Les informations archivées sont fournies aux fins de référence, de recherche ou de tenue de documents. Elles ne sont pas assujetties aux normes Web du gouvernement du Canada et n'ont pas été modifiées ou mises à jour depuis leur archivage. Pour obtenir cette information dans un autre format, veuillez communiquer avec nous.
Carrefour de l'Explorateur géospatial des statistiques canadiennes
L'Explorateur géospatial des statistiques canadiennes permet aux utilisateurs de découvrir les données géospatiales de Statistique Canada jusqu'au plus petit niveau de détail disponible, l'aire de diffusion.
StatCan et la COVID-19 : Des données aux connaissances, pour bâtir un Canada meilleur
Une série d'articles sur divers sujets qui traitent des répercussions de la COVID-19 sur le plan socio-économique. De nouveaux articles seront diffusés de façon périodique.
Le début de la pandémie de COVID-19 a contraint de nombreuses entreprises canadiennes à modifier leur modèle d'affaires pour s'adapter aux restrictions économiques et à la demande accrue de biens et services en ligne. À l'aide des données de l'Enquête sur la technologie numérique et l'utilisation d'Internet de 2019 et 2021, cet article met en évidence certains changements apportés aux stratégies de commerce électronique des entreprises canadiennes pendant la pandémie.
Cette étude porte sur les établissements de soins infirmiers et les résidences pour aînés en 2021, en fournissant des renseignements préliminaires sur ces établissements et les résidents de ces établissements dans toutes les régions du Canada. Les concepts abordés comprennent les pratiques et protocoles en matière de prévention et de contrôle des infections (PCI) et les changements apportés aux établissements en réponse directe à la pandémie de COVID-19.
Cette étude analyse la mortalité COVID-19 en 2020 parmi les groupes racisés au Canada et leurs associations avec le revenu. Les résultats sont basés sur la cohorte santé et environnement du recensement canadien (CSERCan) qui a combiné le formulaire long du recensement de 2016 avec la base de données des statistiques de l'état civil canadiennes sur les décès de 2016 à 2020.
Nous restons au service des Canadiens tout en traçant le chemin de la reprise
Alors que nous traversons ensemble cette période sans précédent, l'importance de fournir des statistiques fiables aux Canadiens devient plus évidente que jamais. Les répercussions sociales et économiques de la pandémie de COVID-19 ont alimenté une demande extraordinaire de données en temps réel et de grande qualité sur la population, la société et l'économie du Canada. Pour répondre à cette demande, Statistique Canada a accéléré la collecte de données et la diffusion de renseignements relatifs aux effets de la COVID-19 sur les entreprises et les particuliers.
L'Enquête sociale générale (ESG) sur la sécurité des Canadiens (victimisation) recueille des données sur les expériences des répondants en matière de crimes signalés et non signalés, de violence familiale et de perception de l'application de la loi. Ces données sont recueillies tous les cinq ans dans les provinces et les territoires à l'aide de l'autodéclaration électronique, de suivis téléphoniques et, dans les territoires, d'interviews sur place pour le dernier cycle, en 2019.
Le taux de réponse à l'ESG de 2019 est inférieur aux taux d'autres enquêtes sociales générales et enquêtes sur la victimisation d'autres pays. Toutefois, cela peut s'expliquer, du moins en partie, par les méthodes de collecte (autodéclaration électronique et collecte par téléphone au Canada, et interviews sur place dans les autres pays).
Statistique Canada a appliqué des procédures rigoureuses de traitement et de validation des données afin de vérifier que le faible taux de réponse n'avait pas nui de façon importante à la qualité des données. Ces procédures, qui comprenaient la vérification, la pondération et la comparaison des données avec celles des cycles précédents et avec les résultats d'autres enquêtes, ont permis de faire en sorte que les données produites soient représentatives de la population canadienne et qu'elles soient adéquates à leur utilisation.
Introduction
L'Enquête sociale générale (ESG) de 2019 sur la sécurité des Canadiens (victimisation) est le septième cycle du genre. Le premier a eu lieu en 1988, et l'exercice se répète tous les cinq ans depuis lors. L'enquête a fait l'objet de nombreuses révisions; la version actuelle est une enquête d'une durée de 45 minutes (en moyenne) qui permet de recueillir des données sur :
les perceptions de la criminalité, de la sécurité et de l'application de la loi;
les efforts déployés pour se protéger de la criminalité;
les expériences en matière de criminalité et de violence entre partenaires intimes;
les antécédents de négligence et de mauvais traitements à l'égard d'enfants;
la consommation d'alcool et de drogues, l'itinérance et le bien-être économique;
les expériences en matière de discrimination.
Ces données ont été recueillies en même temps que diverses variables démographiques. Les variables de revenu ont été extraites des données fiscales des répondants.
Les données ont été publiées dans deux fichiers : le fichier principal et le fichier d'incidents. Le fichier d'incidents comprend des données relatives à des crimes précis, non commis par un conjoint ou partenaire actuel ou précédent, dont le répondant a été victime au cours des douze mois précédant la réalisation de l'enquête. Le fichier principal comprend toutes les autres données, dont celles en matière de violence exercée par un conjoint ou partenaire actuel ou précédent.
Le taux de réponse à l'ESG de 2019 (victimisation) était de 36,4 % pour les provinces (41,0 % pour l'échantillon principal, y compris le suréchantillon de l'Alberta, et 21,2 % pour le suréchantillon d'autochtones), ce qui est inférieur aux taux des cycles précédents sur la victimisation et des autres cycles de l'ESG. Pour faire face à ce faible taux de réponse, Statistique Canada a appliqué des méthodes statistiques rigoureuses et des pratiques de validation approfondies aux étapes de la production et de la diffusion des estimations de l'ESG afin de limiter le risque de biais statistique (veuillez consulter les sections « Réduction des erreurs et des biais » et « Validation des données » pour en savoir plus). À la lumière de ces ajustements et techniques statistiques, Statistique Canada a jugé que les données de l'ESG de 2019 étaient adéquates à leur utilisation. Néanmoins, les utilisateurs de données doivent tenir compte du fait que les estimations pour certains types de crimes déclarés par une petite partie de l'échantillon, ou pour de petites zones géographiques, peuvent donner lieu à des erreurs d'échantillonnage plus importantes et à des risques de biais plus élevés.
Cette note technique fournit des renseignements sur la qualité des données de l'ESG de 2019 ainsi que sur les diverses méthodes d'ajustement et les diverses stratégies de validation utilisées par Statistique Canada pour faire en sorte que ces données soient adéquates à leur utilisation.
Collecte des données
Pour la première fois, les répondants avaient la possibilité de répondre en ligne à l'enquête sur la victimisation. Les ménages sélectionnés dont les numéros de téléphone était associé à une adresse ont reçu par la poste une lettre d'invitation indiquant qui, dans le ménage, avait été choisi pour répondre à l'enquête; la lettre comportait également un code unique pour se connecter et répondre à l'enquête en ligne. On a ensuite appelé les répondants qui n'ont pas répondu à l'enquête avant la date limite et les ménages dont les numéros de téléphone n'étaient pas associés à une adresse pour qu'ils répondent aux questions de l'intervieweur par téléphone. Cette méthode de collecte a été utilisée à l'échelle des provinces et dans les capitales territoriales. Les ménages des régions territoriales en dehors des capitales ainsi que les ménages des capitales territoriales qui n'ont pas répondu à la collecte en ligne ou par téléphone ont été invités à répondre à l'enquête dans le cadre d'une interview sur place au cours de laquelle l'intervieweur a utilisé un ordinateur pour enregistrer leurs réponses.
La collecte dans les provinces a eu lieu du 15 avril 2019 au 31 mars 2020. La collecte par téléphone a pris fin le 15 mars 2020, lorsque les centres d'appels de Statistique Canada ont fermé en raison de l'éclosion de COVID-19. Toutefois, les questionnaires en ligne pouvaient encore être complétés jusqu'au 31 mars.
Dans les territoires, la collecte par téléphone et celle en ligne ont commencé le 3 juin 2019, on est passé aux interviews sur place (connues sous le nom d'interviews sur place assistées par ordinateur) le 9 septembre 2019, et la collecte a pris fin comme prévu le 13 mars 2020.
Dans les provinces, près de 60 % des répondants ont répondu à l'enquête à l'aide du questionnaire en ligne, ce qui représente une augmentation par rapport aux cycles précédents de l'ESG. Environ la moitié des personnes interrogées dans les territoires ont répondu à l'enquête au cours d'interviews sur place tandis que l'autre moitié était répartie de manière égale entre la collecte par téléphone et la collecte en ligne.
Taux de réponse
Le taux de réponse global des provinces était de 36,4 %. Dans les territoires, il était de 57,0 %.
Le nombre de répondants visé pour l'ESG de 2019 était de 25 035 tandis que le nombre réel de répondants était de 20 454. Dans les territoires, l'objectif était de 2 080 alors que le nombre réel de répondants était de 1 958.
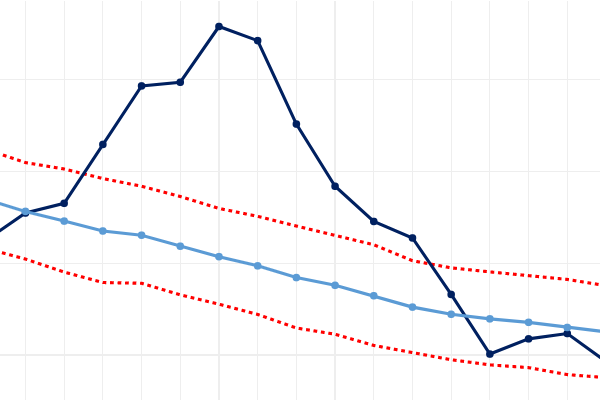
Le graphique ci-dessous présente le taux de réponse selon la province ou la région (groupes de provinces de petite taille) et le taux de réponse dans les territoires (regroupés). Il sépare également, dans les provinces, l'échantillon principal du suréchantillon autochtone. Comme on peut le constater, la partie principale de l'échantillon provincial a enregistré des taux de réponse supérieurs dans l'ensemble, et le taux le plus élevé, soit 52,2 %, a été observé au Québec. Il y a peu de variation entre les provinces ou régions quant aux taux de réponse du suréchantillon d'autochtones, qui vont de 18,1 % au Québec à 23,8 % dans les Prairies.
