Interface utilisateur à programmation schématisée avec Plotly Dash
Par: Jeffery Zhang, Statistique Canada
Introduction
Les scientifiques des données créent souvent des modèles qui sont mis en œuvre en R ou en Python. Si ces modèles sont destinés à la production, ils devront être accessibles aux utilisateurs non spécialisés.
Pour rendre les modèles de données accessibles aux utilisateurs non spécialisés dans la phase de production, l'un des principaux problèmes réside dans les aléas de la création d'interfaces utilisateurs accessibles. Bien qu'il soit acceptable qu'un prototype de recherche soit exécuté à partir d'une ligne de commande, toutes les complexités que ce type d'interface présente peuvent grandement décourager les utilisateurs non spécialisés.
La plupart des scientifiques des données manquent d'expérience dans la conception d'interfaces utilisateurs, et la plupart des projets ne disposent pas du budget nécessaire pour l'embauche d'un développeur spécialiste des interfaces utilisateurs. Dans le présent article, nous présentons un outil qui permet aux personnes qui ne sont pas des spécialistes de ce type d'interface de créer rapidement une interface utilisateur satisfaisante en langage Python.
En quoi consiste Plotly Dash?
Plotly est une bibliothèque de visualisation des données à code source ouvert. Dash est un cadre à programmation schématisée pour la conception d'applications de données à code source ouvert qui s'appuie sur Plotly. Plotly Dash offre une solution au problème des interfaces utilisateurs de données. Avec Plotly Dash, les scientifiques des données qui ne sont pas spécialisés dans les interfaces utilisateurs peuvent en quelques jours en concevoir une qui sera satisfaisante pour une application de données. Dans la plupart des projets, un investissement de deux à cinq jours de travail supplémentaires pour la conception d'une interface utilisateur graphique interactive en vaut la peine.
Comment fonctionne Plotly Dash?
Plotly et Dash peuvent être considérés comme des langages dédiés. Plotly est un langage dédié permettant de décrire des graphiques. L'objet central de Plotly est une figure, qui décrit tous les aspects d'un graphique tels que les axes, ainsi que les composants graphiques comme les barres, les lignes ou les secteurs. Nous utilisons Plotly pour créer les objets de la figure et avons ensuite recours à l'un des moteurs de rendu disponibles pour le rendre sur un dispositif de sortie cible, tel qu'un navigateur Web.
Description - Figure 1 : Exemple d'une figure Plotly
Voici un exemple d’une figure générée par Plotly. Il s’agit d’un diagramme à barres interactif qui permet à l’utilisateur de passer la souris sur chaque barre pour voir les valeurs des données associées à cette barre.
Dash fournit deux langages dédiés et un moteur de rendu Web pour les objets Figure de Plotly.
Le premier langage dédié de Dash sert à décrire la structure d'une interface utilisateur Web. Il comprend des composants pour les éléments HTML tels que div et p, ainsi que des contrôles d'interface utilisateur tels que Slider et DropDown. L'un des éléments clés du langage dédié Web de Dash est le composant Graph, qui nous permet d'intégrer une figure Plotly dans l'interface utilisateur Web de Dash.
Voici un exemple d'une application Dash simple.
From dash import Dash, html, dcc, callback, Output, Input
import plotly.express as px
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminder_unfiltered.csv')
app = Dash(__name__)
app.layout = html.Div([
html.H1(children='Title of Dash App', style={'textAlign':'center'}),
dcc.Dropdown(df.country.unique(), 'Canada', id='dropdown-selection'),
dcc.Graph(id='graph-content')
])
if __name__ == '__main__':
app.run_server(debug=True)
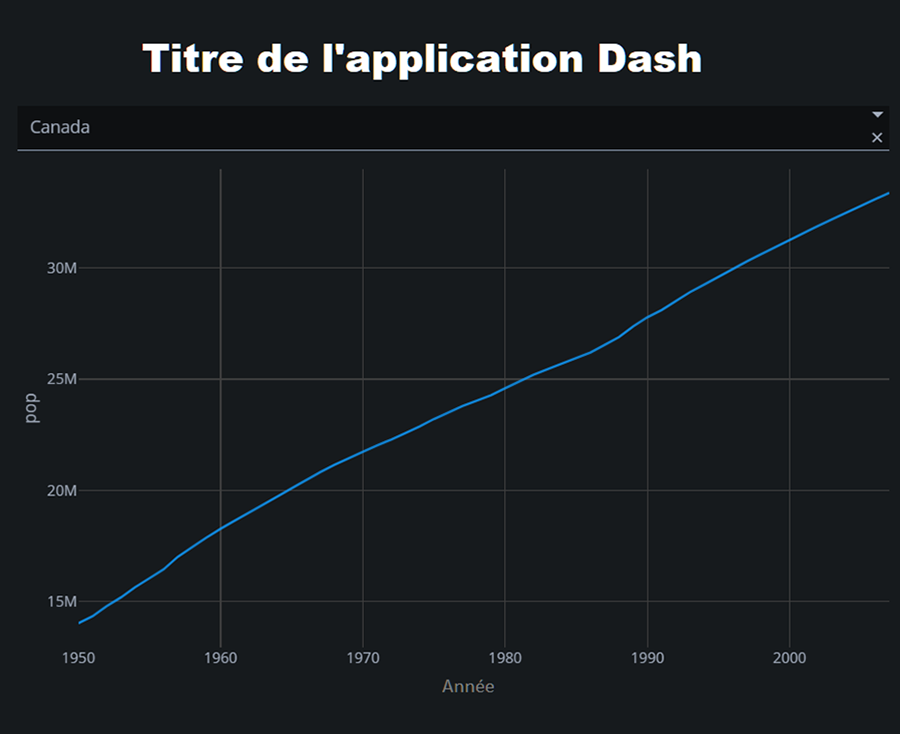
Voici à quoi cela ressemble dans un navigateur Web.
