objectifs à moyen et à long terme du PADD;
axer les activités et les projets futurs sur la viabilité;
établir une communication efficace (p. ex. tirer parti des tables de gouvernance proposées) pour veiller à ce que les priorités, les mesures du rendement et les résultats attendus soient bien compris par le personnel, les principaux partenaires et les parties prenantes (p. ex. de façon régulière, au moyen d'un véritable dialogue).
Recommandation 2
Le SCA du secteur 8 devrait veiller à ce que les efforts de sensibilisation et de mobilisation soient exhaustifs et constants, afin que les besoins continus des utilisateurs de données, y compris ceux des groupes visés par l'EE, soient compris et qu'ils soient comblés par les données désagrégées et les produits analytiques connexes du PADD.
Réponse et plan d'action de la direction
Recommandation 1
Le SCA du secteur 8 devrait veiller à renforcer la gouvernance du PADD afin de contribuer directement à l'obtention des résultats intermédiaires et finals de l'initiative au moyen des mesures suivantes :
mettre à jour le mandat des comités de surveillance du PADD afin d'énoncer clairement les responsabilités, surtout en ce qui concerne l'orientation stratégique à donner et l'atteinte des objectifs à moyen et à long terme du PADD;
axer les activités et les projets futurs sur la viabilité;
établir une communication efficace (p. ex. tirer parti des tables de gouvernance proposées) pour veiller à ce que les priorités, les mesures du rendement et les résultats attendus soient bien compris par le personnel, les principaux partenaires et les parties prenantes (p. ex. de façon régulière, au moyen d'un véritable dialogue).
Réponse de la direction
La direction accepte la recommandation.
Le mandat des comités des DG, des SCA et des SMA sera révisé afin qu'y soit ajoutée la responsabilité concernant l'orientation stratégique à donner et à communiquer et l'atteinte des objectifs à moyen et à long terme du PADD.
Un plan annuel intégré sera élaboré, dans lequel sera donnée l'orientation stratégique de Statistique Canada relative au PADD et dans lequel sera énoncé le principe clé de la désagrégation des données. Il sera assorti d'un plan de travail détaillé servant à guider la mise en œuvre et la surveillance. Le plan annuel intégré englobera des considérations de viabilité (p. ex. des approches méthodologiques autres que le suréchantillonnage) et d'harmonisation avec les résultats à moyen et à long terme du PADD. Le Comité de gouvernance des DG recommandera l'approbation du plan annuel intégré au Comité directeur des SCA.
Le Comité des SMA fera un suivi des résultats du PADD et consignera la façon dont les données désagrégées ont servi à orienter la formulation des politiques ainsi que la mise en œuvre et l'évaluation des programmes d'autres ministères. Ces résultats feront partie du rapport annuel sur les réalisations de 2024-2025 publié par Statistique Canada.
On tirera parti des possibilités existantes de communication et de diffusion (p. ex. l'espace de collaboration de l'EFPC, les mécanismes de diffusion d'autres ministères) pour promouvoir, communiquer, mettre en valeur et mieux faire connaître les résultats, les pratiques exemplaires et les occasions de formation en matière de données désagrégées.
Produits livrables et échéancier
Mandat révisé et approuvé des comités des DG, des SCA et des SMA (septembre 2025).
Plan annuel intégré approuvé (octobre 2025, de manière continue par la suite) qui englobe un plan de travail détaillé et un cadre logique, ce qui comprend :
les objectifs à moyen et à long terme du PADD;
les indicateurs mesurables à utiliser pour suivre les progrès réalisés par rapport à ces objectifs;
une approche en matière de suivi des progrès réalisés par rapport à ces objectifs;
une explication claire de la façon dont on établira les priorités, en mettant l'accent sur la viabilité.
Rapport annuel sur les réalisations de 2024-2025 qui comprendra, pour la première fois, les répercussions et les résultats dont ont fait part d'autres ministères (décembre 2025).
Espace de collaboration solide et modernisé de l'EFPC où mettre en valeur les pratiques exemplaires, tirer parti des possibilités de formation de l'EFPC et accroître la sensibilisation (novembre 2025).