Description Figure 1 – Taux de réponse selon la province ou la région
Taux de réponse selon la province ou la région
Province ou région
Échantillon principal (%)
Suréchantillon autochtone (%)
Atlantique
38,0
19,2
Québec
52,2
18,1
Ontario
45,0
20,4
Prairies
35,2
23,8
Colombie-Britannique
43,8
22,1
Territoires
57,0
Comparaison du taux de réponse avec ceux des autres cycles de l'Enquête sociale générale
Les taux de réponse à l'ESG ont eu tendance à baisser au cours des 10 derniers cycles. L'un des facteurs contributifs est le changement de la base de sondage utilisée dans le cadre de l'ESG qui, au fil du temps, pourrait avoir eu un effet sur les taux de réponse. Les taux de réponse de 2013 à aujourd'hui ne sont pas directement comparables à ceux de 2012 et des années précédentes. En 2013, une nouvelle base de sondage a été utilisée pour sélectionner l'échantillon, ce qui a nécessité des modifications quant à la façon de calculer les taux de réponse. La nouvelle base comprend également les ménages qui n'ont que des téléphones portables, ce qui n'était pas le cas de l'ancienne base. Ce paramètre est essentiel, car le nombre de foyers ne disposant que de téléphones portables ne cesse d'augmenter, et la couverture n'a cessé de diminuer par rapport à la base précédente. L'ajout de ces ménages à la base de sondage a permis une couverture plus complète des ménages canadiens. Même si cet ajout a permis d'améliorer la couverture en augmentant le nombre de foyers qui pouvaient participer à l'enquête, ces foyers ont également été plus difficiles à joindre. L'une des difficultés est que les téléphones portables sont liés à une personne et non à un ménage, ce qui rend la tâche de joindre le répondant sélectionné plus difficile si cette personne n'est pas celle à laquelle le téléphone portable est rattaché (et si le propriétaire du téléphone ne veut pas fournir les coordonnées nécessaires). Les difficultés à joindre les ménages contribuent à la baisse des taux de réponse.
Les taux de réponse présentés dans le graphique ci-dessous représentent uniquement la collecte provinciale. Seuls les taux provinciaux de victimisation sont utilisés dans cette section, car les autres cycles de l'ESG ne recueillent pas de données dans les territoires. Il convient de souligner que, sans le suréchantillon d'autochtones, le taux de réponse provincial relatif à l'enquête sur la victimisation (41,0 %) serait semblable à celui de l'enquête sur le don, le bénévolat et la participation (41,9 %).
Description Figure 2 – Taux de réponse à l’Enquête sociale générale
Taux de réponse à l’Enquête sociale générale
Enquête
Taux de réponse (%)
Victimisation (2009)
61,6
Emploi du temps (2010)
55,2
Famille (2011)
65,8
Soins données et reçus (2012)
65,7
Identité sociale (2013)
48,0
Don, bénévolat et participation (2013)
46,0
Victimisation (2014)
52,9
Emploi du temps (2015)
38,0
Canadiens au travail et à la maison (2016)
50,8
Famille (2017)
52,4
Soins données et reçus (2018)
52,8
Don, bénévolat et participation (2018)
41,9
Victimisation (2019)
36,4
Pour l'échantillon territorial (taux de réponse = 57 %), la comparabilité du taux de réponse au fil du temps est influencée par la capacité de résolution des cas en cours de collecte. Tout d'abord, l'ESG de 2019 a sélectionné les ménages qui ont été récemment inclus dans l'Enquête sur la population active (c'est-à-dire les ménages dont les coordonnées ont été récemment confirmées); ainsi, la probabilité de prise de contact a été optimisée. De même, toutes proportions gardées, plus d'unités ont été traitées au cours d'interviews sur place assistées par ordinateur en 2019 et en 2014 que lors des cycles précédents, ce qui a permis de disposer d'un potentiel beaucoup plus important pour mener à bien les interviews et résoudre les cas.
Comparaison du taux de réponse avec ceux d'enquêtes internationales sur les victimes d'actes criminels
Le graphique ci-dessous présente les taux de réponse à des enquêtes similaires sur la victimisation menées dans d'autres pays. Dans le présent rapport, seules les enquêtes menées dans des nations francophones ou anglophones ont été retenues à titre de comparaison.
Description Figure 3 – Enquêtes internationales sur les victimes d’actes criminels : taux de réponse
Enquêtes internationales sur les victimes d’actes criminels : taux de réponse
Pays
Taux de réponse (%)
Australie (2016)
68,1
Nouvelle-Zélande (2014)
81,0
Angelterre et pays de Galles (2020)
64,0
Écosse (2018)
63,4
États-Unis (2019)
71,0
France (2018)
67,9
Canada (provinces) (2019)
41,0
Canada (territoires) (2019)
57,0
Comme on peut le constater, les taux de réponse à l'ESG de 2019 sont inférieurs à ceux des autres enquêtes sur la victimisation en français et en anglais. Toutefois, il est important de souligner que la méthode de collecte peut jouer un rôle important dans les différences de taux. L'ESG de 2019 s'est appuyée sur l'autodéclaration électronique et les suivis téléphoniques pour recueillir les données dans les provinces. L'absence d'interaction personnelle avec les intervieweurs et la possibilité pour les répondants de filtrer les personnes qui les appellent à l'aide de l'identification du numéro peuvent permettre aux répondants potentiels d'éviter plus facilement la demande d'interview. Les mêmes méthodes de collecte ont été utilisées dans les capitales territoriales, mais des interviews sur place ont également été menées dans les régions plus éloignées. Chacun des autres pays figurant dans le graphique ci-dessus a recueilli des données au moyen d'interviews sur place. La France et l'Australie ont également utilisé, pour des modules précis ou à la demande du répondant, l'autodéclaration électronique.
Le taux de réponse du Canada est plus proche de ceux observés à l'échelle internationale lorsque l'on compare uniquement les méthodes de collecte sur place. Malgré cela, la collecte dans les territoires est un défi en raison de leur population plus petite que celles des provinces. Pour garantir la représentativité de l'échantillon, il faut demander à un pourcentage élevé de la population de participer. Dans les territoires les moins peuplés, cela signifie que les mêmes répondants peuvent être sélectionnés pour plusieurs enquêtes dans un court laps de temps, ce qui peut entraîner une lassitude des répondants et donc une baisse des taux de réponse.
Réduction des erreurs et des biais
Il existe deux types d'erreurs d'enquête : les erreurs d'échantillonnage et les erreurs non dues à l'échantillonnage. Une erreur d'échantillonnage découle de l'estimation d'une caractéristique de la population au moyen de la mesure d'une partie de la population uniquement plutôt que de l'ensemble de celle-ci. Les erreurs non dues à l'échantillonnage comprennent les erreurs dues à la non-réponse, qui peuvent mener à des estimations biaisées lorsque les caractéristiques des répondants et des non- répondants sont différentes.
En ce qui concerne les erreurs non dues à l'échantillonnage, diverses mesures sont en vigueur à Statistique Canada pour réduire au minimum le biais dans les enquêtes. Par exemple, dans le cas de l'ESG de 2019, on a déployé des efforts importants pour réduire le biais en utilisant un questionnaire éprouvé, en faisant appel à des intervieweurs qui ont reçu une formation spécialisée sur le sujet de la victimisation et sur la façon d'aborder les contenus sensibles, et en effectuant un suivi auprès des ménages qui n'ont pas répondu initialement à l'enquête.
De plus, une méthodologie éprouvée a été utilisée pour compenser le risque de biais dû à la non-réponse et pour faire en sorte que les données de l'ESG de 2019 permettent de fournir des estimations de qualité aux échelles nationale et régionale (Atlantique, Québec, Ontario, Prairies, Colombie-Britannique, territoires).
La principale méthode utilisée pour réduire le biais dû à la non-réponse de l'ESG de 2019 a consisté en une série d'ajustements aux poids de l'enquête afin de tenir compte autant que possible de la non-réponse. Pour tous les cycles de l'ESG, les ajustements de poids utilisent des caractéristiques connues des non-répondants, qui proviennent de la base de sondage par exemple, pour créer des groupes de réponses homogènes qui sont utilisés pour ajuster les poids de sondage initiaux pour la non-réponse. Les sources de données administratives sont également utilisées pour fournir des renseignements utiles sur les ménages non-répondants et pour réduire le potentiel de biais dû à la non-réponse.
Comme c'est le cas pour la plupart des enquêtes auprès des ménages, une fois que tous les ajustements de poids relatifs à la non-réponse présentés ci-dessus ont été effectués pour l'ESG de 2019, une dernière étape de pondération a été appliquée pour ajuster les poids aux chiffres de population connus des provinces selon le groupe d'âge et le sexe. Ce calage des poids a permis de veiller à ce que les chiffres de population connus soient respectés pour les principales variables démographiques lorsque des données pondérées étaient utilisées. Par exemple, même si la non-réponse était plus élevée dans les Prairies, l'étape de calage a garanti que la population des Prairies était représentée avec exactitude lorsque les poids de l'enquête étaient utilisées pour produire des estimations. Enfin, des analyses supplémentaires ont été effectuées sur les poids finaux pour examiner la distribution, les valeurs aberrantes et l'effet de plan.
Validation des données
Une fois l'ensemble définitif des poids pour les provinces (y compris le suréchantillon) et des poids pour les territoires pour l'ESG de 2019 dérivé, les estimations de l'enquête ont été validées conformément aux normes de Statistique Canada en matière de validation des données et d'assurance de la qualité. On a examiné les estimations clés aux échelles nationale, provinciale et territoriale en les comparant à des normes internes et externes. Cet exercice a permis d'évaluer l'adéquation des données à leur utilisation et le potentiel biais dû à la non-réponse, qui se produit dans les enquêtes statistiques si les réponses des répondants diffèrent des réponses potentielles de ceux qui n'ont pas répondu.
L'exercice de validation consistait en la comparaison des caractéristiques démographiques des répondants avec celles du Recensement de la population de 2016, de l'Enquête sur la sécurité dans les espaces publics et privés de 2018, et de l'ESG de 2014 sur la sécurité des Canadiens. Il comparait également les données relatives à certains indicateurs de criminalité, de violence familiale, de mauvais traitements infligés aux enfants, d'itinérance et d'incapacité. Dans l'ensemble, les résultats pondérés de l'ESG de 2019 étaient semblables à ceux des autres sources de données. Cependant, certaines différences ont été soulignées; elles ont été attribuées à un effet du mode d'enquête. De plus amples renseignements à ce sujet sont présentés dans la section suivante.
En raison ses pratiques rigoureuses en matière de traitement du biais dû à la non-réponse, de calage des poids d'enquête et de validation des données, Statistique Canada a confiance en la qualité des données diffusées qui sont tirées de l'ESG de 2019 et assure que les données soient adéquates à leur utilisation. Cependant, la qualité des estimations pour certains groupes de population tels que la population autochtone et les petites régions géographiques peut être affectée par le taux de réponse plus faible que prévu.