Description - Figure 2 : Application simple affichée dans un navigateur
Voici un exemple d’une application minimale créée avec Plotly Dash. Cette application d’échantillons permet de visualiser la croissance de la population canadienne de 1950 jusqu’à la date actuelle à l’aide d’un graphique linéaire. La visualisation est interactive et l’utilisateur peut passer la souris sur les points de la ligne bleue pour voir les valeurs de données associées à ce point.
Le deuxième langage dédié de Dash permet de décrire des flux de données réactifs. Cela nous permet d'ajouter de l'interactivité à l'application de données en décrivant de quelle façon les données passent des composants d'entrée de l'utilisateur au modèle de données, puis reviennent à l'interface utilisateur.
L'ajout du code suivant à l'exemple ci-dessus crée un flux de données réactif entre le composant d'entrée dropdown-selection, la fonction update_graph et le graphique de sortie. Dès que la valeur du composant d'entrée dropdown-selection change, la fonction update_graph est lancée avec la nouvelle valeur de dropdown-selection, et la valeur de retour de update-graph est envoyée à la propriété figure de l'objet graph-content. Cette opération met à jour le graphique en fonction de la sélection de l'utilisateur dans le composant déroulant.
Vous trouverez ci-dessous quelques scénarios courants d'applications de données; nous indiquons également de quelle façon les fonctions de Dash prennent en charge ces scénarios.
Longs délais de traitement
Il arrive que l'exécution d'un modèle de données prenne beaucoup de temps. Par conséquent, il est judicieux de fournir à l'utilisateur une rétroaction au cours de ce processus afin de l'informer que le modèle de données est en cours d'exécution et que l'application n'est pas tombée en panne. Il serait encore plus utile de fournir une mise à jour de l'état d'avancement afin que l'utilisateur sache approximativement la part du travail qui a été accomplie et celle qui reste à faire.
Nous pouvons également nous rendre compte que nous avons commis une erreur lors de la définition des paramètres d'un travail à longue exécution; dans ce cas, nous voudrions annuler le travail en cours et le recommencer après y avoir apporté des corrections. La fonction de Dash permettant la mise en œuvre de ces scénarios s'appelle « Background callbacks » (en anglais seulement).
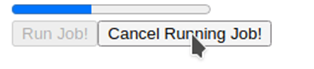
Voici un exemple d'une application Dash simple qui présente un travail à longue exécution et montre la barre de progression et le bouton d'annulation.
Description - Figure 3 : Travail à longue exécution avec la barre de progression et le bouton d'annulation
Voici un exemple d’une application de Plotly Dash impliquant une tâche d’exécution longue et une barre de progression pour afficher l’état d’avancement de la tâche. Cette application a deux boutons. Le bouton « Run Job » (exécuter la tâche) est activé initialement. Si vous cliquez sur ce bouton, la tâche sera lancée et la barre de progression sera créée. Lorsque la tâche est en cours d’exécution, le bouton « Run Job » (exécuter la tâche) est désactivé et le bouton « Cancel Running Job » (annuler la tâche en cours) est activé pendant que la tâche est en cours d’exécution. Si vous cliquez sur ce bouton avant la fin de la tâche, celle-ci sera annulée.
Rappels multiples
Normalement, la valeur d'une sortie est déterminée de manière unique par un rappel. Si plusieurs rappels mettent à jour la même sortie, nous serons confrontés à un scénario dans lequel la sortie aura plusieurs valeurs en même temps et nous ne saurons pas laquelle est la bonne.