Recommandation 2
Le SCA du secteur 8 devrait veiller à ce que les efforts de sensibilisation et de mobilisation soient exhaustifs et constants, afin que les besoins continus des utilisateurs de données, y compris ceux des groupes visés par l'EE, soient compris et qu'ils soient comblés par les données désagrégées et les produits analytiques connexes du PADD.
Réponse de la direction
La direction accepte la recommandation.
On élaborera un plan de sensibilisation et de mobilisation pour établir la communication avec les partenaires et les parties prenantes du PADD, notamment en s'attachant à tirer parti des réseaux externes au niveau des SMA et des SCA (au sein et à l'extérieur du GC).
Ce plan peut comprendre l'organisation de séances de mobilisation ou d'enquêtes auprès des groupes visés par l'EE (et au-delà des quatre groupes visés par l'EE, selon les besoins et dans la mesure du possible).
Produits livrables et échéancier
Plan de sensibilisation et de mobilisation approuvé par le Comité consultatif fédéral des SMA sur les données désagrégées (avril 2026).
Annexe A : Questions et indicateurs d'évaluation
Questions et indicateurs d'évaluation
Questions d'évaluation
Indicateurs d'évaluation
1. Dans quelle mesure le Plan d'action sur les données désagrégées (PADD) est-il pertinent lorsqu'il s'agit de répondre aux besoins et de donner suite aux priorités du gouvernement fédéral, y compris ceux de Statistique Canada?
1.1 Mesure de la concordance entre les projets et les activités du PADD de Statistique Canada et a) les priorités stratégiques de l'organisme et b) les priorités pangouvernementales du PADD.
2. Dans quelle mesure la conception et l'exécution du PADD facilitent-elles l'atteinte des résultats escomptés?
2.1 Mesure dans laquelle la gouvernance du PADD assure de manière efficace une orientation stratégique, une surveillance et une reddition de comptes à tous les niveaux (soit au niveau du gouvernement fédéral, de l'organisme, du programme et des projets).
Mesure dans laquelle la structure de gouvernance assure une communication, une coordination et une collaboration efficaces aux différents niveaux.
Mesure dans laquelle des mécanismes efficaces d'établissement des priorités, de surveillance, de reddition de comptes et de correction de cap en temps opportun ont été mis en place à tous les niveaux.
2.2 Mesure dans laquelle des consultations visant à orienter les priorités et les projets ont été menées.
Nombre de consultations, selon la formule, le type d'utilisateurs prévus et l'exercice financier.
Degré d'efficacité des processus d'analyse des besoins et d'établissement de rapports à ce sujet à la suite des consultations.
Mesure dans laquelle les commentaires issus des consultations ont orienté les priorités et les projets du PADD.
2.3 Mesure dans laquelle les activités du PADD ont pris appui sur l'infrastructure, les ressources et les capacités existantes (compétences, partenariats) ou les ont améliorées, ce qui a permis de réduire au minimum les coûts et les efforts supplémentaires.
2.4 Mesure dans laquelle on a pris des mesures destinées à assurer la viabilité des nouvelles activités s'inscrivant dans les opérations courantes de l'organisme.
3. Dans quelle mesure le PADD progresse-t-il vers les résultats escomptés à court, à moyen et à long terme?
3.1 Mesure dans laquelle les obstacles internes et externes à l'atteinte des résultats attendus ont été cernés et atténués.
3.2 Étendue des progrès vers l'obtention des résultats à court terme.
Mesure dans laquelle le PADD a contribué à mieux faire connaître et comprendre le besoin de données désagrégées et la nécessité de l'Analyse comparative entre les sexes Plus.
Mesure dans laquelle le PADD a contribué à améliorer la qualité des données et à combler les lacunes en matière d'information.
Éléments démontrant un accès accru ou amélioré aux données désagrégées.
Éléments démontrant une planification accrue ou améliorée relative aux données désagrégées ainsi que la collecte, l'analyse, la production et la diffusion de données désagrégées de 2020-2021 à 2024-2025 (année partielle).
3.3 Étendue des progrès vers l'obtention des résultats à moyen terme.
Mesure dans laquelle le PADD a contribué à un changement de culture où l'on accorde la priorité à l'utilisation de données désagrégées existantes, à la collecte de nouvelles données désagrégées et, dans la mesure du possible, à des analyses intersectionnelles pour répondre aux besoins des décideurs et d'autres utilisateurs de données.