Effet du mode d'enquête
L'ESG de 2019 sur la sécurité des Canadiens (victimisation) offrait pour la première fois aux répondants la possibilité de répondre en ligne à l'enquête. Cette nouvelle méthode de collecte des données répondait à la nécessité, pour l'organisme, de s'adapter à l'évolution de l'utilisation de la technologie et de tenir compte des contraintes de temps avec lesquelles doivent composer les Canadiens. En ayant recours à des modes de collecte de données par téléphone et par Internet dans les provinces, l'ESG de 2019 a offert aux répondants une plus grande souplesse et une plus grande commodité pour fournir des renseignements clés et essentiels à Statistique Canada.
Il est impossible de déterminer avec certitude, d'une part, si les différences dans une variable sont attribuables à un changement réel dans la population ou à des changements de la méthodologie d'enquête et, d'autre part, dans quelle mesure elles le sont. Cependant, il y a des raisons de penser que l'utilisation d'un questionnaire électronique peut avoir une incidence sur les estimations; cette incidence est appelée l'effet de mode. Plusieurs études ont montré que les questions présentant une désirabilité sociale, par opposition aux questions factuelles, sont plus à risque. Des observations similaires ont été faites au sujet de l'ESG de 2019 dans les provinces. Par exemple, l'ESG de 2019 présente un pourcentage plus faible de répondants qui ont déclaré avoir subi des violences psychologiques ou une exploitation financière de la part d'un conjoint ou d'un partenaire actuel ou ancien que l'ESG de 2014. L'ESG de 2019 présente également un pourcentage plus faible de répondants qui ont déclaré avoir subi des violences physiques ou sexuelles de la part d'un conjoint ou d'un partenaire actuel, avoir fait l'objet de pratiques parentales sévères ou avoir subi de mauvais traitements quand ils étaient enfants que l'ESG de 2014.
Il est possible que les différences soient dues à des raisons autres que l'effet de mode, comme un biais de sélection, un biais dû à la non-réponse ou des erreurs non dues à l'échantillonnage. À chaque étape du traitement, de la vérification et de la diffusion, des efforts considérables ont été déployés pour produire des données aussi détaillées que possible et pour faire en sorte que les estimations publiées soient de bonne qualité, conformément aux normes de Statistique Canada. Cependant, en raison de ces changements, il n'est pas conseillé de comparer les résultats de l'ESG de 2019 à ceux des cycles précédents; à tout le moins, ces comparaisons doivent être accompagnées d'un avertissement.
Déclaration d'adéquation des données à leur utilisation
Les méthodes rigoureuses utilisées pour réduire les erreurs et les biais ainsi que pour valider les données permettent à Statistique Canada d'avoir confiance en la qualité des données diffusées. À ce titre, les données de l'ESG de 2019 sont jugées adéquates à leur utilisation.
Statistique Canada a traité le biais potentiel dû à la non-réponse en effectuant des ajustements de poids à l'aide des caractéristiques connues des non-répondants et en calant les poids de l'enquête avec des chiffres de population connus pour les principales variables démographiques. L'organisme a également validé les principales estimations de l'enquête aux échelles nationale, provinciale et territoriale par rapport à d'autres sources de données, conformément à ses propres normes quant à la validation des données.
En appliquant un ajustement de non-réponse et un calage appropriés aux poids de l'enquête, et en validant les principales estimations de l'enquête par rapport à plusieurs autres sources de données, Statistique Canada a voulu faire en sorte que les données de l'ESG de 2019 soient adéquates à leur utilisation. Cependant, la qualité des estimations pour certains groupes de population tels que la population autochtone et les petites régions géographiques peut être affectée par le taux de réponse plus faible que prévu.
Le présent module fournit un résumé concis de certains événements économiques canadiens et de faits nouveaux survenus sur le marché international et les marchés financiers, selon le mois civil. L'objectif du module est de fournir des renseignements contextuels visant à guider les utilisateurs des données économiques publiées par Statistique Canada. En faisant état des principaux événements ou faits nouveaux, Statistique Canada ne laisse pas entendre que ceux-ci ont une incidence importante sur les données économiques publiées au cours d'un mois de référence en particulier.
Tous les renseignements présentés ici sont obtenus à partir de sources de nouvelles et d'information publiques, et ils ne comprennent pas les renseignements protégés qui sont fournis à Statistique Canada par les répondants aux enquêtes.
Ressources
ARC Resources Ltd., établie à Calgary, a annoncé avoir conclu une entente définitive avec Shell plc du Royaume-Uni et Shell Canada Limited selon laquelle Shell avait accepté d'acquérir toutes les actions ordinaires émises et en circulation d'ARC dans le cadre d'une transaction en espèces et en actions évaluée à environ 22 milliards de dollars, y compris la dette nette comptabilisée. Arc a déclaré que la transaction devrait se conclure au cours de la deuxième moitié de 2026, sous réserve de l'approbation des actionnaires et des tribunaux, ainsi que des approbations réglementaires applicables, notamment les approbations requises en vertu de la Loi sur la concurrence (Canada), de la Loi surInvestissement Canada, de la Loi sur les transports au Canada, et de la Hart-Scott-Rodino Antitrust Improvements Act de 1976.
Enbridge, Inc., établie à Calgary, a annoncé que le gouvernement du Canada avait approuvé le programme d'expansion Sunrise, un projet d'agrandissement du réseau pipelinier Westcoast d'Enbridge en Colombie-Britannique d'une valeur de 4 milliards de dollars. Enbridge a déclaré que la construction devrait commencer en juillet 2026 et que la mise en service est prévue pour la fin de 2028.
La société Agnico Eagle Mines Limited, établie à Toronto, a annoncé l'acquisition de toutes les actions émises et en circulation de Rupert Resources Ltd. de Toronto et d'Aurion Resources Ltd. de Saint-Jean, à Terre-Neuve-et-Labrador, pour une contrepartie combinée de 3,35 milliards de dollars. Agnico a déclaré que les transactions devraient se conclure au début du troisième trimestre, sous réserve de l'approbation des tribunaux et des actionnaires.
La société G Mining Ventures Corp., établie à Brossard au Québec, et G2 Goldfields Inc. de Toronto ont annoncé qu'elles avaient conclu une entente définitive selon laquelle GMIN acquerra toutes les actions émises et en circulation de G2 pour une valeur nette d'environ 3,0 milliards de dollars. Les sociétés ont déclaré que la transaction devrait se conclure au deuxième trimestre de 2026, sous réserve de l'approbation des actionnaires et des tribunaux et du respect de certaines autres conditions de clôture habituelles pour une transaction de cette nature.
Salaire minimum
Le salaire minimum fédéral est passé de 17,75 $ à 18,15 $ l'heure le 1er avril.
Le salaire minimum de Terre-Neuve-et-Labrador est passé de 16,00 $ à 16,35 $ l'heure le 1er avril.
Le salaire minimum de l'Île-du-Prince-Édouard est passé de 16,50 $ à 17,00 $ l'heure le 1er avril.
Le salaire minimum de la Nouvelle-Écosse est passé de 16,50 $ à 16,75 $ l'heure le 1er avril.
Le salaire minimum du Nouveau-Brunswick est passé de 15,65 $ à 15,90 $ l'heure le 1er avril.
Le salaire minimum du Yukon est passé de 17,94 $ à 18,51 $ l'heure le 1er avril.
Budgets provinciaux et territoriaux
Le 14 avril, le gouvernement de l'Île-du-Prince-Édouard a déposé son budget de fonctionnement pour 2026-2027, qui comprend des investissements dans les soins de santé et l'éducation ainsi que du soutien pour les insulaires à revenu faible ou moyen, ainsi que du soutien pour les municipalités et les collectivités. Le gouvernement prévoit un déficit de 410 millions de dollars en 2026-2027 et une croissance du produit intérieur brut (PIB) réel de 2,0 % en 2026 et de 2,0 % en 2027.
Le 29 avril, le gouvernement de Terre-Neuve-et-Labrador a publié son budget de 2026, qui comprend des réductions d'impôts ainsi que des investissements dans les soins de santé et dans l'amélioration de la sécurité des collectivités. Le gouvernement prévoit un déficit de 688,5 millions de dollars en 2026-2027 et une croissance du PIB réel de 5,5 % en 2026 et de 3,9 % en 2027.
Autres nouvelles
Le 2 avril, le gouvernement du Canada a annoncé une prolongation de deux ans de l'allègement du droit d'accise sur l'alcool afin de protéger les brasseurs, les distillateurs et les vinificateurs pendant une période d'incertitude mondiale.
Le 14 avril, le gouvernement du Canada a annoncé qu'il suspendait temporairement la taxe d'accise fédérale sur l'essence et le diesel partout au Canada, du 20 avril au 7 septembre.
Le 27 avril, le gouvernement du Canada a annoncé le lancement du premier fonds d'investissement souverain au Canada, le Fonds pour un Canada fort. Le gouvernement a déclaré que le Fonds permettra de financer des entreprises et des projets stratégiques canadiens aux côtés d'autres investisseurs et que, initialement, il versera 25 milliards de dollars sur trois ans, selon la comptabilité de caisse, pour lancer le Fonds.
Le 28 avril, le gouvernement du Canada a publié sa Mise à jour économique du printemps de 2026. Le gouvernement prévoit un déficit de 65,3 milliards de dollars en 2026-2027 et une croissance du PIB réel de 1,1 % en 2026 et de 1,9 % en 2027.
La Banque du Canada a maintenu son taux cible de financement à un jour à 2,25 %. La dernière modification du taux cible du financement à un jour remonte à octobre 2025, et le taux avait alors été abaissé de 25 points de base.
La société GFL Environmental Inc., établie en Floride, et SECURE Waste Infrastructure Corp. de Calgary ont annoncé qu'elles avaient conclu une entente définitive selon laquelle GFL avait accepté d'acquérir toutes les actions ordinaires émises et en circulation de SECURE pour une valeur d'environ 6,4 milliards de dollars. Les sociétés ont déclaré que la transaction devrait se conclure au cours de la deuxième moitié de 2026, sous réserve du respect des conditions de clôture habituelles, notamment l'approbation des tribunaux et des actionnaires, et les approbations réglementaires.