Cependant, nous pourrons parfois prendre le risque de lier plusieurs rappels à la même sortie pour simplifier les choses. Dash nous permet de le faire en indiquant expressément que nous autorisons les sorties multiples. Cette fonction s'active lorsque nous fixons la valeur du paramètre allow_duplicate de Output à True. Voici un exemple :
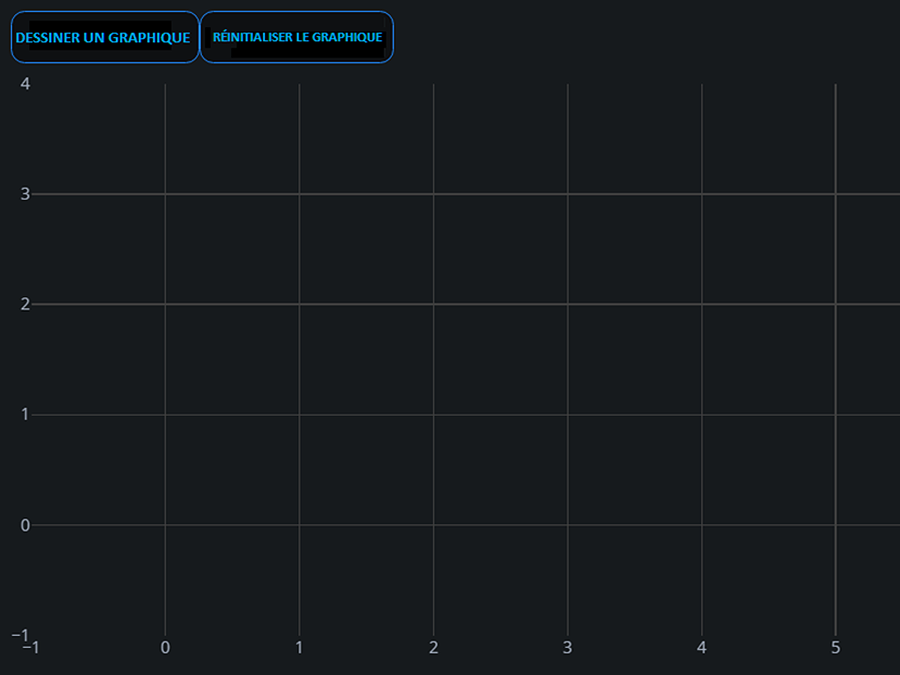
Description - Figure 4 : Graphique mis à jour par deux boutons différents
Voici un exemple d’une application Plotly Dash qui utilise des rappels multiples. Elle comporte deux boutons qui ciblent tous les deux les mêmes données de sortie, soit le graphique ci-dessous. Un clic sur le bouton « Draw Graph » (dessiner le graphique) produit le graphique, tandis que le bouton « Reset Graph » (réinitialiser le graphique) efface le graphique. Étant donné que les deux boutons ciblent les mêmes données de sortie, ce scénario nécessite la fonction de rappels multiples de Plotly Dash.
Dans ce cas, nous disposons de deux boutons pour mettre à jour un graphique : Draw (dessiner) et Reset (réinitialiser). Le graphique sera mis à jour par le dernier bouton utilisé. Bien que cela soit pratique, la conception d'une interface utilisateur de cette manière comporte un risque. Dans un ordinateur pourvu d'un seul pointeur de souris, on peut supposer qu'un seul clic de bouton est possible à un moment donné. Par contre, dans le cas d'un écran tactile multipoint comme celui d'un téléphone intelligent ou d'une tablette, il est possible de cliquer sur deux boutons en même temps. En général, dès que nous autorisons des rappels multiples, la sortie devient potentiellement indéterminée, ce qui peut entraîner certains bogues très difficiles à reproduire.
Cette fonctionnalité est à la fois pratique et potentiellement dangereuse. Par conséquent, son utilisation est à vos risques et périls!
Composants personnalisés
Parfois, l'ensemble des composants fournis avec Dash n'est pas suffisant. L'interface utilisateur Web de Dash est créée avec React; Dash fournit un outil pratique pour intégrer des composants React personnalisés dans Dash. Cet article ne traite pas en détail de React ni de l'intégration Dash-React. Cependant, vous pouvez en savoir plus à ce sujet en consultant la page « Build your own components » (en anglais seulement).
Affichage des erreurs
Durant les calculs, il arrive qu'une erreur se produise en raison de problèmes liés aux données, au code ou à une erreur de l'utilisateur. Au lieu d'interrompre l'application, nous pourrions vouloir afficher l'erreur pour l'utilisateur et lui fournir quelques renseignements sur ce qu'il est possible de faire pour la corriger.
Deux fonctions de Dash sont utilisées pour ce scénario : multiple outputs et dash.no_update.
La fonction multiple outputs autorise les rappels et retourne plusieurs sorties sous la forme d'un uplet.
Quant à la fonction dash.no_update, elle prend une valeur et peut la retourner dans un emplacement de sortie pour indiquer qu'il n'y a pas de changement dans cette sortie.
Voici un exemple qui utilise ces deux fonctions pour mettre en œuvre l'affichage d'une erreur :
Les calculs de rappel Dash étant effectués sur le serveur, il faut, pour afficher les résultats à l'intention du client, rassembler toutes les valeurs de retour du rappel et les lui envoyer à chaque mise à jour.
Ces mises à jour concernent parfois des objets de figure très volumineux, qui consomment beaucoup de bande passante et ralentissent le processus de mise à jour. Cela aura une incidence négative sur l'expérience d'utilisateur. Une manière simple de réaliser des mises à jour par rappel consiste à effectuer des mises à jour monolithiques sur de grandes structures de données telles que des figures, même si seule une petite partie, comme le titre, a été modifiée.
Pour optimiser l'utilisation de la bande passante et améliorer l'expérience d'utilisateur, Dash dispose d'une fonction appelée « Partial Update » (mise à jour partielle). Cette fonctionnalité introduit un nouveau type de valeur de retour pour les rappels appelé Patch. Patch désigne les sous-composants d'une structure de données plus large qui doivent être mis à jour, ce qui nous permet d'éviter d'envoyer une structure de données entière dans l'ensemble du réseau lorsque seule une partie de celle-ci doit être mise à jour.