3.4 Étendue des progrès vers l'obtention des résultats à long terme.
Mesure dans laquelle le PADD a contribué à ce jour à l'amélioration des débats entourant la prise de décisions, la recherche ou les politiques en assurant une représentation plus détaillée de diverses populations, de leur expérience et de leur environnement.
Mesure dans laquelle le PADD a contribué à l'établissement de normes propres aux données désagrégées.
Annexe B : Échelle de quantification des entrevues
Les réponses obtenues lors des entrevues sont quantifiées et catégorisées dans le présent rapport à l'aide de l'échelle illustrée dans le tableau ci-dessous.
Échelle de quantification des entrevues
Terme
Définition
Un
Utilisé lorsqu'un participant a fourni la réponse.
Peu
Utilisé lorsque de 4 % à 15 % des participants ont répondu de façon semblable. La teneur de la réponse a été exprimée par ces participants, mais pas par d'autres participants.
Certains
Utilisé lorsque de 16 % à 45 % des participants ont répondu de façon semblable.
Environ la moitié
Utilisé lorsque de 46 % à 55 % des participants ont répondu de façon semblable.
La plupart ou une majorité
Utilisé lorsque de 56 % à 89 % des participants ont répondu de façon semblable.
Presque tous
Utilisé lorsque de 90 % à 99 % des participants ont répondu de façon semblable.
Tous
Utilisé lorsque 100 % des participants ont répondu de façon semblable.
Si vous avez participé à l'Enquête canadienne sur les mesures de la santé (ECMS) de janvier 2023 à décembre 2024 nous voulons maintenant obtenir votre consentement éclairé pour permettre l'utilisation des échantillons biologiques que vous avez fournis pendant l'enquête aux fins de projets de recherche génétique en santé. Votre consentement permettra de soutenir d'importantes recherches sur les résultats en matière de santé et leurs liens à l'information génétique humaine.
Voici ce que vous devez savoir :
Vos échantillons et la génétique
L'ADN (acide désoxyribonucléique) est la molécule qui contient les informations génétiques et qui se trouve dans de nombreuses parties du corps, comme les cellules, la peau et le sang. L'ADN peut être extrait de votre échantillon de sang afin de mieux comprendre ce qui rend les gens malades et ce qui les maintient en bonne santé. Les informations génétiques tirées à partir de vos échantillons peuvent être utilisées dans la recherche et partagées sous forme de données regroupées provenant de plusieurs personnes (données agrégées ou regroupées). Les renseignements liés à vos échantillons et à vos données génétiques ne seront ni utilisés ni publiés de façon individuelle.
Qu'est-ce que la recherche génétique?
La recherche génétique permet d'étudier l'ADN humain pour comprendre l'incidence des gènes et des facteurs environnementaux sur la santé et les maladies. Cette recherche peut nous aider à découvrir les causes des maladies, à améliorer leur détection et leur traitement, et même à les prévenir.
Protection de vos données
Afin de protéger votre vie privée, chaque échantillon biologique portera un code-barres au lieu de votre nom ou de vos renseignements personnels. Une fois prélevés, vos échantillons seront congelés et stockés en toute sécurité dans la Biobanque de Statistique Canada, située au Laboratoire national de microbiologie de l'Agence de la santé publique du Canada. Cette installation sécurisée respecte les normes internationales et applique des mesures de sécurité strictes pour veiller à ce que le risque que quelqu'un vous identifie à partir de vos échantillons soit très faible.
Seuls les employés autorisés de Statistique Canada peuvent accéder à vos renseignements dans le cadre de leur travail. Un petit nombre d'employés peuvent établir un lien entre le code-barres de votre échantillon et vos renseignements personnels, lesquels sont conservés séparément à notre bureau principal. Personne à l'extérieur de Statistique Canada n'aura accès à vos renseignements personnels.
Les chercheurs autorisés peuvent utiliser vos échantillons pour la recherche, mais seulement s'ils prennent les mesures suivantes :
faire une demande d'accès aux échantillons;
obtenir l'approbation du comité consultatif de la Biobanque de Statistique Canada.