Les sociétés First Capital REIT, KingSett Capital et Choice Properties REIT, établies à Toronto, ont annoncé avoir conclu une entente en vertu de laquelle KingSett et Choice Properties acquerront First Capital dans le cadre d'une opération en unités et en espèces d'une valeur d'environ 9,4 milliards de dollars, y compris la prise en charge de certaines dettes. Les sociétés ont déclaré que la transaction devrait se conclure au cours de la deuxième moitié de 2026, sous réserve de l'approbation des actionnaires et des tribunaux, du respect de la Loi sur la concurrence et de certaines autres conditions de clôture habituelles pour les transactions de cette nature.
La société Nippon Express Holdings, Inc., établie au Japon, a annoncé qu'elle avait conclu une entente pour acquérir toutes les actions du groupe Chaîne d'approvisionnement Metro Inc. de Montréal pour une valeur d'entreprise de 1,8 milliard de dollars. Nippon a déclaré que la transaction devrait se conclure entre juillet 2026 et décembre 2026, sous réserve de la réception des approbations et des autorisations réglementaires applicables.
La société METRO Inc., établie à Montréal, a annoncé le 30 mars que les employés syndiqués de son centre de distribution de produits frais à Laval, ainsi que ceux des secteurs du transport et du bureau central, ont déclenché une grève. METRO a déclaré avoir mis en œuvre un plan d'urgence pour veiller à ce que les magasins continuent de répondre aux besoins des clients.
La société WestJet, établie à Calgary, a annoncé qu'elle avait réduit sa capacité d'environ 1 % en avril, de 3 % en mai et de 5,5 % en juin pour répondre à la demande et mieux gérer les coûts de carburant connexes. WestJet a également déclaré qu'un supplément pour carburant de 50 $ par personne s'appliquerait à toutes les réservations effectuées à compter du 14 avril.
La société Transat A.T. Inc., établie à Montréal, a annoncé qu'elle avait révisé son programme de 2026, comprenant des ajustements ciblés sur certains trajets, en réponse à la crise du carburant dans l'aviation et à la volatilité des marchés de l'énergie. Transat a déclaré que les changements mis en œuvre à ce jour représentaient une réduction de 6 % de la capacité prévue de mai à octobre 2026.
Nouvelles des États-Unis et autres nouvelles internationales
Le président des États-Unis, Donald Trump, a annoncé qu'il avait accordé un permis présidentiel à Bridger Pipeline Expansion LLC, du Wyoming, pour construire, raccorder, exploiter et entretenir des installations frontalières liées aux pipelines à la frontière internationale entre les États-Unis et le Canada, dans le Montana, pour le transport de pétrole brut et de produits pétroliers entre les deux pays.
Le Federal Open Market Committee des États-Unis a maintenu la fourchette cible pour le taux d'intérêt des fonds fédéraux à une valeur allant de 3,50 % à 3,75 %. La dernière modification de la fourchette cible remonte à décembre 2025, et celle-ci avait alors été réduite de 25 points de base.
La Banque de réserve de Nouvelle-Zélande (RBNZ) a maintenu le taux officiel à un jour, son principal taux directeur, à 2,25 %. La dernière modification du taux officiel à un jour remonte à novembre 2025, et le taux avait alors été réduit de 25 points de base.
La Banque du Japon a annoncé qu'elle favoriserait le maintien du taux de financement à un jour (non garanti) autour de 0,75 %. La dernière modification du taux de financement à un jour (non garanti) remonte à décembre 2025, et le taux avait alors augmenté de 25 points de base.
La Banque centrale européenne a maintenu ses trois principaux taux d'intérêt à 2,00 % (service de dépôt), à 2,15 % (principales opérations de refinancement) et à 2,40 % (mécanisme de prêt marginal). La dernière modification de ces taux remonte à juin 2025, et ils avaient alors été réduits de 25 points de base.
Le comité de la politique monétaire de la Banque d'Angleterre a voté en faveur du maintien du taux d'escompte à 3,75 %. La dernière modification du taux d'escompte remonte à décembre 2025, et le taux avait alors été réduit de 25 points de base.
Les huit pays membres de l'Organisation des pays exportateurs de pétrole et ses partenaires (OPEP+), soit l'Arabie saoudite, la Russie, l'Irak, les Émirats arabes unis, le Koweït, le Kazakhstan, l'Algérie et Oman, ont annoncé qu'ils avaient décidé de mettre en œuvre un ajustement de production de 206 000 barils par jour par rapport aux ajustements volontaires supplémentaires de 1,65 million de barils par jour annoncés en avril 2023. Le groupe a déclaré que l'ajustement serait mis en œuvre en mai 2026.
Nouvelles des marchés financiers
Le prix du pétrole brut West Texas Intermediate a clôturé à 105,07 $ US le baril le 30 avril, en hausse par rapport à une valeur de clôture de 101,38 $ US à la fin de mars. Le pétrole brut Western Canadian Select s'est négocié entre 70,00 $ US et 101,00 $ US le baril tout au long d'avril. Le dollar canadien a clôturé à 73,40 cents américains le 30 avril, en hausse par rapport à 71,74 cents américains à la fin de mars. L'indice composé S&P/TSX a clôturé à 33 964,33 le 30 avril, en hausse par rapport à 32 768,04 à la fin de mars.
Le présent module fournit un résumé concis de certains événements économiques canadiens et de faits nouveaux survenus sur le marché international et les marchés financiers, selon le mois civil. L'objectif du module est de fournir des renseignements contextuels visant à guider les utilisateurs des données économiques publiées par Statistique Canada. En faisant état des principaux événements ou faits nouveaux, Statistique Canada ne laisse pas entendre que ceux-ci ont une incidence importante sur les données économiques publiées au cours d'un mois de référence en particulier.
Tous les renseignements présentés ici sont obtenus à partir de sources de nouvelles et d'information publiques, et ils ne comprennent pas les renseignements protégés qui sont fournis à Statistique Canada par les répondants aux enquêtes.
Ressources
Les sociétés Hudbay Minerals Inc., établie à Toronto, et Arizona Sonoran Copper Company Inc. (ASCU), établie en Arizona, ont annoncé qu'elles avaient conclu une entente définitive selon laquelle Hudbay a accepté d'acquérir toutes les actions ordinaires émises et en circulation d'ASCU pour une valeur nette de 1,48 milliard de dollars américains. Les sociétés ont indiqué que la transaction devrait se conclure au deuxième trimestre de 2026, sous réserve de l'approbation des actionnaires ainsi que du respect des autres conditions de clôture habituelles pour les transactions de cette nature.
La Commission canadienne de sûreté nucléaire (CCSN) a annoncé sa décision de délivrer un permis à NexGen Energy Ltd., établie à Vancouver, afin de préparer un site et d'y construire le projet Rook. Ce projet, situé dans le nord de la Saskatchewan, comprend une mine d'uranium et une usine de traitement. La CCSN a déclaré que le permis est valide jusqu'au 31 mars 2036 et autorise les activités de préparation du site et de construction en vertu de la Loi sur la sûreté et la réglementation nucléaires, mais qu'il n'autorise pas l'exploitation de l'installation une fois celle-ci construite.
La société Rio Tinto, établie au Royaume-Uni, a annoncé le 26 mars le dernier jour de production à la mine de diamants Diavik, dans les Territoires du Nord-Ouest. La société a indiqué que les activités de fermeture se poursuivront jusqu'en 2029 et qu'elles seront suivies d'une période de surveillance post-fermeture.
Budgets provinciaux et territoriaux
Le 17 mars, le gouvernement du Nouveau-Brunswick a déposé son budget 2026-2027, qui prévoit des investissements centrés sur les soins de santé, l'abordabilité, l'éducation et le développement économique. Le gouvernement prévoit un déficit de 1,39 milliard de dollars en 2026-2027, ainsi qu'une croissance du produit intérieur réel (PIB) réel de 1,0 % en 2026 et de 1,1 % en 2027.
Le 18 mars, le gouvernement du Québec a présenté son budget 2026-2027, qui prévoit des investissements pour renforcer les services publics, stimuler l'économie, protéger le pouvoir d'achat des Québécois et assurer le bien-être des plus vulnérables. Le gouvernement prévoit un déficit de 8,6 milliards de dollars en 2026 et une croissance du PIB réel de 1,1 % en 2026 et de 1,4 % en 2027.
Le 18 mars, le gouvernement de la Saskatchewan a présenté son budget 2026-2027, qui comprend un plan visant à réduire les impôts provinciaux sur le revenu et à investir dans les compétences et la formation, l'infrastructure, les soins de santé, l'éducation et l'amélioration de la capacité des organismes d'application de la loi. Le gouvernement prévoit un déficit de 819 millions de dollars en 2026-2027 ainsi qu'une croissance du PIB réel de 1,6 % en 2026 et de 2,0 % en 2027.
Le 19 mars, le gouvernement du Yukon a déposé son budget de 2026, qui comprend des investissements dans les soins de santé, l'éducation, le logement et la sécurité publique, ainsi que dans l'amélioration de l'abordabilité et de la fiabilité du réseau énergétique du Yukon. Le gouvernement prévoit un déficit de 81,8 millions de dollars en 2026-2027 et une croissance du PIB réel de 1,2 % en 2026 et de 2,6 % en 2027.
Le 24 mars, le gouvernement du Manitoba a présenté son budget de 2026, qui comprend des investissements visant à renforcer les soins de santé, à réduire les coûts et à créer des emplois. Le gouvernement prévoit un déficit de 498 millions de dollars en 2026-2027, ainsi qu'une croissance du PIB réel de 1,3 % en 2026 et de 1,7 % en 2027.
Le 26 mars, le gouvernement de l'Ontario a déposé son budget de 2026, qui comprend des investissements liés aux infrastructures, aux soins de santé, à l'éducation, à l'abordabilité, à la compétitivité et à la création d'emplois. Le gouvernement prévoit un déficit de 13,8 milliards de dollars en 2026-2027, ainsi qu'une croissance du PIB réel de 1,0 % en 2026 et de 1,7 % en 2027.
Autres nouvelles
Le gouvernement du Canada a annoncé qu'à compter du 1er mars 2026, la Chine avait :
suspendu les droits de douane antidiscrimination sur la farine de canola, les pois, le homard et le crabe jusqu'à la fin de 2026;
réduit ses droits de douane sur les graines de canola canadiennes à un taux tarifaire combiné appliqué de 14,9 %, ce qui représente une baisse par rapport au niveau tarifaire combiné précédent de près de 85 %.
Le gouvernement a également déclaré qu'en date du 1er mars, il avait
mis en place un contingent annuel initial propre au pays de 49 000 véhicules électriques chinois au taux tarifaire de la nation la plus favorisée de 6,1 %, supprimant ainsi la surtaxe précédente de 100 %;
prolongé la remise des surtaxes pour certains produits chinois en acier et en aluminium en pénurie et élargi la couverture à d'autres produits en acier, en aluminium et dérivés de l'acier.