Voici un exemple de mise à jour partielle qui ne sert à modifier que la couleur de la police du titre de la figure, au lieu de la figure entière :
From dash import Dash, html, dcc, Input, Output, Patch
import plotly.express as px
import random
app = Dash(__name__)
df = px.data.iris()
fig = px.scatter(
df, x="sepal_length", y="sepal_width", color="species", title="Updating Title Color"
)
app.layout = html.Div(
[
html.Button("Update Graph Color", id="update-color-button-2"),
dcc.Graph(figure=fig, id="my-fig"),
]
)
@app.callback(Output("my-fig", "figure"), Input("update-color-button-2", "n_clicks"))def my_callback(n_clicks):
# Defining a new random color
red = random.randint(0, 255)
green = random.randint(0, 255)
blue = random.randint(0, 255)
new_color = f"rgb({red}, {green}, {blue})"# Creating a Patch object
patched_figure = Patch()
patched_figure["layout"]["title"]["font"]["color"] = new_color
return patched_figure
if __name__ == "__main__":
app.run_server(debug=True)
Interface utilisateur dynamique et filtrage de rappels
Parfois, il n'est pas possible de définir statiquement le flux de données. Si, par exemple, nous voulons créer une pile de filtres qui permet à l'utilisateur d'ajouter des filtres de façon flexible, nous ne saurons pas à l'avance quels filtres ce dernier ajoutera. C'est statiquement impossible de définir des flux de données comportant des composants d'entrée que l'utilisateur ajoute au moment de l'exécution.
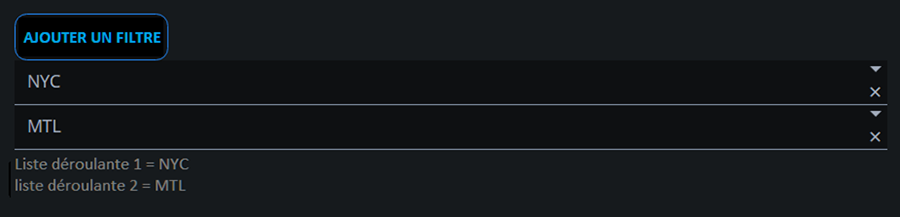
Voici un exemple de pile dynamique de filtres à laquelle l'utilisateur peut en ajouter de nouveaux en cliquant sur le bouton ADD FILTER. L'utilisateur peut ensuite sélectionner la valeur du filtre à l'aide de la liste déroulante qui s'ajoute dynamiquement.
Description - Figure 5 : Pile de filtres dynamique
Voici un exemple d’une application Plotly Dash qui utilise une interface utilisateur dynamique et un filtrage de rappels. En cliquant sur le bouton « Add Filter » (ajouter un filtre), vous ajoutez une liste déroulante supplémentaire. Étant donné que les cases déroulantes sont ajoutées de manière dynamique, nous ne pouvons pas les lier aux rappels à l’avance. L’utilisation de la fonction de filtrage de rappels de Dash nous permet de lier des éléments de l’interface utilisateur créés dynamiquement à des rappels à l’aide d’un prédicat de filtrage.
Dash prend en charge ce scénario en nous permettant de lier des rappels à des sources de données de manière dynamique grâce à un mécanisme de filtrage.
Le code suivant met en œuvre l'interface utilisateur ci-dessus :
Au lieu de définir les composants DropDown de manière statique, nous créons dropdown-container-div, où seront stockés tous les composants DropDown que l'utilisateur créera. Si nous créons les composants DropDown dans display_dropdowns, chaque nouveau composant DropDown sera doté d'un id (identifiant). En règle générale, cette valeur id aurait la forme d'une chaîne de caractères; cependant, pour activer le filtrage des rappels, Dash permet également que id soit un dictionnaire. Il peut s'agir d'un dictionnaire arbitraire, de sorte que les clés de l'exemple ci-dessus ne sont pas des valeurs spéciales. Si id est un dictionnaire, nous pouvons définir des filtres détaillés dont l'appariement est effectué avec chaque clé du dictionnaire.
Dans l'exemple ci-dessus, lorsque l'utilisateur ajoute de nouveaux composants DropDown, les identifiants (id) des composants dynamiques DropDown sont marqués par des identifiants séquentiels comme les suivants :
'{"type": "city-filter-dropdown", "index": 1}
'{"type": "city-filter-dropdown", "index": 2}
'{"type": "city-filter-dropdown", "index": 3}
Ensuite, dans les métadonnées du rappel display_output, nous définissons son entrée comme Input({"type" : « city-filter-dropdown », « index" : ALL}, « value »), qui s'apparie alors à tous les composants dont l'id a un type égal à city-filter-dropdown. En indiquant "index": ALL, nous précisons que l'appariement s'applique à toutes les valeurs de l'indice (index).
Outre ALL, Dash prend également en charge d'autres critères de filtrage tels que MATCH et ALLSMALLER. Pour en savoir davantage sur cette fonctionnalité, consultez la page « Pattern Matching Callbacks » (en anglais seulement).