Ce processus garantit que vos renseignements sont toujours protégés. L'approbation comprend :
une demande de projet de recherche soumise à Statistique Canada;
une évaluation par un comité de scientifiques, d'experts et d'éthiciens afin de s'assurer que la recherche respecte toutes les lignes directrices.
Toutes les recherches en santé sont surveillées de près par Santé Canada, le Comité d'éthique de la recherche de l'Agence de la santé publique du Canada, le Commissariat à la protection de la vie privée du Canada et le comité d'éthique de l'établissement du chercheur. Cela garantit que la recherche suit les lignes directrices en matière d'éthique tout en protégeant votre vie privée.
Statistique Canada observe des règles rigoureuses en matière de protection de la vie privée en vertu de la Loi sur la statistique. Les résultats publiés de la recherche ne présenteront que des données regroupées provenant de plusieurs personnes, et aucun renseignement personnel ou qui permet de vous identifier ne sera divulgué.
Votre droit de retrait
Si vous ne souhaitez plus participer à une partie de cette enquête, y compris à la recherche génétique, vous pouvez vous retirer à tout moment. Pour retirer vos échantillons génétiques de la recherche actuelle ou future, vous pouvez envoyer une demande écrite par courriel à statcan.biobankinfo-infobiobanque.statcan@statcan.gc.ca. Veuillez indiquer votre nom complet, la date approximative et l'adresse de votre domicile au moment de votre visite au centre d'examen temporaire ainsi que votre date de naissance. Ces renseignements seront utilisés uniquement pour s'assurer que les bons échantillons sont retirés et dûment détruits. Veuillez noter que les données qui ont déjà été utilisées dans le cadre de recherches et qui ont été publiées avant votre demande de retrait ne peuvent pas être supprimées.
La recherche génétique peut aider à relever les gènes liés à certaines maladies. Grâce aux avancées dans ce domaine, les chercheurs ont découvert et continuent de découvrir des gènes ou des variations génétiques associés à un risque accru de développer certaines maladies. Lors de recherches génétiques futures qui utilisent vos échantillons biologiques, si des chercheurs découvrent des informations génétiques qui pourraient avoir une incidence sur votre santé, celles-ci ne vous seront pas communiquées, ni à votre médecin. Vos échantillons seront uniquement utilisés à des fins de recherche et les résultats n'auront pas d'incidence sur vos soins médicaux. En consentant à la conservation et à l'utilisation de vos échantillons pour la recherche génétique, vous acceptez de ne recevoir aucun résultat génétique personnel ni aucun renseignement sur votre santé.
Recherche génétique à l'échelle individuelle
L'ADN est comme un gigantesque livre d'instructions pour votre corps, qui guide sa croissance, son développement et son fonctionnement. Les chercheurs peuvent le lire en faisant appel au séquençage de l'ADN, qui leur permet d'obtenir des renseignements sur vos traits génétiques, sur les risques de contracter certaines maladies et sur d'autres caractéristiques liées à la santé. Pour ce cycle de l'ECMS, la publication des résultats individuels des recherches génétiques ne sera pas autorisée avec vos échantillons.
Recherche génétique à l'échelle de la population
Lorsque les données génétiques sont utilisées à l'échelle de la population, vos résultats sont combinés à ceux d'autres participants à l'ECMS. Cela signifie que vos renseignements personnels et vos résultats individuels ne sont pas inclus. Toutes les données génétiques qui pourraient révéler votre identité ou celle d'autres participants sont retirées avant la publication des résultats. En résumé :
Vos résultats en matière d'ADN feront partie de résumés statistiques (par exemple, pour montrer la prévalence de certains traits génétiques ou de certaines maladies).
Vos données génétiques seront combinées avec celles des nombreux autres participants, sans inclure de renseignements personnels.
Les données partagées dans les publications de recherche ne pourront pas être attribuées à une personne en particulier, garantissant une forte protection de la vie privée.
L'objectif de cette recherche est de déterminer les tendances et les relations au sein de grands groupes de personnes afin d'aider les scientifiques à mieux comprendre la génétique et les maladies.
Veuillez utiliser le code d'accès sécurisé inclus dans l'invitation que vous avez reçue de Statistique Canada pour accéder à notre portail Web sécurisé et donner votre consentement.