Les gouvernements de l'Ontario et de la Nouvelle-Écosse ont annoncé qu'ils avaient signé une entente pour permettre aux consommateurs d'acheter de l'alcool directement des producteurs locaux de l'autre province, dont les brasseries, les établissements vinicoles et les distilleries.
La société Bell Canada, établie à Montréal, et le gouvernement de la Saskatchewan ont annoncé la construction d'un nouveau centre de données de 300 MW à l'extérieur de Regina, dont une partie de l'électricité sera réservée à la capacité de calcul souveraine de l'intelligence artificielle. Bell a indiqué que la construction de l'installation nécessitera environ 1,7 milliard de dollars en dépenses en immobilisations supplémentaires, dont environ 1,3 milliard de dollars devant être engagés en 2026. Bell a également indiqué que la construction de l'installation commencerait au printemps et que la première phase serait mise en service au cours du premier semestre de 2027.
La société NFI Group Inc., établie à Winnipeg, a annoncé l'inauguration officielle de son nouveau centre d'acceptation et de livraison client à Winnipeg. NFI a déclaré que ce centre lui permet de réaliser entièrement au pays, pour la première fois en 15 ans à Winnipeg, l'ensemble de la production de véhicules lourds pour le transport en commun, y compris des autobus à émission zéro .
La société Boralex Inc., établie à Kingsey Falls, au Québec, la société Brookfield, établie à New York et La Caisse du Québec ont annoncé qu'elles avaient conclu une entente définitive en vertu de laquelle Brookfield et La Caisse acquerraient toutes les actions ordinaires de catégorie A émises et en circulation de Boralex Inc., pour une valeur d'entreprise totale d'environ 9,0 milliards de dollars. Boralex a indiqué que la transaction devrait se conclure au quatrième trimestre de 2026, sous réserve de l'approbation des actionnaires et des autorisations réglementaires et du respect des autres conditions de clôture habituelles.
Nouvelles des États-Unis et autres nouvelles internationales
La Maison-Blanche a annoncé que le président Donald J. Trump avait autorisé l'opération Epic Fury, une campagne militaire visant à éliminer la menace nucléaire posée par le régime iranien.
Le Federal Open Market Committee des États-Unis a maintenu la fourchette cible pour le taux d'intérêt des fonds fédéraux à une valeur allant de 3,50 % à 3,75 %. La dernière modification de la fourchette cible remonte à décembre 2025 et celle-ci avait alors été réduite de 25 points de base.
La Banque de réserve de l'Australie a augmenté la cible pour le taux à un jour de 25 points de base pour la faire passer à 4,10 %. La dernière modification du taux à un jour remonte à février 2026 et le taux avait alors été augmenté de 25 points de base.
La Banque centrale européenne a maintenu ses trois principaux taux d'intérêt à 2,00 % (service de dépôt), à 2,15 % (principales opérations de refinancement) et à 2,40 % (mécanisme de prêt marginal). La dernière modification de ces taux remontait à juin 2025 et ceux-ci avaient alors été abaissés de 25 points de base.
La Banque du Japon a annoncé qu'elle favoriserait le maintien du taux de financement à un jour (non garanti) autour de 0,75 %. La dernière modification du taux de financement à un jour remonte à décembre 2025 et le taux avait alors augmenté de 25 points de base.
Le comité de la politique monétaire de la Banque d'Angleterre a voté en faveur du maintien du taux d'escompte à 3,75 %. La dernière modification du taux d'escompte remonte à décembre 2025 et le taux avait alors été réduit de 25 points de base.
Le conseil d'administration de la Riksbank de Suède a maintenu le taux des prises en pension à 1,75 %. La dernière modification du taux des prises en pension remonte à septembre 2025 et le taux avait alors été réduit de 25 points de base.
Le comité de politique monétaire et de stabilité financière de la banque centrale de Norvège, la Norges Bank, a maintenu son taux directeur à 4,00 %. La dernière modification du taux directeur remonte à septembre 2025 et le taux avait alors été réduit de 25 points de base.
Les huit pays de l'Organisation des pays exportateurs de pétrole et ses partenaires (OPEP+), soit l'Arabie saoudite, la Russie, l'Irak, les Émirats arabes unis, le Koweït, le Kazakhstan, l'Algérie et Oman, ont annoncé qu'ils avaient décidé de reprendre le processus de réduction progressive de 1,65 million de barils par jour en ajustements volontaires supplémentaires annoncés en avril 2023 et se sont entendus sur un ajustement de production de 206 000 barils par jour. Les membres indiquent que cet ajustement sera mis en œuvre en avril 2026.
La société BP, établie au Royaume-Uni, a annoncé le 17 mars qu'elle avait envoyé un avis de lock-out au Syndicat des métallos à sa raffinerie de Whiting, dans l'Indiana. Le lock-out entrera en vigueur le 19 mars.
La société McCormick & Company, Incorporated, établie au Maryland, et la société Unilever PLC, établie au Royaume-Uni, ont annoncé qu'elles avaient conclu une entente visant à fusionner McCormick avec la division alimentaire d'Unilever pour une valeur d'entreprise de 44,8 milliards de dollars. Les sociétés ont indiqué que la transaction devrait se conclure d'ici le milieu de 2027, sous réserve de l'approbation des actionnaires, des approbations réglementaires et du respect des autres conditions de clôture habituelles.
La société Sysco, établie au Texas, et Jetro Restaurant Depot, de New York, ont annoncé avoir conclu une entente définitive en vertu de laquelle Sysco fera l'acquisition de Jetro Restaurant Depot dans le cadre d'une transaction structurante d'une valeur totale d'environ 29,1 milliards de dollars américains. Les entreprises ont indiqué que la transaction devrait se conclure d'ici le troisième trimestre de l'exercice 2027 de Sysco, sous réserve du respect des conditions de clôture habituelles, y compris la réception des approbations réglementaires.
Nouvelles des marchés financiers
Le prix du pétrole brut West Texas Intermediate a clôturé à 101,38 $ US le baril le 31 mars, en hausse par rapport à sa valeur de clôture de 67,02 $ US enregistrée à la fin de février. Le pétrole brut Western Canadian Select s'est négocié de 55,00 $ US à 95,00 $ US le baril tout au long du mois de mars. Le dollar canadien a clôturé à 71,74 cents américains le 31 mars, en baisse par rapport à sa valeur de 73,30 cents américains enregistrée à la fin de février. Le 31 mars, l'indice composé Standard and Poor's/Bourse de Toronto a clôturé à 32 768,04, en baisse par rapport à sa valeur de clôture de 34 339,99 enregistrée à la fin de février.
Le présent module fournit un résumé concis de certains événements économiques canadiens et de faits nouveaux survenus sur le marché international et les marchés financiers, selon le mois civil. L'objectif du module est de fournir des renseignements contextuels visant à guider les utilisateurs des données économiques publiées par Statistique Canada. En faisant état des principaux événements ou faits nouveaux, Statistique Canada ne laisse pas entendre que ceux-ci ont une incidence importante sur les données économiques publiées au cours d'un mois de référence en particulier.
Tous les renseignements présentés ici sont obtenus à partir de sources de nouvelles et d'information publiques, et ils ne comprennent pas les renseignements protégés qui sont fournis à Statistique Canada par les répondants aux enquêtes.
Ressources
Les sociétés Eldorado Gold et Foran Mining, établies à Vancouver, ont annoncé qu'elles avaient conclu une entente en vertu de laquelle Eldorado ferait l'acquisition de Foran pour une valeur d'environ 3,8 milliards de dollars. Les sociétés ont indiqué que la transaction devrait se conclure au deuxième trimestre de 2026, sous réserve de l'approbation des actionnaires et des tribunaux et de l'obtention de certaines autorisations réglementaires, et du respect d'autres conditions de clôture habituelles pour les transactions de cette nature.
La Commission canadienne de sûreté nucléaire (CCSN) a annoncé sa décision de délivrer un permis à Denison Mines Corp., de Toronto, afin de préparer un site pour le projet Wheeler River et d'en faire la construction. Ce projet comprend une mine d'uranium et une usine de traitement situées dans le nord de la Saskatchewan. La CCSN a déclaré que le permis est valide jusqu'au 28 février 2031 et autorise les activités de préparation du site et de construction en vertu de la Loi sur la sûreté et la réglementation nucléaires, mais qu'il n'autorise pas l'exploitation de l'installation qui sera construite.
La société Denison Mines, établie à Toronto, a annoncé qu'elle avait pris la décision finale d'investissement de procéder à la construction de la mine d'uranium Phoenix à récupération in situ et que la préparation du site et les activités de construction devraient commencer en mars 2026.
Fabrication
La société Bombardier inc., établie à Montréal, a annoncé avoir reçu des commandes fermes pour 40 avions d'affaires Challenger 3500, assorties d'options d'achat visant 120 autres appareils. Selon la société, la valeur marchande des commandes s'élève à 1,18 milliard de dollars américains selon les prix de catalogue de 2026, et à 4,72 milliards de dollars américains si toutes les options d'achat sont exercées.
La société LG Energy Solution, établie en Corée du Sud, et les sociétés Stellantis N.V., établie aux Pays-Bas, et NextStar Energy, de Windsor, en Ontario, ont annoncé que LG Energy Solution procédera à l'acquisition de la pleine propriété de NextStar Energy, et que Stellantis vendra à LG Energy Solution sa participation de 49 % dans la société. Les sociétés ont déclaré que la conclusion de la transaction est assujettie aux approbations réglementaires et aux autres conditions de clôture.
Budgets provinciaux et territoriaux
Le 5 février, le gouvernement des Territoires du Nord-Ouest a présenté le budget pour l'exercice 2026-2027, qui comprend des investissements dans le logement, les services de santé, la sécurité des collectivités, les initiatives de réconciliation et le développement économique. Le gouvernement prévoit un excédent d'exploitation de 20 millions de dollars en 2026-2027, et un recul du PIB réel de 3,2 % en 2026.
Le 17 février, le gouvernement de la Colombie-Britannique a présenté le budget 2026, qui comprend des investissements dans l'éducation, les soins de santé, la prévention de la criminalité, les ressources naturelles, l'appui aux entreprises et à la productivité, ainsi que la mise à jour du régime fiscal de la province. Le gouvernement prévoit un déficit de 13,3 milliards de dollars en 2026-2027, ainsi qu'une croissance du PIB réel de 1,3 % en 2026 et de 1,8 % en 2027.