Exemples
Voici quelques exemples d'applications créées avec Dash :
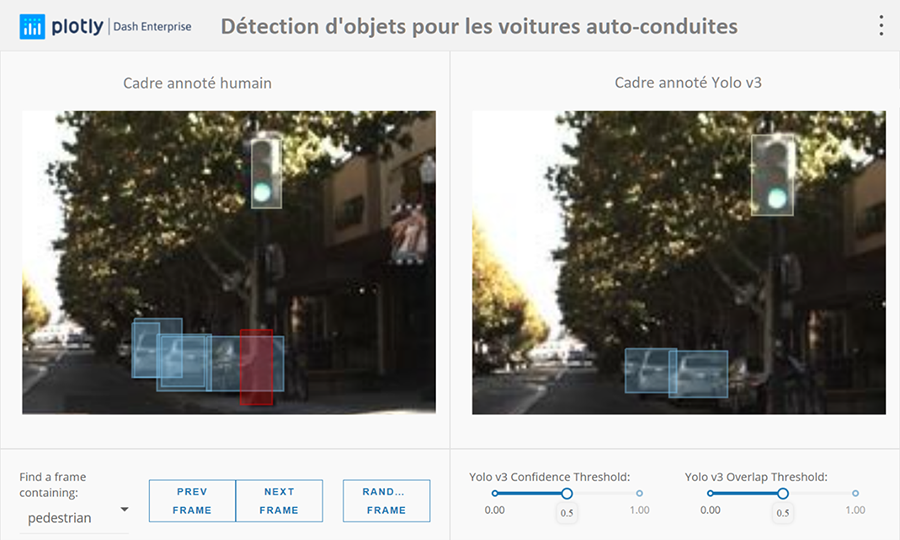
Description - Figure 6 : Détection d'objets
Voici un exemple d’une application Plotly Dash utilisée pour la détection d’objets. Elle permet de visualiser les boîtes de délimitation des objets détectés dans une scène.
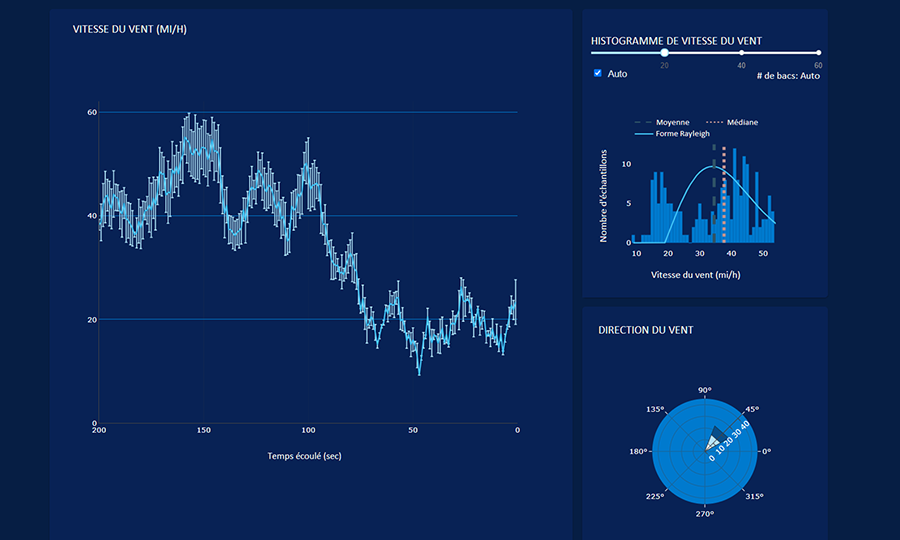
Description - Figure 7 : Tableau de bord
Voici un exemple d’une application du tableau de bord Plotly Dash. Cette application permet de visualiser les données relatives à la vitesse et à la direction du vent.
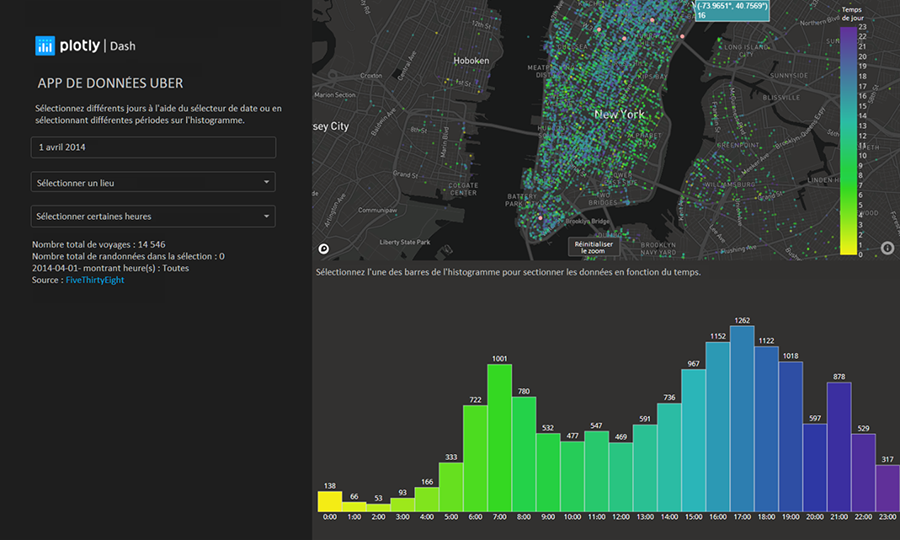
Description - Figure 8 :Trajets Uber
Voici un exemple d’une application du tableau de bord Plotly Dash. Elle permet de visualiser la répartition temporelle et spatiale des trajets Uber à Manhattan.
Description - Figure 9 : Carte des opioïdes
Voici un exemple d’une application du tableau de bord Plotly Dash. Elle visualise la répartition spatiale des décès attribuables à la toxicité des opioïdes aux États-Unis, selon le comté.
Description - Figure 10 : Nuage de points
Voici un exemple d’une application de visualisation 3D développée à l’aide de Plotly Dash. Cette application permet de visualiser les nuages de points 3D recueillis par un LIDAR dans une voiture.
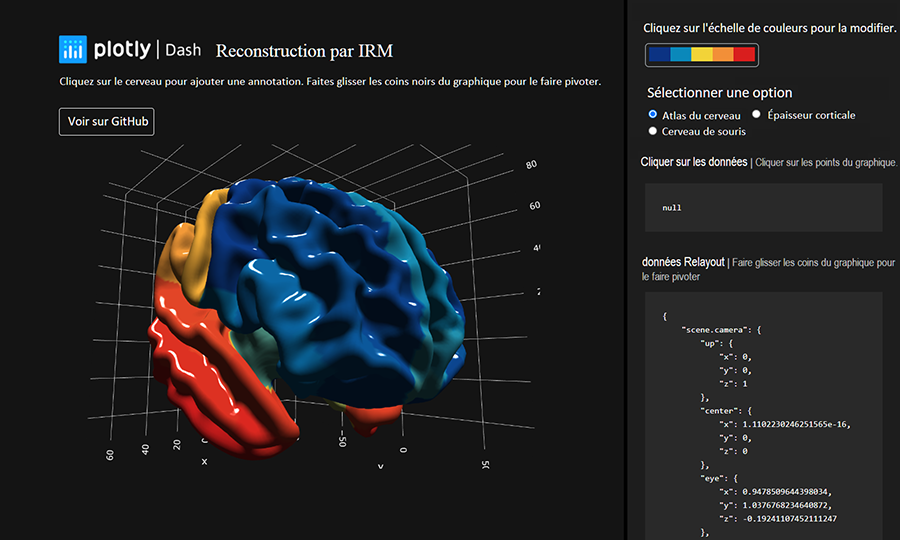
Description - Figure 11 : Maillage 3D
Voici un exemple d’une application de visualisation de maillages 3D développée à l’aide de Plotly Dash. Cette application permet de visualiser la reconstruction du cerveau à partir des données de l’IRM.
Une bonne interface utilisateur peut ajouter de la valeur aux projets en rendant les produits livrables plus présentables et utilisables. Pour les systèmes de production qui seront utilisés pendant longtemps, l'investissement préalable dans l'interface utilisateur peut se révéler rentable au fil du temps en réduisant la courbe d'apprentissage, en diminuant la confusion chez les utilisateurs et en améliorant leur productivité. Plotly Dash contribue à réduire considérablement le coût de conception d'interfaces utilisateurs pour les applications de données, ce qui peut augmenter le rendement sur l'investissement dans la conception de telles interfaces.
Rencontre avec le scientifique des données
Si vous avez des questions à propos de mon article ou si vous souhaitez en discuter davantage, je vous invite à une Rencontre avec le scientifique des données, un événement au cours duquel les auteurs rencontrent les lecteurs, présentent leur sujet et discutent de leurs résultats.
Jeudi, le 15 juin
De 13 00 h à 16 00 h, HE
MS Teams – le lien sera fourni aux participants par courriel
Description : En chiffres : Le Mois de l'histoire des Noirs 2023
Population
Selon le Recensement de la population de 2021, 7 013 835 personnes au Canada avoir des origines asiatiques, ce qui représente 19,3 % de la population canadienne.
Langue maternelle
En 2021, les quatre langues maternelles les plus souvent déclarées, après l’anglais et le français, étaient le pendjabi (panjabi), le mandarin, l’arabe et le yue (cantonais).
Emploi
En 2021, parmi les Canadiens et Canadiennes d’origine asiatique, les taux d’emploi les plus élevés ont été observés chez les personnes philippines (70,1 %), suivies par les personnes sud-asiatiques (62,3 %) et les personnes asiatiques du Sud-Est (56,7 %).
Immigration
Pendant des décennies, l’Asie (y compris le Moyen-Orient) a été la région d’origine de la plus grande part des immigrants récents. Cette proportion a augmenté, et les immigrants nés en Asie ont représenté un niveau record de 62,0 % des immigrants récents admis de 2016 à 2021.
Source : Statistique Canada. Recensement de la population, 2021.
Comité organisateur – première rangée, de gauche à droite: Apiraami Pathmalingam, Eleanor Melanson, Eric Neudorf, Sarah-Maude Bossé, Marina Smailes. Deuxième rangée, from de gauche à droite: Pippa O'Brien, Jasper Hui, Raphaël Duteau, Julien Lambert, Heidi Boles, Daanish Garda, Philippe Boudreault, Arthur Quang, Jason Blackwell, Olivier Godard. Missing: Phanie Boudreault, Amanda Azzi and Bala Vasudevan.
La cérémonie d'ouverture
La cérémonie d'ouverture
Séance de remue-méninges
Une équipe qui travaille
Une équipe le matin de l'événement
Séance de remue-méninges
Une équipe qui travaille
Atelier - Introduction à R et Python (Manolo Malaver-Vojvodic)
Avec la publication d'Une chance pour tous – La Première stratégie canadienne de réduction de la pauvreté, par le gouvernement du Canada, la mesure du panier de consommation (MPC) a été établie comme seuil de pauvreté officiel du Canada. Selon la MPC, une famille vit dans la pauvreté si elle ne dispose pas d'un revenu suffisant pour acheter un panier de biens et de services spécifique à sa communauté. Dans cette courte vidéo, vous apprendrez comment le panier de la MPC est construit et comparé au revenu disponible d'une famille pour calculer les statistiques sur la pauvreté au Canada.