Le 23 février, le gouvernement de la Nouvelle-Écosse a déposé son budget pour l'exercice 2026-2027, qui comprend du financement pour les soins de santé, le logement et des projets de transformation des technologies de l'information en cybersécurité. Le gouvernement prévoit un déficit de 1,19 milliard de dollars en 2026-2027 et une croissance du PIB réel de 1,5 % en 2026 et de 1,5 % en 2027.
Le 26 février, le gouvernement de l'Alberta a présenté son budget pour 2026, qui comprend des investissements dans l'éducation, les soins de santé, le fonds du patrimoine et l'infrastructure. Le gouvernement prévoit un déficit de 9,4 milliards de dollars en 2026-2027, ainsi qu'une croissance du PIB réel de 1,8 % en 2026 et de 2,3 % en 2027.
Commerce de détail
La société Eddie Bauer LLC, établie dans l'État de Washington et exploitant des magasins Eddie Bauer aux États-Unis et au Canada, a annoncé qu'elle avait conclu un accord de soutien à la restructuration avec les prêteurs garantis de la société et entamé des demandes volontaires en vertu du chapitre 11 de la loi américaine sur les faillites. La société a déclaré que ses magasins de liquidation et de vente au détail aux États-Unis et au Canada demeureront ouverts et continueront de servir la clientèle pendant qu'elle amorce le processus de fermeture progressive de certains magasins.
La société Loblaw Companies Limited, établie à Brampton, en Ontario, a annoncé des investissements de 2,4 milliards de dollars en 2026 afin d'ouvrir 70 nouveaux magasins, dont 34 pharmacies et cliniques de soins Shoppers Drug Mart / Pharmaprix et 31 magasins de maxidiscompte No Frills et Maxi, de rénover 191 autres magasins et de poursuivre la construction de son centre de distribution automatisé à Caledon, en Ontario. La société a indiqué que ces investissements devraient permettre de créer 9 700 emplois dans le commerce de détail et la construction.
Autres nouvelles
Le 12 février, le gouvernement du Canada a annoncé qu'à la suite de l'adoption, par le Parlement, du projet de loi C-19, la Loi sur l'allocation canadienne pour l'épicerie et les besoins essentiels, cette mesure législative a reçu la sanction royale.
Le gouvernement du Canada a annoncé sa nouvelle stratégie pour l'industrie automobile, qui comprend de nouvelles mesures visant à :
accélérer les investissements dans le secteur canadien de la fabrication d'automobiles;
rationaliser les politiques de réduction des émissions;
rendre les véhicules électriques plus abordables et plus fiables;
établir un régime commercial complet qui renforce la compétitivité du secteur de l'automobile;
protéger les travailleurs et les entreprises du secteur canadien de l'automobile contre les pressions immédiates.
Selon le gouvernement, ces mesures s'appuient sur des initiatives annoncées précédemment afin d'appuyer la transformation d'industries stratégiques canadiennes, dont l'acier et le bois d'œuvre de résineux.
Le gouvernement du Canada a annoncé sa Stratégie industrielle de défense, qui devrait permettre de créer 125 000 emplois bien rémunérés, d'augmenter de 50 % les exportations dans le domaine de la défense, de porter à 70 % la part des acquisitions de matériel de défense attribuées à des entreprises canadiennes et d'accroître de plus de 240 % les recettes totales de l'industrie canadienne de la défense. Le gouvernement a déclaré que la stratégie s'articule autour de cinq piliers :
faire du Canada un chef de file de la production de matériel de défense;
faciliter la construction au Canada en éliminant les obstacles entre le gouvernement et l'industrie;
accroître l'innovation canadienne en matière de défense et à double usage, et l'exporter vers nos alliés;
protéger les travailleurs, les industries et les chaînes d'approvisionnement du Canada;
diriger une initiative nationale concertée visant à renforcer le secteur de la défense du Canada.
Les sociétés Bell Canada, établie à Montréal, et SAP Canada, établie à Toronto, ont annoncé la signature d'un protocole d'entente visant la prestation conjointe d'une solution infonuagique exploitée au Canada. Les sociétés ont précisé que ce partenariat combinera les capacités du réseau national sécurisé, de la puissance de calcul et de l'infrastructure de couverture des centres de données du Réseau d'intelligence artificielle (IA) tissé de Bell à celles de la solution Sovereign Cloud On-Site de SAP afin d'offrir une solution infonuagique entièrement canadienne et complètement isolée, pour le secteur public et les secteurs réglementés.
Nouvelles des États-Unis et autres nouvelles internationales
Le 20 février, la Cour suprême des États-Unis a déclaré que l'International Emergency Economic Powers Act n'autorise pas le président à imposer des droits de douane.
Le 20 février, la Maison-Blanche a annoncé que le président Donald J. Trump avait signé une proclamation qui impose, pour une période de 150 jours, une taxe à l'importation ad valorem de 10 % sur les articles importés aux États-Unis en vigueur à compter du 24 février. La Maison-Blanche a précisé que certains biens ne seront pas assujettis à la taxe d'importation temporaire, dont les marchandises en provenance du Canada et du Mexique conformes à l'Accord Canada–États-Unis–Mexique.
La Banque de réserve de l'Australie a augmenté le taux à un jour de 25 points de base pour le faire passer à 3,85 %. La dernière modification du taux à un jour remonte à août 2025, et le taux avait alors été réduit de 25 points de base.
Le comité de la politique monétaire de la Banque d'Angleterre a voté en faveur du maintien du taux d'escompte à 3,75 %. La dernière modification du taux d'escompte remonte à décembre 2025 et le taux avait alors été réduit de 25 points de base.
La Banque centrale européenne a maintenu ses trois principaux taux d'intérêt à 2,00 % (service de dépôt), à 2,15 % (principales opérations de refinancement) et à 2,40 % (mécanisme de prêt marginal). La dernière modification de ces taux remonte à juin 2025, et ils avaient alors été réduits de 25 points de base.
La Banque de réserve de la Nouvelle-Zélande a maintenu le taux officiel à un jour, son principal taux directeur, à 2,25 %. La dernière modification du taux officiel à un jour remonte à novembre 2025, et le taux avait alors été réduit de 25 points de base.
Les huit pays membres de l'Organisation des pays exportateurs de pétrole et ses partenaires (OPEP+), soit l'Arabie saoudite, la Russie, l'Irak, les Émirats arabes unis, le Koweït, le Kazakhstan, l'Algérie et Oman, ont annoncé qu'ils ont réaffirmé leur décision du 2 novembre 2025 de suspendre les augmentations de production en mars 2026.
Les sociétés Devon Energy Corporation, établie en Oklahoma, et Coterra Energy Inc., établie au Texas, ont annoncé la signature d'une entente définitive visant leur fusion dans le cadre d'une transaction payée entièrement en actions. Devon a précisé que l'opération correspond à une valeur d'entreprise combinée d'environ 58 milliards de dollars américains et que la transaction devrait se conclure au deuxième trimestre de 2026, sous réserve de l'approbation des actionnaires, des autorisations réglementaires, et des autres conditions de clôture habituelles.
La société Paramount Skydance Corporation, établie en Californie, et la société Warner Bros. Discovery (WBD), établie à New York, ont annoncé qu'elles avaient conclu une entente de fusion définitive en vertu de laquelle Paramount fera l'acquisition de WBD pour une valeur d'entreprise de 110 milliards de dollars américains. Les sociétés ont déclaré que la transaction devrait se conclure au troisième trimestre de 2026, sous réserve des conditions de clôture habituelles, y compris les autorisations réglementaires et l'approbation des actionnaires de WBD.
Nouvelles des marchés financiers
Le prix du pétrole brut West Texas Intermediate a clôturé à 67,02 $US le baril, le 27 février, en hausse par rapport à sa valeur de clôture de 65,42 $US enregistrée à la fin de janvier. Le pétrole brut Western Canadian Select s'est négocié de 49,00 $US à 55,00 $US le baril tout au long du mois de février. Le dollar canadien a clôturé à 73,30 cents américains le 27 février, en baisse par rapport à 73,74 cents américains à la fin de janvier. L'indice composé Standard and Poor's / Bourse de Toronto a clôturé à 34 339,99 le 27 février, en hausse par rapport à sa valeur de clôture de 31 923,52 enregistrée à la fin de janvier.
Le présent module fournit un résumé concis de certains événements économiques canadiens et de faits nouveaux survenus sur le marché international et les marchés financiers, selon le mois civil. L'objectif du module est de fournir des renseignements contextuels visant à guider les utilisateurs des données économiques publiées par Statistique Canada. En faisant état des principaux événements ou faits nouveaux, Statistique Canada ne laisse pas entendre que ceux-ci ont une incidence importante sur les données économiques publiées au cours d'un mois de référence en particulier.
Tous les renseignements présentés ici sont obtenus à partir de sources de nouvelles et d'information publiques, et ils ne comprennent pas les renseignements protégés qui sont fournis à Statistique Canada par les répondants aux enquêtes.
Ressources
La société Kinross Gold, établie à Toronto, a annoncé la mise en œuvre de trois projets de croissance organisationnelle, soit les projets Round Mountain Phase X et Bald Mountain Redbird 2 au Nevada, ainsi que le projet Kettle River-Curlew dans l'État de Washington. Kinross a indiqué que les dépenses en immobilisations initiales des trois projets devraient s'élever à environ 1,38 milliard de dollars américains et s'échelonneront sur une période de trois ou quatre ans.
La société Allied Gold Corporation, établie à Toronto, a annoncé la conclusion d'une entente définitive selon laquelle la compagnie Zijin Gold International Company Limited de Hong Kong avait accepté d'acquérir toutes les actions émises et en circulation d'Allied Gold pour une valeur nette d'environ 5,5 milliards de dollars. Allied Gold a déclaré que la transaction devrait se conclure d'ici la fin avril 2026, sous réserve de l'approbation des actionnaires et des tribunaux, des approbations en vertu de la Loi sur Investissement Canada et d'autres conditions habituelles pour la conclusion de transactions de cette nature.
La société Keyera Corp., établie à Calgary, a annoncé un arrêt prolongé non planifié de ses installations d'Alberta Envirofuels (AEF). La société a déclaré qu'elle avait déclenché un arrêt non planifié à AEF au début de janvier 2026 pour enquêter sur une réduction observée du rendement de l'usine, et qu'elle prévoyait remettre les installations d'AEF en service en mai 2026.