La discrimination ou le traitement injuste est le fait de traiter des personnes différemment, négativement ou défavorablement en raison de leur race, de leur âge, de leur langue, de leur religion, de leur genre et d'autres caractéristiques. Selon des données tirées de l'Enquête sociale générale sur l'identité sociale de 2020, 54 % des personnes d'origine chinoise âgées de 15 ans et plus ont déclaré avoir été victimes de discrimination au cours des cinq années ayant précédé la pandémie de COVID-19, tandis que 52 % des personnes d'origine philippine et 47 % des personnes d'origine sud-asiatique ont déclaré avoir été victimes de discrimination
Les personnes d'origine asiatique du Sud-Est (58 %) étaient les plus susceptibles de subir de la discrimination dans un magasin, une banque ou un restaurant cinq ans avant la pandémie de COVID-19, suivies des personnes d'origine chinoise (53 %), sud-asiatique (50 %) et philippine (49 %)
Au cours des cinq années ayant précédé la pandémie de COVID-19, 52 % des personnes sud-asiatiques ont déclaré avoir été victimes de discrimination au travail ou au moment de présenter une demande d'emploi ou d'avancement; il s'agit de la part la plus élevée chez les personnes ayant un patrimoine asiatique. Parmi les femmes sud-asiatiques, 61 % ont été victimes de ce type de discrimination, alors que le pourcentage chez les hommes est de 43 %. En ce qui concerne les personnes arabes, 45 % d'entre elles ont été victimes de discrimination. À titre de comparaison, environ 41 % des personnes d'origine philippine et 31 % des personnes d'origine chinoise ont déclaré avoir été victimes de discrimination au travail ou au moment de présenter une demande d'emploi ou d'avancement, mais il n'y avait pas de différence entre les genres
Environ 31 % des personnes d'origine philippine ont déclaré avoir été victimes de discrimination à l'école ou en suivant des cours par rapport à 27 % des personnes d'origine asiatique du Sud-Est, à 24 % des personnes d'origine chinoise et à 21 % des personnes d'origine arabe
Approximativement 39 % des personnes d'origine philippine ont déclaré avoir été victimes de discrimination en raison de leur race ou de la couleur de leur peau, et 30 % en raison de leur appartenance ethnique ou culturelle. En ce qui concerne les personnes d'origine sud-asiatique, 35 % d'entre elles ont déclaré avoir été victimes de discrimination en raison de leur race ou de la couleur de leur peau, et 34 % en raison de leur appartenance ethnique ou culturelle
Les personnes arabes étaient les plus susceptibles de déclarer avoir été victimes de discrimination en raison de la religion (21 %); cette proportion était de 25 % chez les femmes et de 17 % chez les hommes. Environ 18 % des personnes sud-asiatiques ont été victimes de discrimination fondée sur la religion et il y avait une légère différence entre les femmes sud-asiatiques (18 %) et les hommes sud-asiatiques (17 %)
Au Canada, de nombreux groupes de population asiatiques affichent des niveaux de scolarité élevés, mais l'on observe des variations considérables. Parmi les personnes âgées de 25 à 64 ans, 6 personnes coréennes sur 10 sont titulaires d'un baccalauréat ou d'un grade supérieur, tout comme plus de la moitié des personnes chinoises, sud-asiatiques et asiatiques occidentales et comme plus de 4 personnes sur 10 des populations arabes, japonaises et philippines
La part des personnes asiatiques détenant un baccalauréat ou un grade supérieur est inférieure à la moyenne nationale (33 %) uniquement au sein de la population asiatique du Sud-Est (30 %) Cela s'explique par le fait que beaucoup de personnes de ce groupe sont arrivées au Canada en tant que réfugiées après avoir fui le Vietnam en 1979 et dans les années 1980, puis comme immigrantes de la catégorie du regroupement familial au cours des années suivantes. La population asiatique du Sud-Est de deuxième génération (c'est-à-dire les personnes nées au Canada qui ont au moins un parent né à l'extérieur du pays) affiche des niveaux de scolarité plus élevés; 44 % des personnes de ce groupe sont titulaires d'un baccalauréat ou grade supérieur
Le lieu d'études varie également au sein des populations asiatiques du Canada. Chez les personnes asiatiques canadiennes de première génération (c'est-à-dire les personnes nées à l'extérieur du Canada) qui sont titulaires d'un baccalauréat ou grade supérieur, la part de celles qui ont obtenu leur diplôme ailleurs qu'au Canada varie de 89 % pour les personnes philippines de première génération à 47 % pour les personnes chinoises de première génération
Les principaux domaines d'études varient de façon semblable dans les groupes de population asiatiques. Par exemple, 40 % des personnes asiatiques occidentales détenant un titre scolaire postsecondaire ont étudié dans de domaines STIM (science, technologie, ingénierie et mathématiques), ce qui représente deux fois la proportion observée dans l'ensemble de la population (20 %). Plus du quart (26 %) des personnes philippines ont étudié dans le domaine des soins de santé, ce qui représente aussi deux fois la proportion observée dans l'ensemble de la population (13 %). La part des personnes coréennes qui ont étudié en arts visuels et arts d'interprétation (10 %) est environ trois fois plus élevée que la proportion observée dans l'ensemble de la population (3 %)