La compagnie Imperial Oil Limited, établie à Calgary, a annoncé que sa production d'hydrocarbures à Norman Wells, dans les Territoires du Nord-Ouest, prendrait fin au troisième trimestre de 2026, alors que l'installation arrive à la fin de sa durée de vie. Selon la société, les travaux d'assainissement ne devraient pas commencer avant 2030, une fois qu'un plan de fermeture définitif aura été établi, qu'une évaluation environnementale aura été achevée et que les permis auront été approuvés par les organismes de réglementation.
Autres nouvelles
Le gouvernement du Canada a annoncé qu'il proposait la nouvelle Allocation canadienne pour l'épicerie et les besoins essentiels, à compter du printemps 2026 et sous réserve de la sanction royale. Le gouvernement a déclaré que l'Allocation canadienne pour l'épicerie et les besoins essentiels fournirait une aide supplémentaire de 11,7 milliards de dollars sur six ans : i) en procédant au versement d'un supplément unique, dès que possible au printemps et au plus tard en juin 2026; ii) en augmentant la valeur de l'Allocation canadienne pour l'épicerie et les besoins essentiels de 25 % pendant cinq ans, à compter de juillet 2026.
Le gouvernement de la Colombie-Britannique a annoncé que le bureau d'évaluation environnementale avait approuvé une modification du certificat d'évaluation environnementale de la mine de cuivre et d'or de Mount Milligan, qui autorise la mine, située près de Fort St. James, à accroître sa production et à poursuivre ses activités jusqu'en 2035.
La Banque du Canada a maintenu son taux cible de financement à un jour à 2,25 %. La dernière modification du taux cible du financement à un jour remonte à octobre 2025, et le taux avait alors été abaissé de 25 points de base.
L'Administration portuaire de Montréal (APM) a annoncé qu'elle avait reçu une autorisation de Pêches et Océans Canada en vue d'agrandir les installations portuaires de Contrecœur et de poursuivre la construction du nouveau terminal à conteneurs. L'APM a déclaré que l'autorisation suit le processus d'évaluation environnementale mené par l'Agence d'évaluation d'impact du Canada, qui a donné lieu à une décision favorable en 2021.
La société Bombardier, établie à Montréal, a annoncé la construction d'un nouveau centre manufacturier de 126 000 pieds carrés à Dorval. Bombardier a indiqué que le centre représente un investissement d'environ 100 millions de dollars et qu'il devrait ouvrir ses portes avant la fin de 2027.
Le Groupe Minto d'Ottawa et la société Crestpoint Real Estate Investments Limited Partnership de Toronto ont annoncé qu'ils formeront un nouveau partenariat de coentreprise sous forme de programme et qu'ils avaient simultanément conclu une entente selon laquelle Crestpoint acquerra la totalité des parts de fiducie en circulation de Minto Apartment Real Estate Investment Trust pour environ 2,3 milliards de dollars, ce qui comprend la prise en charge de la dette nette.
L'entreprise Thunder Bay Pulp and Paper a annoncé qu'elle déposerait des avis auprès du ministère du Travail de l'Ontario pour mettre fin à ses activités de fabrication de papier journal à Thunder Bay au cours du premier trimestre de 2026. L'entreprise a déclaré que jusqu'à 150 personnes seraient directement touchées par l'arrêt de ces activités, et qu'elle continuera d'exploiter une usine consacrée uniquement à la fabrication de pâte kraft à partir de bois résineux, tout en produisant de l'énergie renouvelable destinée à la vente sur le réseau.
General Motors Canada, établie à Oshawa, a annoncé que l'usine d'assemblage d'Oshawa reviendrait à deux quarts de production à compter du 2 février, date à laquelle environ 500 employés seraient mis à pied.
Nouvelles des États-Unis et autres nouvelles internationales
Le 5 janvier, la Maison-Blanche a annoncé la capture et l'extradition du président vénézuélien Nicolas Maduro vers les États-Unis.
La Maison-Blanche a annoncé le 20 janvier que le président Donald J. Trump avait signé un décret pour faire en sorte que les grands investisseurs institutionnels ne puissent pas acheter de maisons unifamiliales qui pourraient autrement être achetées par des familles. La Maison-Blanche a déclaré que le décret prescrit aux principaux organismes d'émettre des directives visant à interdire que les programmes fédéraux pertinents permettent d'approuver, d'assurer, de garantir, de titriser ou de faciliter la vente de maisons unifamiliales à des d'investisseurs institutionnels.
Le Federal Open Market Committee des États-Unis a maintenu la fourchette cible pour le taux d'intérêt des fonds fédéraux à une valeur allant de 3,50 % à 3,75 %. La dernière modification de la fourchette cible remonte à décembre 2025, et celle-ci avait alors été réduite de 25 points de base.
Le comité de politique monétaire et de stabilité financière de la banque centrale de Norvège, la Norges Bank, a maintenu son taux directeur à 4,00 %. La dernière modification du taux directeur remonte à septembre 2025, et le taux avait alors été réduit de 25 points de base.
La Banque du Japon a annoncé qu'elle favoriserait le maintien du taux de financement à un jour (non garanti) autour de 0,75 %. La dernière modification du taux de financement à un jour remonte à décembre 2025, et le taux avait alors augmenté de 25 points de base.
Le Conseil d'administration de la Riksbank de Suède a maintenu le taux des prises en pension à 1,75 %. La dernière modification du taux des prises en pension remonte à septembre 2025, et le taux avait alors été réduit de 25 points de base.
Les huit pays membres de l'Organisation des pays exportateurs de pétrole et ses partenaires (OPEP+), soit l'Arabie saoudite, la Russie, l'Irak, les Émirats arabes unis, le Koweït, le Kazakhstan, l'Algérie et Oman, ont annoncé qu'ils ont réaffirmé leur décision du 2 novembre 2025 de suspendre les augmentations de production en février et en mars 2026.
La société Boston Scientific Corporation, établie au Massachusetts, et la société Penumbra, Inc., établie en Californie, ont annoncé la conclusion d'une entente définitive selon laquelle Boston Scientific fera l'acquisition de Penumbra dans le cadre d'une transaction en espèces et en actions évaluée à environ 14,5 milliards de dollars américains. Les deux sociétés ont indiqué que la transaction devrait se conclure en 2026, sous réserve de l'approbation des actionnaires de Penumbra, et des autres conditions de clôture habituelles.
La société Saks Global Holdings LLC, établie à New York, a annoncé avoir entamé une procédure volontaire de redressement en vertu du chapitre 11 de la loi américaine sur les faillites avec l'appui de ses principaux intervenants financiers. Saks a déclaré que les magasins Saks Fifth Avenue, Neiman Marcus, Bergdorf Goodman, Saks OFF 5TH, Last Call et Horchow étaient ouverts à la clientèle et que le commerce en ligne se poursuivait.
Amazon.com, Inc., établie dans l'État de Washington, a déclaré qu'elle procéderait à des changements organisationnels supplémentaires qui auront une incidence sur 16 000 postes à l'échelle de l'entreprise.
La société Dow Chemical, établie au Michigan, a annoncé un plan visant à simplifier ses activités et prévoit entre 600 et 800 millions de dollars américains en indemnités de départ pour environ 4 500 employés de Dow.
Nouvelles des marchés financiers
Le prix du pétrole brut West Texas Intermediate a clôturé à 65,21 $ US le baril, le 30 janvier, en hausse par rapport à sa valeur de clôture de 57,95 $ US à la fin de décembre. Le pétrole brut Western Canadian Select s'est négocié entre 43,00 $ US et 53,00 $ US le baril tout au long du mois de janvier. Le dollar canadien a clôturé à 73,74 cents américains le 30 janvier, en hausse par rapport à sa valeur de 72,96 cents américains enregistrée à la fin de décembre. Le 30 janvier, l'indice composé Standard and Poor's/Bourse de Toronto a clôturé à 31 923,52, en hausse par rapport à sa valeur de clôture de 31 712,76 à la fin de décembre.
Le présent module fournit un résumé concis de certains événements économiques canadiens et de faits nouveaux survenus sur le marché international et les marchés financiers, selon le mois civil. L'objectif du module est de fournir des renseignements contextuels visant à guider les utilisateurs des données économiques publiées par Statistique Canada. En faisant état des principaux événements ou faits nouveaux, Statistique Canada ne laisse pas entendre que ceux-ci ont une incidence importante sur les données économiques publiées au cours d'un mois de référence en particulier.
Tous les renseignements présentés ici sont obtenus à partir de sources de nouvelles et d'information publiques, et ils ne comprennent pas les renseignements protégés qui sont fournis à Statistique Canada par les répondants aux enquêtes.
Ressources
La société Suncor Énergie inc., établie à Calgary, a annoncé que ses dépenses en immobilisations devraient se situer entre 5,6 milliards de dollars et 5,8 milliards de dollars en 2026. Selon Suncor, les principaux investissements économiques prévus ou en cours en 2026 portent sur les plateformes d'exploitation in situ, Mildred Lake East, West White Rose, le développement de la fosse nord de Fort Hills et la poursuite du plan d'optimisation du réseau de vente au détail de Petro-Canada.
La société Cenovus Energy Inc., établie à Calgary, a annoncé que ses investissements en immobilisations se situeraient entre 5,0 milliards de dollars et 5,3 milliards de dollars en 2026. Cenovus a précisé que son budget d'investissement en immobilisations comprend un investissement de maintien de 3,5 milliards de dollars à 3,6 milliards de dollars, tandis qu'un montant supplémentaire de 1,2 milliard de dollars à 1,4 milliard de dollars en investissement sera affecté à des projets de croissance, notamment un projet d'agrandissement à Christina Lake North.
La société Imperial Oil Limited, établie à Calgary, a annoncé que ses dépenses d'immobilisations et d'exploration devraient se situer entre 2,0 milliards de dollars et 2,2 milliards de dollars, et qu'elles seraient orientées vers des projets visant à renforcer la rentabilité à long terme, notamment l'avancement de projets de récupération secondaire du bitume à Kearl, de forage à Cold Lake, d'avancement des activités minières à Kearl et à Syncrude, ainsi que des investissements dans les infrastructures numériques.
La société Baytex Energy Corp., établie à Calgary, a annoncé des dépenses d'exploration et de développement pour 2026 de 550 millions de dollars à 625 millions de dollars. Baytex a déclaré que les capitaux d'entretien s'établiraient à 435 millions de dollars et que le capital de croissance se situerait entre 50 millions de dollars et 75 millions de dollars.
La société Enbridge Inc., établie à Calgary, a annoncé qu'elle prévoit dépenser environ 10 milliards de dollars de capital de croissance en 2026, à l'exclusion des capitaux d'entretien.