Selon les données recueillies dans le cadre du Recensement de 2021, le taux d'emploi global était de 57,1 %. Au sein des populations asiatiques du Canada, les taux d'emploi les plus élevés ont été observés chez les personnes philippines (70,1 %), sud-asiatiques (62,3 %) et asiatiques du Sud-Est (56,7 %)
Les travailleurs des populations sud-asiatiques et chinoises étaient fortement représentés dans les emplois liés aux mathématiques, à l'informatique et aux sciences de l'information; ils représentaient respectivement 17,1 % et 11,4 % de tous les travailleurs dans ces domaines. À titre de comparaison, les travailleurs sud-asiatiques représentaient 7,4 % de tous les travailleurs et les travailleurs chinois, 4,5 %
En 2021, 6,2 % des navetteurs canadiens utilisaient un mode de transport actif — comme la marche et le vélo — pour se rendre au travail et 7,4 % d'entre eux faisaient du covoiturage avec un ou plusieurs travailleurs. Parmi les personnes asiatiques du Canada qui faisaient du navettage, 13,5 % des navetteurs japonais utilisaient un mode de transport actif et 12,8 % des navetteurs asiatiques du Sud-Est faisaient du covoiturage avec un ou plusieurs travailleurs
Un peu plus de la moitié de la population immigrante du Canada est née en Asie. En 2021, 51,5 % de tous les immigrants ont déclaré être nés en Asie (y compris le Moyen-Orient)
Depuis quelques décennies, l'Asie (y compris le Moyen-Orient) représente la région de naissance de la plus grande part des immigrants récents. Cette part a augmenté, les immigrants nés en Asie représentant un pourcentage record de 62,0 % des immigrants récents admis de 2016 à 2021
En 2021, 6 des 10 principaux pays de naissance des immigrants récents étaient des pays asiatiques : l'Inde, les Philippines, la Chine, la Syrie, le Pakistan et l'Iran
Selon les projections démographiques de Statistique Canada, les immigrants nés en Asie pourraient représenter de 59,2 % à 60,0 % de tous les immigrants d'ici 2041
En 2021, les quatre langues maternelles principales après l'anglais et le français étaient des langues parlées en Asie (y compris le Moyen-Orient) : le pendjabi (panjabi), le mandarin, l'arabe et le yue (cantonais). Chacune d'entre elles était la langue maternelle de plus de 600 000 personnes au Canada
Le nombre de Canadiens qui parlaient une langue sud-asiatique comme le gujarati, le pendjabi, l'hindi ou le malayalam de façon prédominante à la maison a augmenté considérablement de 2016 à 2021 en raison de l'immigration. En fait, le taux de croissance de la population qui parlait l'une de ces langues était au moins huit fois plus élevé que celui de l'ensemble de la population canadienne au cours de cette période
Les immigrants asiatiques issus de chacune des vagues d'immigration au Canada, de même que leurs descendants nés au pays, ont contribué à la diversité ethnoculturelle de la population canadienne
En 2021, 7 013 835 de personnes au Canada ont déclaré avoir des origines asiatiques, ce qui représente 19,3 % de la population du pays
Dans l'ensemble de la population canadienne, trois origines asiatiques comptent parmi les vingt origines les plus fréquemment déclarées, soit les origines chinoises (environ 1,7 million de personnes), les origines indiennes de l'Inde (environ 1,3 million de personnes) et les origines philippines (925 490 personnes)
La population racisée se compose de plusieurs groupes qui sont eux-mêmes diversifiés à de nombreux égards (p. ex. par rapport au lieu de naissance, aux origines ethniques ou culturelles, à la langue et à la religion)
En 2021, les populations sud-asiatiques et chinoises représentaient les deux plus grands groupes racisés au Canada, chacune comptant plus de 1,5 million de personnes. La population philippine, qui comptait près de 1 million de personnes, était le quatrième groupe racisé en importance
Selon les projections démographiques de Statistique Canada, en 2041, la population sud-asiatique pourrait surpasser les 5 millions de personnes, la population chinoise, les 3 millions de personnes et la population philippine, les 2 millions de personnes
Cette vidéo en langue des signes québécoise se veut une introduction à l'Enquête sur les modes d’apprentissage et de garde des jeunes enfants - Les enfants ayant un problème de santé de longue durée ou une incapacité. Elle présente une brève description de ce que la participation exige, des avantages de participer à l'enquête, et des renseignements sur la protection des renseignements personnels et sur la confidentialité.
Quand : Du 20 au 21 octobre 2018 - 24 heures intensives de résolution de problèmes Organisé par : Statistique Canada en collaboration avec l'Université d'Ottawa Où : Université d'Ottawa au Carrefour des apprentissages situé au 100 Louis-Pasteur Ouvert à : Tous les étudiants postsecondaires de 18 ans et plus au Canada Coût : Gratuit
Quand : Du 18 au 19 janvier 2020 - 24 heures intensives de résolution de problèmes Organisé par : Statistique Canada en collaboration avec l'Université d'Ottawa Où : Université d'Ottawa au Carrefour des apprentissages situé au 100 Louis-Pasteur Ouvert à : Tous les étudiants postsecondaires de 18 ans et plus au Canada Coût : Gratuit