La société Vale Base Metals, établie à Toronto, a annoncé la conclusion d'une entente avec la société Glencore Canada en vue d'évaluer conjointement un projet potentiel de mise en valeur du cuivre dans une zone désaffectée située sur leurs propriétés adjacentes dans le bassin de Sudbury. Selon la société Vale, le projet devrait produire 880 kilotonnes de cuivre sur 21 ans, pour un coût en capital évalué entre 1,6 milliard de dollars américains et 2,0 milliards de dollars américains. Une décision définitive d'investissement est attendue au premier semestre de 2027.
La société Domtar Corporation, établie à Montréal, a annoncé la fin de ses activités de façon permanente à ses installations de Crofton, en Colombie-Britannique. Domtar a déclaré que cette décision touchera environ 350 employés et réduira sa production annuelle de pâte à papier d'environ 380 000 tonnes métriques de pâte séchée à l'air.
Aperçu de la situation économique et financière
Le 15 décembre, le gouvernement du Manitoba a publié sa mise à jour économique et financière. Le gouvernement prévoit un déficit de 1,66 milliard de dollars en 2025-2026 et une croissance du produit intérieur brut (PIB) réel de 1,1 % en 2025 et de 1,4 % en 2026.
Le 16 décembre, le gouvernement de Terre-Neuve-et-Labrador a publié sa mise à jour économique et financière de l'automne. Le gouvernement prévoit un déficit de 948 millions de dollars en 2025-2026 et une croissance du PIB réel de 5,3 % en 2025.
Le 18 décembre, le gouvernement de la Nouvelle-Écosse a publié une mise à jour de ses prévisions. Le gouvernement prévoit un déficit de 1,29 milliard de dollars avant provisions pour imprévus en 2025-2026, ainsi qu'une croissance du PIB réel de 1,5 % en 2025 et de 1,3 % en 2026.
Autres nouvelles
Le 12 décembre, le gouvernement du Canada a annoncé la mise en œuvre de nouvelles mesures annoncées par le premier ministre le 26 novembre visant à offrir un allègement et une meilleure prévisibilité aux fabricants canadiens. Ces mesures comprennent la prolongation temporaire de la suppression des droits de douane canadiens imposés sur les importations en provenance des États-Unis, ainsi que la réduction des niveaux de contingents tarifaires applicables aux produits de l'acier importés à compter du 26 décembre 2025.
La Banque du Canada a maintenu son taux cible de financement à un jour à 2,25 %. La dernière modification du taux cible du financement à un jour remonte à octobre 2025, et le taux avait alors été abaissé de 25 points de base.
Le gouvernement du Québec a annoncé qu'il avait reçu des avis de 39 syndicats affiliés à la Fédération du préhospitalier du Québec indiquant que les ambulanciers avaient l'intention de déclencher une grève illimitée à partir du 24 décembre. Le gouvernement a indiqué que les services maintenus étaient suffisants pour que la santé ou la sécurité de la population ne soit pas mise en danger.
La société Transcontinental inc., établie à Montréal, a annoncé la conclusion d'une entente d'achat d'actions avec ProAmpac Holdings Inc., établie en Ohio, en vertu de laquelle ProAmpac a accepté d'acquérir la totalité des actions émises et en circulation du stock net de capital des entités exerçant les activités du secteur de l'emballage de Transcontinental, pour une valeur d'entreprise d'environ 2,22 milliards de dollars. Selon Transcontinental, la transaction est assujettie à l'obtention de l'approbation des actionnaires, des approbations réglementaires et des autres conditions de clôture habituelles.
La Banque Laurentienne du Canada, établie à Montréal, a annoncé que : i) la Banque Nationale du Canada avait conclu une entente définitive visant l'acquisition des portefeuilles de services bancaires au détail et des petites et moyennes entreprises (PME) de la Banque Laurentienne; ii) la Banque Fairstone du Canada avait conclu une entente définitive visant l'acquisition de la totalité des actions ordinaires émises et en circulation de la Banque Laurentienne pour une contrepartie totale en espèces d'environ 1,9 milliard de dollars, sous réserve des conditions de clôture habituelles, y compris la réception des approbations réglementaires nécessaires. La Banque Laurentienne a déclaré que les transactions devraient se conclure vers la fin de 2026.
La société WSP Global inc., établie à Montréal, a annoncé la conclusion d'une entente visant l'acquisition de TRC Companies, une société américaine du secteur de l'énergie établie au Connecticut, pour un prix d'achat total en espèces d'environ 4,5 milliards de dollars. WSP a déclaré que l'acquisition devrait se conclure lors du premier trimestre de 2026, sous réserve de certaines des conditions de clôture habituelles, y compris les approbations réglementaires nécessaires.
La Société Microsoft, établie dans l'État de Washington, a annoncé qu'elle investirait plus de 7,5 milliards de dollars au Canada au cours des deux prochaines années, notamment dans la construction de nouvelles infrastructures numériques et d'intelligence artificielle dotées de capacité supplémentaire qui commencera à être mise en service dans la seconde moitié de 2026. Selon Microsoft, ses investissements au Canada atteindraient 19 milliards de dollars de 2023 à 2027.
La société EQB Inc., établie à Toronto, et Loblaw Companies Limited de Brampton ont annoncé la conclusion d'une entente définitive en vertu de laquelle EQB fera l'acquisition de President's Choice Bank (PC Bank), PC® Financial Insurance Agency Inc., PC® Financial Insurance Brokers Inc., et de certaines autres entités affiliées de PC Bank pour une valeur totale estimée à 1,3 milliard de dollars. Les sociétés ont déclaré que la transaction devrait se conclure en 2026, sous réserve des conditions de clôture habituelles et des approbations réglementaires.
Le Syndicat des Métallos a annoncé la mise à pied de plus d'un millier de personnes à l'aciérie Algoma Steel Inc. à Sault-Sainte-Marie, en Ontario. Le syndicat a indiqué que les pertes d'emploi étaient prévisibles en raison du passage aux fours à arc électrique pour la production d'acier et de l'imposition de droits de douane de 50 % par les États-Unis sur les exportations d'acier canadien.
Nouvelles des États-Unis et autres nouvelles internationales
Le Federal Open Market Committee (FOMC) des États-Unis a abaissé de 25 points de base la fourchette cible pour le taux d'intérêt des fonds fédéraux, celle-ci étant maintenant de 3,50 % à 3,75 %. La dernière modification de la fourchette cible remontait à octobre 2025 et celle-ci avait alors été réduite de 25 points de base.
La Banque de réserve de l'Australie a maintenu le taux à un jour à 3,60 %. La dernière modification du taux à un jour remonte à août 2025 et le taux avait alors été réduit de 25 points de base.
Le comité de la politique monétaire de la Banque d'Angleterre a voté pour la réduction de son taux d'escompte de 25 points de base pour le porter à 3,75 %. La dernière modification du taux d'escompte remonte à août 2025 et le taux avait alors été réduit de 25 points de base.
La Banque centrale européenne a maintenu ses trois principaux taux d'intérêt à 2,00 % (service de dépôt), à 2,15 % (principales opérations de refinancement) et à 2,40 % (mécanisme de prêt marginal). La dernière modification de ces taux remontait à juin 2025, et ceux-ci avaient alors été abaissés de 25 points de base.
Le conseil d'administration de la Riksbank de Suède a maintenu le taux des prises en pension à 1,75 %. La dernière modification du taux des prises en pension remonte à septembre 2025 et le taux avait alors été réduit de 25 points de base.
Le comité de politique monétaire et de stabilité financière de la banque centrale de Norvège, la Norges Bank, a maintenu son taux directeur à 4,00 %. La dernière modification du taux directeur remonte à septembre 2025 et le taux avait alors été réduit de 25 points de base.
La Banque du Japon a annoncé qu'elle favoriserait le maintien du taux de financement à un jour (non garanti) autour de 0,75 %. La dernière modification du taux de financement à un jour remontait à janvier 2025 et le taux avait alors augmenté de 25 points de base pour s'établir à 0,50 %.
Les huit pays membres de l'Organisation des pays exportateurs de pétrole et ses partenaires (OPEP+), soit l'Arabie saoudite, la Russie, l'Iraq, les Émirats arabes unis, le Koweït, le Kazakhstan, l'Algérie et Oman, ont réaffirmé leur décision du 2 novembre 2025 de suspendre les augmentations de production en janvier, en février et en mars 2026.
La société IBM, établie dans l'État de New York, et Confluent, Inc., une plateforme infonuagique de diffusion continue établie en Californie, ont annoncé qu'elles avaient conclu une entente définitive en vertu de laquelle IBM acquerra la totalité des actions ordinaires émises et en circulation de Confluent pour une valeur d'entreprise de 11 milliards de dollars américains. Selon les deux sociétés, la transaction devrait se conclure d'ici le milieu de 2026, sous réserve de l'approbation des actionnaires de Confluent, des approbations réglementaires et des autres conditions de clôture habituelles.
La société Brookfield Asset Management, établie à New York, et Qai, une entreprise d'intelligence artificielle (IA) du Qatar et filiale de Qatar Investment Authority, ont annoncé un partenariat stratégique visant la création d'une coentreprise d'une valeur de 20 milliards de dollars américains axée sur les infrastructures d'IA au Qatar et dans certains marchés internationaux.
Netflix, Inc., établie en Californie, et Warner Bros. Discovery, Inc. ont annoncé qu'elles avaient conclu une entente définitive en vertu de laquelle Netflix acquerra Warner Bros. dans le cadre d'une transaction payée en espèces et en actions d'une valeur nette totale de 72,0 milliards de dollars américains. Les sociétés ont déclaré que la transaction devrait se conclure d'ici 12 à 18 mois, sous réserve de l'obtention des approbations réglementaires, de l'approbation des actionnaires de Warner Bros. et des autres conditions de clôture habituelles.
Nouvelles des marchés financiers
Le prix du pétrole brut West Texas Intermediate a clôturé à 57,95 $ US le baril le 31 décembre, en baisse par rapport à sa valeur de clôture de 58,55 $ US enregistrée à la fin de novembre. Le pétrole brut Western Canadian Select s'est négocié entre 42,00 $ US et 48,00 $ US le baril tout au long du mois de décembre. Le dollar canadien a clôturé à 72,96 cents américains le 31 décembre, en hausse par rapport à sa valeur de 71,54 cents américains à la fin de novembre. Le 31 décembre, l'indice composé Standard and Poor's/Bourse de Toronto a clôturé à 31 712,76, en hausse par rapport à sa valeur de clôture de 31 382,78 enregistrée à la fin de novembre.

 La COVID-19
La COVID-19